
अ Hindi
Transcription Questions in Hindi
Class 12 Biology · Molecular Basis of Inheritance · Transcription
277+
Questions
Hindi
Language
100%
With Solutions
Showing 50 of 277 questions in Hindi
101
DifficultMCQ
$AGGTATCGCAT$ एक जीन की कोडिंग स्ट्रैंड का एक अनुक्रम है। तो इससे बनने वाले $mRNA$ का संबंधित अनुक्रम क्या होगा?
A
$AGGUAUCGCAU$
B
$UCCAUAGCGUA$
C
$ACCUAUGCGAU$
D
$UGGTUTCGCAT$
Solution
(A) जीन की कोडिंग स्ट्रैंड का अनुक्रम $mRNA$ के समान ही होता है,सिवाय इसके कि $DNA$ में मौजूद $Thymine$ $(T)$ को $RNA$ में $Uracil$ $(U)$ द्वारा प्रतिस्थापित किया जाता है।
दी गई कोडिंग स्ट्रैंड का अनुक्रम: $AGGTATCGCAT$ है।
$T$ को $U$ से बदलने पर $mRNA$ का अनुक्रम प्राप्त होता है: $AGGUAUCGCAU$।
अतः,सही विकल्प $A$ है।
दी गई कोडिंग स्ट्रैंड का अनुक्रम: $AGGTATCGCAT$ है।
$T$ को $U$ से बदलने पर $mRNA$ का अनुक्रम प्राप्त होता है: $AGGUAUCGCAU$।
अतः,सही विकल्प $A$ है।
0 likes
View Solution102
EasyMCQ
यूकेरियोटिक प्रमोटर का $TATA$ बॉक्स कहाँ स्थित होता है?
A
ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $25$ $bp$ ऊपर की ओर (upstream)।
B
ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $50$ $bp$ ऊपर की ओर (upstream)।
C
ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $75$ $bp$ ऊपर की ओर (upstream)।
D
ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $200$ $bp$ ऊपर की ओर (upstream)।
Solution
(A) $TATA$ बॉक्स,जिसे $Goldberg-Hogness$ बॉक्स के रूप में भी जाना जाता है,यूकेरियोट्स और आर्किया के जीन के प्रमोटर क्षेत्र में पाई जाने वाली एक $DNA$ अनुक्रम है।
यह आमतौर पर ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $25$ बेस पेयर $(bp)$ ऊपर की ओर (upstream) स्थित होता है।
यह अनुक्रम ट्रांसक्रिप्शन कारकों और $RNA$ पॉलीमरेज़ $II$ के लिए बाइंडिंग साइट के रूप में कार्य करता है और ट्रांसक्रिप्शन की शुरुआत में महत्वपूर्ण भूमिका निभाता है।
यह आमतौर पर ट्रांसक्रिप्शन शुरू होने वाले स्थान से लगभग $25$ बेस पेयर $(bp)$ ऊपर की ओर (upstream) स्थित होता है।
यह अनुक्रम ट्रांसक्रिप्शन कारकों और $RNA$ पॉलीमरेज़ $II$ के लिए बाइंडिंग साइट के रूप में कार्य करता है और ट्रांसक्रिप्शन की शुरुआत में महत्वपूर्ण भूमिका निभाता है।
0 likes
View Solution103
MediumMCQ
$RNA$ संश्लेषण की दिशा और टेम्पलेट $DNA$ रज्जुक (strand) के पढ़ने की दिशा के संबंध में सही विकल्प चुनें:
A
$5'-3'$ और $3'-5'$
B
$3'-5'$ और $5'-3'$
C
$5'-3'$ और $5'-3'$
D
$3'-5'$ और $3'-5'$
Solution
(A) अनुलेखन (Transcription) की प्रक्रिया के दौरान,$RNA$ पॉलीमरेज़ एंजाइम $RNA$ का संश्लेषण $5'-3'$ दिशा में करता है।
इसका अर्थ है कि नई $RNA$ श्रृंखला $3'$ सिरे पर न्यूक्लियोटाइड्स जोड़कर बनाई जाती है।
इसे प्राप्त करने के लिए,$RNA$ पॉलीमरेज़ एंजाइम टेम्पलेट $DNA$ रज्जुक पर $3'-5'$ दिशा में आगे बढ़ता है।
अतः,$RNA$ संश्लेषण की दिशा $5'-3'$ है और टेम्पलेट $DNA$ रज्जुक को पढ़ने की दिशा $3'-5'$ है।
इसका अर्थ है कि नई $RNA$ श्रृंखला $3'$ सिरे पर न्यूक्लियोटाइड्स जोड़कर बनाई जाती है।
इसे प्राप्त करने के लिए,$RNA$ पॉलीमरेज़ एंजाइम टेम्पलेट $DNA$ रज्जुक पर $3'-5'$ दिशा में आगे बढ़ता है।
अतः,$RNA$ संश्लेषण की दिशा $5'-3'$ है और टेम्पलेट $DNA$ रज्जुक को पढ़ने की दिशा $3'-5'$ है।
0 likes
View Solution104
DifficultMCQ
$DNA$ के निम्नलिखित खंड द्वारा उत्पादित $mRNA$ का अनुक्रम क्या होगा?
$3' ATGCATGCATGCATG 5'$ टेम्पलेट रज्जुक
$5' TACGTACGTACGTAC 3'$ कोडिंग रज्जुक
$3' ATGCATGCATGCATG 5'$ टेम्पलेट रज्जुक
$5' TACGTACGTACGTAC 3'$ कोडिंग रज्जुक
A
$3' AUGCAUGCAUGCAUG 5'$
B
$5' UACGUACGUACGUAC 3'$
C
$3' UACGUACGUACGUAC 5'$
D
$5' AUGCAUGCAUGCAUG 3'$
Solution
(D) अनुलेखन (Transcription) की प्रक्रिया के दौरान,$mRNA$ का संश्लेषण $DNA$ के टेम्पलेट रज्जुक ($3' \rightarrow 5'$ दिशा) का उपयोग करके किया जाता है।
क्षार-युग्मन (Base-pairing) के नियमों के अनुसार,$A$ के साथ $U$,$T$ के साथ $A$,$G$ के साथ $C$,और $C$ के साथ $G$ जुड़ता है।
टेम्पलेट रज्जुक $3' ATGCATGCATGCATG 5'$ है।
क्षार-युग्मन के नियमों को लागू करने पर,पूरक $mRNA$ अनुक्रम $5' UACGUACGUACGUAC 3'$ प्राप्त होता है।
यह अनुक्रम कोडिंग रज्जुक के समान है,केवल $Thymine$ $(T)$ के स्थान पर $Uracil$ $(U)$ होता है।
क्षार-युग्मन (Base-pairing) के नियमों के अनुसार,$A$ के साथ $U$,$T$ के साथ $A$,$G$ के साथ $C$,और $C$ के साथ $G$ जुड़ता है।
टेम्पलेट रज्जुक $3' ATGCATGCATGCATG 5'$ है।
क्षार-युग्मन के नियमों को लागू करने पर,पूरक $mRNA$ अनुक्रम $5' UACGUACGUACGUAC 3'$ प्राप्त होता है।
यह अनुक्रम कोडिंग रज्जुक के समान है,केवल $Thymine$ $(T)$ के स्थान पर $Uracil$ $(U)$ होता है।
0 likes
View Solution105
DifficultMCQ
निम्नलिखित $RNA$ पॉलीमरेज़ एंजाइमों को उनके ट्रांसक्रिप्शन उत्पादों के साथ सुमेलित करें:
निम्नलिखित में से सही विकल्प चुनें:
| $(a) \; RNA$ पॉलीमरेज़ $I$ | $(i) \; tRNA$ |
| $(b) \; RNA$ पॉलीमरेज़ $II$ | $(ii) \; rRNA$ |
| $(c) \; RNA$ पॉलीमरेज़ $III$ | $(iii) \; hnRNA$ |
निम्नलिखित में से सही विकल्प चुनें:
A
$a-i, b-iii, c-ii$
B
$a-i, b-ii, c-iii$
C
$a-ii, b-iii, c-i$
D
$a-iii, b-ii, c-i$
Solution
(C) यूकेरियोट्स में, ट्रांसक्रिप्शन में शामिल $RNA$ पॉलीमरेज़ के तीन मुख्य प्रकार होते हैं:
$1$. $RNA$ पॉलीमरेज़ $I$ $rRNA$ ($28S, 18S,$ और $5.8S$) का ट्रांसक्रिप्शन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$ $mRNA$ के पूर्ववर्ती का ट्रांसक्रिप्शन करता है, जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ कहा जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$ $tRNA$, $5S$ $rRNA$ और $snRNA$ (स्मॉल न्यूक्लियर $RNA$) के ट्रांसक्रिप्शन के लिए जिम्मेदार होता है।
इनका मिलान करने पर:
$(a) \; RNA$ पॉलीमरेज़ $I$ $\rightarrow$ $(ii) \; rRNA$
$(b) \; RNA$ पॉलीमरेज़ $II$ $\rightarrow$ $(iii) \; hnRNA$
$(c) \; RNA$ पॉलीमरेज़ $III$ $\rightarrow$ $(i) \; tRNA$
अतः, सही मिलान $a-ii, b-iii, c-i$ है।
$1$. $RNA$ पॉलीमरेज़ $I$ $rRNA$ ($28S, 18S,$ और $5.8S$) का ट्रांसक्रिप्शन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$ $mRNA$ के पूर्ववर्ती का ट्रांसक्रिप्शन करता है, जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ कहा जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$ $tRNA$, $5S$ $rRNA$ और $snRNA$ (स्मॉल न्यूक्लियर $RNA$) के ट्रांसक्रिप्शन के लिए जिम्मेदार होता है।
इनका मिलान करने पर:
$(a) \; RNA$ पॉलीमरेज़ $I$ $\rightarrow$ $(ii) \; rRNA$
$(b) \; RNA$ पॉलीमरेज़ $II$ $\rightarrow$ $(iii) \; hnRNA$
$(c) \; RNA$ पॉलीमरेज़ $III$ $\rightarrow$ $(i) \; tRNA$
अतः, सही मिलान $a-ii, b-iii, c-i$ है।
0 likes
View Solution106
MediumMCQ
यूकेरियोट्स में अनुलेखन (transcription) की प्रक्रिया में,$RNA$ पॉलीमरेज़ $I$ किसका अनुलेखन करता है?
A
अतिरिक्त प्रसंस्करण,कैपिंग और टेलिंग के साथ $mRNA$
B
$tRNA, 5S rRNA$ और $snRNAs$
C
$rRNAs$ ($28S, 18S$ और $5.8S$)
D
$mRNA$ का पूर्ववर्ती $(hnRNA)$
Solution
(C) यूकेरियोट्स में अनुलेखन के लिए तीन प्रकार के $RNA$ पॉलीमरेज़ शामिल होते हैं:
$1$. $RNA$ पॉलीमरेज़ $I$ का कार्य $rRNAs$ ($28S, 18S$ और $5.8S$) का अनुलेखन करना है।
$2$. $RNA$ पॉलीमरेज़ $II$ का कार्य $mRNA$ के पूर्ववर्ती का अनुलेखन करना है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ कहा जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$ का कार्य $tRNA, 5S rRNA$ और $snRNAs$ (स्मॉल न्यूक्लियर $RNAs$) का अनुलेखन करना है।
$1$. $RNA$ पॉलीमरेज़ $I$ का कार्य $rRNAs$ ($28S, 18S$ और $5.8S$) का अनुलेखन करना है।
$2$. $RNA$ पॉलीमरेज़ $II$ का कार्य $mRNA$ के पूर्ववर्ती का अनुलेखन करना है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ कहा जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$ का कार्य $tRNA, 5S rRNA$ और $snRNAs$ (स्मॉल न्यूक्लियर $RNAs$) का अनुलेखन करना है।
0 likes
View Solution107
MediumMCQ
यूकेरियोट्स (सुकेन्द्रकी) में अनुलेखन (transcription) में कौन से प्रारंभिक और समापन कारक शामिल होते हैं?
A
क्रमशः $\alpha$ और $\sigma$
B
क्रमशः $\alpha$ और $\beta$
C
क्रमशः $\beta$ और $\gamma$
D
क्रमशः $\sigma$ और $\rho$
Solution
(D) प्रोकैरियोट्स (आद्यकेन्द्रकी) में,$RNA$ पॉलीमरेज़ एंजाइम को अनुलेखन की शुरुआत के लिए सिग्मा $(\sigma)$ कारक और अनुलेखन की समाप्ति के लिए रो $(\rho)$ कारक की आवश्यकता होती है।
हालाँकि,प्रश्न यूकेरियोट्स के बारे में पूछा गया है। यूकेरियोट्स में अनुलेखन अधिक जटिल होता है और इसमें तीन अलग-अलग $RNA$ पॉलीमरेज़ ($I$,$II$,और $III$) तथा विभिन्न अनुलेखन कारक (TFs) शामिल होते हैं,न कि साधारण सिग्मा या रो कारक।
दिए गए विकल्पों को देखते हुए,यह प्रश्न प्रोकैरियोटिक अनुलेखन प्रक्रिया का संदर्भ दे रहा है,क्योंकि ये विशिष्ट कारक ($\sigma$ और $\rho$) यूकेरियोट्स में प्राथमिक प्रारंभिक और समापन कारक नहीं हैं।
यदि प्रश्न प्रोकैरियोटिक अनुलेखन के कारकों की पहचान करना चाहता है,तो सही उत्तर $\sigma$ (प्रारंभ) और $\rho$ (समापन) है।
हालाँकि,प्रश्न यूकेरियोट्स के बारे में पूछा गया है। यूकेरियोट्स में अनुलेखन अधिक जटिल होता है और इसमें तीन अलग-अलग $RNA$ पॉलीमरेज़ ($I$,$II$,और $III$) तथा विभिन्न अनुलेखन कारक (TFs) शामिल होते हैं,न कि साधारण सिग्मा या रो कारक।
दिए गए विकल्पों को देखते हुए,यह प्रश्न प्रोकैरियोटिक अनुलेखन प्रक्रिया का संदर्भ दे रहा है,क्योंकि ये विशिष्ट कारक ($\sigma$ और $\rho$) यूकेरियोट्स में प्राथमिक प्रारंभिक और समापन कारक नहीं हैं।
यदि प्रश्न प्रोकैरियोटिक अनुलेखन के कारकों की पहचान करना चाहता है,तो सही उत्तर $\sigma$ (प्रारंभ) और $\rho$ (समापन) है।
0 likes
View Solution108
Medium
यदि एक ट्रांसक्रिप्शन यूनिट में कोडिंग स्ट्रैंड का अनुक्रम इस प्रकार लिखा गया है:
$5'-ATGCATGCATGCATGCATGCATGCATGC-3'$. तो $mRNA$ का अनुक्रम लिखिए।
$5'-ATGCATGCATGCATGCATGCATGCATGC-3'$. तो $mRNA$ का अनुक्रम लिखिए।
Solution
(N/A) $DNA$ की कोडिंग स्ट्रैंड का अनुक्रम $mRNA$ ट्रांसक्रिप्ट के समान ही होता है,बस अंतर यह है कि $DNA$ में मौजूद $Thymine$ $(T)$ के स्थान पर $RNA$ में $Uracil$ $(U)$ होता है।
दी गई कोडिंग स्ट्रैंड: $5'-ATGCATGCATGCATGCATGCATGCATGC-3'$.
$T$ को $U$ से बदलने पर,$mRNA$ का अनुक्रम होगा:
$5'-AUGCAUGCAUGCAUGCAUGCAUGCAUGC-3'$.
दी गई कोडिंग स्ट्रैंड: $5'-ATGCATGCATGCATGCATGCATGCATGC-3'$.
$T$ को $U$ से बदलने पर,$mRNA$ का अनुक्रम होगा:
$5'-AUGCAUGCAUGCAUGCAUGCAUGCAUGC-3'$.
0 likes
View Solution109
Easy
निम्नलिखित के कार्यों को समझाइए (एक या दो पंक्तियों में):
$(a)$ प्रमोटर (Promoter)
$(b)$ $tRNA$
$(c)$ एक्सॉन (Exons)
$(a)$ प्रमोटर (Promoter)
$(b)$ $tRNA$
$(c)$ एक्सॉन (Exons)
Solution
(N/A) प्रमोटर: प्रमोटर $DNA$ का वह क्षेत्र है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट के रूप में कार्य करके अनुलेखन (transcription) की प्रक्रिया को शुरू करने में मदद करता है।
$(b)$ $tRNA$: $tRNA$ (ट्रांसफर $RNA$) $mRNA$ पर मौजूद आनुवंशिक कोड को पढ़ता है और प्रोटीन संश्लेषण के दौरान राइबोसोम तक विशिष्ट अमीनो एसिड ले जाता है।
$(c)$ एक्सॉन: एक्सॉन सुकेंद्रकी (eukaryotes) जीवों में $DNA$ के कोडिंग अनुक्रम हैं जो प्रोटीन के लिए अनुलेखित (transcribe) होते हैं।
$(b)$ $tRNA$: $tRNA$ (ट्रांसफर $RNA$) $mRNA$ पर मौजूद आनुवंशिक कोड को पढ़ता है और प्रोटीन संश्लेषण के दौरान राइबोसोम तक विशिष्ट अमीनो एसिड ले जाता है।
$(c)$ एक्सॉन: एक्सॉन सुकेंद्रकी (eukaryotes) जीवों में $DNA$ के कोडिंग अनुक्रम हैं जो प्रोटीन के लिए अनुलेखित (transcribe) होते हैं।
0 likes
View Solution110
Medium
अनुलेखन (Transcription) का वर्णन कीजिए।
Solution
(N/A) अनुलेखन $DNA$ की एक रज्जुक (strand) से आनुवंशिक जानकारी को $RNA$ में कॉपी करने की प्रक्रिया है।
अनुलेखन की प्रक्रिया पूरकता के सिद्धांत द्वारा शासित होती है,सिवाय इसके कि एडेनोसिन अब थाइमिन के बजाय यूरेसिल के साथ क्षार युग्म बनाता है।
प्रतिकृति (Replication) के विपरीत,जिसमें एक जीव के संपूर्ण $DNA$ की नकल की जाती है,अनुलेखन में केवल $DNA$ का एक खंड और दो रज्जुक में से केवल एक ही रज्जुक को $RNA$ में कॉपी किया जाता है।
अनुलेखन के दौरान दोनों रज्जुक एक साथ कॉपी क्यों नहीं होते,इसके कारण:
$(i)$ यदि दोनों रज्जुक कॉपी किए जाते,तो वे अलग-अलग अनुक्रमों वाले $RNA$ अणुओं के लिए कोड करते (क्योंकि पूरक होने का अर्थ समान होना नहीं है)। परिणामस्वरूप,अलग-अलग अमीनो एसिड अनुक्रम वाले दो प्रोटीन बनेंगे,जिससे आनुवंशिक सूचना स्थानांतरण तंत्र बहुत अधिक जटिल हो जाएगा।
$(ii)$ एक साथ उत्पादित दो $RNA$ अणु एक-दूसरे के पूरक होंगे और इसलिए वे आपस में जुड़कर द्वि-रज्जुक $RNA$ बना लेंगे। यह $RNA$ को प्रोटीन में अनुवादित होने से रोकेगा।
अनुलेखन की प्रक्रिया पूरकता के सिद्धांत द्वारा शासित होती है,सिवाय इसके कि एडेनोसिन अब थाइमिन के बजाय यूरेसिल के साथ क्षार युग्म बनाता है।
प्रतिकृति (Replication) के विपरीत,जिसमें एक जीव के संपूर्ण $DNA$ की नकल की जाती है,अनुलेखन में केवल $DNA$ का एक खंड और दो रज्जुक में से केवल एक ही रज्जुक को $RNA$ में कॉपी किया जाता है।
अनुलेखन के दौरान दोनों रज्जुक एक साथ कॉपी क्यों नहीं होते,इसके कारण:
$(i)$ यदि दोनों रज्जुक कॉपी किए जाते,तो वे अलग-अलग अनुक्रमों वाले $RNA$ अणुओं के लिए कोड करते (क्योंकि पूरक होने का अर्थ समान होना नहीं है)। परिणामस्वरूप,अलग-अलग अमीनो एसिड अनुक्रम वाले दो प्रोटीन बनेंगे,जिससे आनुवंशिक सूचना स्थानांतरण तंत्र बहुत अधिक जटिल हो जाएगा।
$(ii)$ एक साथ उत्पादित दो $RNA$ अणु एक-दूसरे के पूरक होंगे और इसलिए वे आपस में जुड़कर द्वि-रज्जुक $RNA$ बना लेंगे। यह $RNA$ को प्रोटीन में अनुवादित होने से रोकेगा।
0 likes
View Solution111
Medium
अनुलेखन इकाई (Transcription unit) पर संक्षिप्त टिप्पणी लिखिए।
Solution
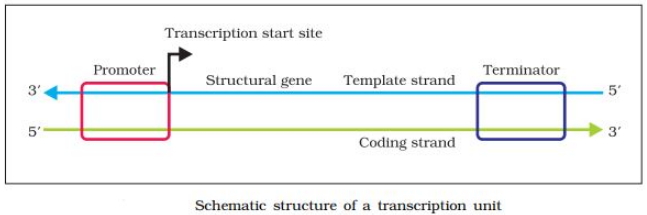
(N/A) $DNA$ में एक अनुलेखन इकाई मुख्य रूप से $DNA$ के तीन क्षेत्रों द्वारा परिभाषित होती है: $(i)$ एक प्रमोटर,$(ii)$ संरचनात्मक जीन,और $(iii)$ एक टर्मिनेटर।
अनुलेखन इकाई के संरचनात्मक जीन में $DNA$ की दो रज्जुक (strands) को परिभाषित करने के लिए एक परंपरा है।
चूंकि दोनों रज्जुक की ध्रुवता विपरीत होती है और $DNA$ पर निर्भर $RNA$ पॉलीमरेज केवल एक दिशा में यानी $5' \rightarrow 3'$ में बहुलकीकरण को उत्प्रेरित करता है,इसलिए जिस रज्जुक की ध्रुवता $3' \rightarrow 5'$ होती है,वह टेम्पलेट के रूप में कार्य करता है और इसे टेम्पलेट रज्जुक कहा जाता है।
दूसरा रज्जुक जिसकी ध्रुवता $5' \rightarrow 3'$ होती है और जिसका अनुक्रम $RNA$ के समान होता है (यूरेसिल के स्थान पर थाइमिन को छोड़कर),अनुलेखन के दौरान विस्थापित हो जाता है। अजीब बात यह है कि इस रज्जुक (जो किसी भी चीज़ के लिए कोड नहीं करता है) को कोडिंग रज्जुक कहा जाता है।
अनुलेखन इकाई को परिभाषित करते समय सभी संदर्भ बिंदु कोडिंग रज्जुक के संबंध में लिए जाते हैं।
$(i)$ प्रमोटर $DNA$ का वह अनुक्रम है जो $RNA$ पॉलीमरेज के लिए बाइंडिंग साइट प्रदान करता है। यह संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) पर स्थित होता है। अनुलेखन इकाई में प्रमोटर की उपस्थिति टेम्पलेट और कोडिंग रज्जुक को परिभाषित करती है। इसकी स्थिति को टर्मिनेटर के साथ बदलकर,कोडिंग और टेम्पलेट रज्जुक की परिभाषा को उलट दिया जा सकता है।
$(ii)$ अनुलेखन इकाई में संरचनात्मक जीन $DNA$ का वह खंड है जो प्रमोटर और टर्मिनेटर के बीच स्थित होता है।
$(iii)$ टर्मिनेटर कोडिंग रज्जुक के $3'$ सिरे (डाउनस्ट्रीम) की ओर स्थित होता है। यह आमतौर पर अनुलेखन प्रक्रिया के अंत को परिभाषित करता है। प्रमोटर के आगे अपस्ट्रीम या डाउनस्ट्रीम में अतिरिक्त नियामक अनुक्रम मौजूद हो सकते हैं।
अनुलेखन इकाई के संरचनात्मक जीन में $DNA$ की दो रज्जुक (strands) को परिभाषित करने के लिए एक परंपरा है।
चूंकि दोनों रज्जुक की ध्रुवता विपरीत होती है और $DNA$ पर निर्भर $RNA$ पॉलीमरेज केवल एक दिशा में यानी $5' \rightarrow 3'$ में बहुलकीकरण को उत्प्रेरित करता है,इसलिए जिस रज्जुक की ध्रुवता $3' \rightarrow 5'$ होती है,वह टेम्पलेट के रूप में कार्य करता है और इसे टेम्पलेट रज्जुक कहा जाता है।
दूसरा रज्जुक जिसकी ध्रुवता $5' \rightarrow 3'$ होती है और जिसका अनुक्रम $RNA$ के समान होता है (यूरेसिल के स्थान पर थाइमिन को छोड़कर),अनुलेखन के दौरान विस्थापित हो जाता है। अजीब बात यह है कि इस रज्जुक (जो किसी भी चीज़ के लिए कोड नहीं करता है) को कोडिंग रज्जुक कहा जाता है।
अनुलेखन इकाई को परिभाषित करते समय सभी संदर्भ बिंदु कोडिंग रज्जुक के संबंध में लिए जाते हैं।
$(i)$ प्रमोटर $DNA$ का वह अनुक्रम है जो $RNA$ पॉलीमरेज के लिए बाइंडिंग साइट प्रदान करता है। यह संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) पर स्थित होता है। अनुलेखन इकाई में प्रमोटर की उपस्थिति टेम्पलेट और कोडिंग रज्जुक को परिभाषित करती है। इसकी स्थिति को टर्मिनेटर के साथ बदलकर,कोडिंग और टेम्पलेट रज्जुक की परिभाषा को उलट दिया जा सकता है।
$(ii)$ अनुलेखन इकाई में संरचनात्मक जीन $DNA$ का वह खंड है जो प्रमोटर और टर्मिनेटर के बीच स्थित होता है।
$(iii)$ टर्मिनेटर कोडिंग रज्जुक के $3'$ सिरे (डाउनस्ट्रीम) की ओर स्थित होता है। यह आमतौर पर अनुलेखन प्रक्रिया के अंत को परिभाषित करता है। प्रमोटर के आगे अपस्ट्रीम या डाउनस्ट्रीम में अतिरिक्त नियामक अनुक्रम मौजूद हो सकते हैं।
0 likes
View Solution112
Medium
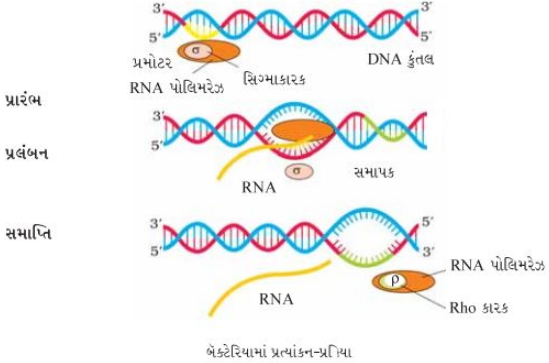
प्रोकैरियोट्स (बैक्टीरिया) में अनुलेखन (transcription) की प्रक्रिया का वर्णन कीजिए।
Solution
(N/A) बैक्टीरिया में तीन मुख्य प्रकार के $RNA$ होते हैं: $m-RNA$, $t-RNA$ और $r-RNA$। ये तीनों कोशिका में प्रोटीन संश्लेषण के लिए आवश्यक हैं।
$m-RNA$ एक टेम्पलेट के रूप में कार्य करता है, $t-RNA$ अमीनो एसिड को लाने और आनुवंशिक कोड को पढ़ने का काम करता है, जबकि $r-RNA$ अनुवाद के दौरान संरचनात्मक और उत्प्रेरक भूमिका निभाता है।
बैक्टीरिया में केवल एक ही $DNA$-निर्भर $RNA$ पॉलीमरेज़ होता है जो सभी प्रकार के $RNA$ के अनुलेखन को उत्प्रेरित करता है।
बैक्टीरिया में अनुलेखन की प्रक्रिया तीन चरणों में होती है: दीक्षा (initiation), दीर्घीकरण (elongation) और समापन (termination)।
$1$. दीक्षा: $RNA$ पॉलीमरेज़ दीक्षा कारक $(\sigma)$ की मदद से $DNA$ पर प्रमोटर के साथ जुड़ता है, जो अनुलेखन प्रक्रिया को शुरू करता है।
$2$. दीर्घीकरण: $RNA$ पॉलीमरेज़ न्यूक्लियोटाइड ट्राइफॉस्फेट का उपयोग सब्सट्रेट के रूप में करता है और टेम्पलेट स्ट्रैंड के अनुसार उनका बहुलकीकरण करता है। यह $DNA$ हेलिक्स को खोलने और $RNA$ श्रृंखला के दीर्घीकरण में मदद करता है।
$3$. समापन: जब $RNA$ पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँचता है, तो नव-निर्मित $RNA$ और $RNA$ पॉलीमरेज़ अलग हो जाते हैं। यह समापन कारक $(\rho)$ द्वारा सुगम होता है।
बैक्टीरिया में, चूंकि $mRNA$ को किसी प्रसंस्करण की आवश्यकता नहीं होती है और अनुलेखन तथा अनुवाद एक ही कोशिका द्रव्य में होते हैं, इसलिए $mRNA$ के पूरी तरह से अनुलेखित होने से पहले ही अनुवाद शुरू हो सकता है।
$m-RNA$ एक टेम्पलेट के रूप में कार्य करता है, $t-RNA$ अमीनो एसिड को लाने और आनुवंशिक कोड को पढ़ने का काम करता है, जबकि $r-RNA$ अनुवाद के दौरान संरचनात्मक और उत्प्रेरक भूमिका निभाता है।
बैक्टीरिया में केवल एक ही $DNA$-निर्भर $RNA$ पॉलीमरेज़ होता है जो सभी प्रकार के $RNA$ के अनुलेखन को उत्प्रेरित करता है।
बैक्टीरिया में अनुलेखन की प्रक्रिया तीन चरणों में होती है: दीक्षा (initiation), दीर्घीकरण (elongation) और समापन (termination)।
$1$. दीक्षा: $RNA$ पॉलीमरेज़ दीक्षा कारक $(\sigma)$ की मदद से $DNA$ पर प्रमोटर के साथ जुड़ता है, जो अनुलेखन प्रक्रिया को शुरू करता है।
$2$. दीर्घीकरण: $RNA$ पॉलीमरेज़ न्यूक्लियोटाइड ट्राइफॉस्फेट का उपयोग सब्सट्रेट के रूप में करता है और टेम्पलेट स्ट्रैंड के अनुसार उनका बहुलकीकरण करता है। यह $DNA$ हेलिक्स को खोलने और $RNA$ श्रृंखला के दीर्घीकरण में मदद करता है।
$3$. समापन: जब $RNA$ पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँचता है, तो नव-निर्मित $RNA$ और $RNA$ पॉलीमरेज़ अलग हो जाते हैं। यह समापन कारक $(\rho)$ द्वारा सुगम होता है।
बैक्टीरिया में, चूंकि $mRNA$ को किसी प्रसंस्करण की आवश्यकता नहीं होती है और अनुलेखन तथा अनुवाद एक ही कोशिका द्रव्य में होते हैं, इसलिए $mRNA$ के पूरी तरह से अनुलेखित होने से पहले ही अनुवाद शुरू हो सकता है।
0 likes
View Solution113
Difficult
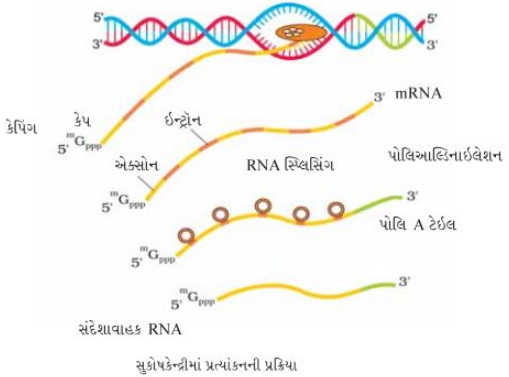
सुकेन्द्रकी (eukaryotes) में अनुलेखन (transcription) की प्रक्रिया का वर्णन कीजिए।
Solution
(N/A) सुकेन्द्रकी में अनुलेखन की प्रक्रिया जटिल होती है और इसमें निम्नलिखित चरण शामिल होते हैं:
$(i)$ केंद्रक में तीन प्रकार के $RNA$ पॉलीमरेज़ पाए जाते हैं। $RNA$ पॉलीमरेज़ $I$,$r-RNA$ ($28S, 18S$ और $5.8S$) का अनुलेखन करता है। $RNA$ पॉलीमरेज़ $III$,$t-RNA$,$5S$ $r-RNA$ और $sn-RNAs$ (स्मॉल न्यूक्लियर $RNAs$) के अनुलेखन के लिए जिम्मेदार है। $RNA$ पॉलीमरेज़ $II$,$m-RNA$ के पूर्ववर्ती रूप का अनुलेखन करता है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hn-RNA)$ कहा जाता है।
(ii) प्राथमिक प्रतिलेख में एक्सॉन और इंट्रॉन दोनों होते हैं और यह अक्रियाशील होता है। यह स्प्लिसिंग (splicing) नामक प्रक्रिया से गुजरता है,जिसमें इंट्रॉन को हटा दिया जाता है और एक्सॉन को एक निश्चित क्रम में जोड़ा जाता है। $hn-RNA$ कैपिंग (capping) और टेलिंग (tailing) प्रक्रिया से भी गुजरता है। कैपिंग में,एक असामान्य न्यूक्लियोटाइड,मिथाइल ग्वानोसिन ट्राइफॉस्फेट,$hn-RNA$ के $5'$ सिरे पर जोड़ा जाता है। टेलिंग में,$3'$ सिरे पर टेम्पलेट-स्वतंत्र तरीके से एडेनिलेट अवशेष $(200-300)$ जोड़े जाते हैं।
(iii) पूर्णतः संसाधित $hn-RNA$,जिसे अब $m-RNA$ कहा जाता है,अनुवाद (translation) के लिए केंद्रक से बाहर स्थानांतरित कर दिया जाता है।
$(i)$ केंद्रक में तीन प्रकार के $RNA$ पॉलीमरेज़ पाए जाते हैं। $RNA$ पॉलीमरेज़ $I$,$r-RNA$ ($28S, 18S$ और $5.8S$) का अनुलेखन करता है। $RNA$ पॉलीमरेज़ $III$,$t-RNA$,$5S$ $r-RNA$ और $sn-RNAs$ (स्मॉल न्यूक्लियर $RNAs$) के अनुलेखन के लिए जिम्मेदार है। $RNA$ पॉलीमरेज़ $II$,$m-RNA$ के पूर्ववर्ती रूप का अनुलेखन करता है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hn-RNA)$ कहा जाता है।
(ii) प्राथमिक प्रतिलेख में एक्सॉन और इंट्रॉन दोनों होते हैं और यह अक्रियाशील होता है। यह स्प्लिसिंग (splicing) नामक प्रक्रिया से गुजरता है,जिसमें इंट्रॉन को हटा दिया जाता है और एक्सॉन को एक निश्चित क्रम में जोड़ा जाता है। $hn-RNA$ कैपिंग (capping) और टेलिंग (tailing) प्रक्रिया से भी गुजरता है। कैपिंग में,एक असामान्य न्यूक्लियोटाइड,मिथाइल ग्वानोसिन ट्राइफॉस्फेट,$hn-RNA$ के $5'$ सिरे पर जोड़ा जाता है। टेलिंग में,$3'$ सिरे पर टेम्पलेट-स्वतंत्र तरीके से एडेनिलेट अवशेष $(200-300)$ जोड़े जाते हैं।
(iii) पूर्णतः संसाधित $hn-RNA$,जिसे अब $m-RNA$ कहा जाता है,अनुवाद (translation) के लिए केंद्रक से बाहर स्थानांतरित कर दिया जाता है।
0 likes
View Solution114
Medium
प्रोकैरियोट्स (आदिकेंद्रकी) और यूकेरियोट्स (सुकेंद्रकी) में अनुलेखन (Transcription) के बीच अंतर स्पष्ट कीजिए।
Solution
(N/A)
| प्रोकैरियोट्स में अनुलेखन | यूकेरियोट्स में अनुलेखन |
|---|---|
| $1$. अनुलेखन उत्पाद $\text{in situ}$ (उसी स्थान पर) कार्यात्मक होते हैं। | $1$. अनुलेखन उत्पादों को कार्यात्मक होने के लिए केंद्रक से बाहर कोशिका द्रव्य में जाना पड़ता है। |
| $2$. केवल एक ही प्रकार का $RNA$ पॉलीमरेज़ शामिल होता है। | $2$. तीन अलग-अलग प्रकार के $RNA$ पॉलीमरेज़ $(I, II, III)$ शामिल होते हैं। |
| $3$. $mRNA$ पॉलिसिस्ट्रोनिक होता है। | $3$. $mRNA$ मोनोसिस्ट्रोनिक होता है। |
| $4$. स्प्लिसिंग की आवश्यकता नहीं होती क्योंकि इसमें इंट्रॉन्स नहीं होते। | $4$. प्राथमिक प्रतिलेख से इंट्रॉन्स को हटाने के लिए स्प्लिसिंग आवश्यक है। |
0 likes
View Solution115
Medium
निम्नलिखित शब्दों को परिभाषित कीजिए: $Cistron$ (सिस्ट्रॉन) और $Terminator$ (टर्मिनेटर)।
Solution
(N/A) $Cistron$ (सिस्ट्रॉन): यह $DNA$ का एक खंड है जो एक विशिष्ट पॉलीपेप्टाइड श्रृंखला के लिए कूटलेखन (code) करता है। सुकेंद्रकी (eukaryotes) में यह आमतौर पर मोनोसिस्ट्रोनिक होता है,जबकि असीमकेंद्रकी (prokaryotes) में यह अक्सर पॉलीसिस्ट्रोनिक होता है।
$Terminator$ (टर्मिनेटर): यह $DNA$ का एक विशिष्ट अनुक्रम है जो अनुलेखन (transcription) के अंत का संकेत देता है। जब $RNA$ पॉलीमरेज़ एंजाइम इस क्षेत्र तक पहुँचता है,तो यह $RNA$ के संश्लेषण को रोक देता है और ट्रांसक्रिप्ट को मुक्त कर देता है।
$Terminator$ (टर्मिनेटर): यह $DNA$ का एक विशिष्ट अनुक्रम है जो अनुलेखन (transcription) के अंत का संकेत देता है। जब $RNA$ पॉलीमरेज़ एंजाइम इस क्षेत्र तक पहुँचता है,तो यह $RNA$ के संश्लेषण को रोक देता है और ट्रांसक्रिप्ट को मुक्त कर देता है।
0 likes
View Solution116
Medium
निम्नलिखित शब्दों की परिभाषा और व्याख्या कीजिए: एक्सॉन (Exons),इंट्रॉन (Introns),कैपिंग (Capping) और टेलिंग (Tailing)।
Solution
(N/A) एक्सॉन: ये कोडिंग अनुक्रम या अभिव्यक्त अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई देते हैं।
इंट्रॉन: ये मध्यवर्ती अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई नहीं देते हैं। वे केवल एक्सॉन के कोडिंग अनुक्रमों को बाधित करते हैं।
कैपिंग: इस प्रक्रिया में,$hnRNA$ के $5^{\prime}$-सिरे पर एक असामान्य न्यूक्लियोटाइड,$7$-मिथाइल ग्वानोसिन ट्राइफॉस्फेट जोड़ा जाता है।
टेलिंग: इस प्रक्रिया में,टेम्पलेट-स्वतंत्र तरीके से ट्रांसक्रिप्ट के $3^{\prime}$-सिरे पर एडेनाइलेट अवशेष $(200-300)$ जोड़े जाते हैं।
इंट्रॉन: ये मध्यवर्ती अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई नहीं देते हैं। वे केवल एक्सॉन के कोडिंग अनुक्रमों को बाधित करते हैं।
कैपिंग: इस प्रक्रिया में,$hnRNA$ के $5^{\prime}$-सिरे पर एक असामान्य न्यूक्लियोटाइड,$7$-मिथाइल ग्वानोसिन ट्राइफॉस्फेट जोड़ा जाता है।
टेलिंग: इस प्रक्रिया में,टेम्पलेट-स्वतंत्र तरीके से ट्रांसक्रिप्ट के $3^{\prime}$-सिरे पर एडेनाइलेट अवशेष $(200-300)$ जोड़े जाते हैं।
0 likes
View Solution117
Easy
नीचे एक ट्रांसक्रिप्शन यूनिट में $DNA$ की कोडिंग स्ट्रैंड का अनुक्रम दिया गया है: $5' - AATGCAGCTATTAGG - 3'$. $(a)$ इसकी पूरक स्ट्रैंड और $(b)$ $mRNA$ का अनुक्रम लिखिए।
Solution
(N/A) कोडिंग स्ट्रैंड $5' - AATGCAGCTATTAGG - 3'$ है। पूरक स्ट्रैंड (टेम्पलेट स्ट्रैंड) $3' - 5'$ दिशा में होती है और कोडिंग स्ट्रैंड के प्रतिसमांतर (antiparallel) होती है। अतः,पूरक स्ट्रैंड का अनुक्रम $3' - TTACGTCGATAATCC - 5'$ या $5' - CCTAATAGCTGCATT - 3'$ है।
$(b)$ $mRNA$ का अनुक्रम $DNA$ की कोडिंग स्ट्रैंड के समान होता है,सिवाय इसके कि $Thymine$ $(T)$ के स्थान पर $Uracil$ $(U)$ होता है। अतः,$mRNA$ का अनुक्रम $5' - AAUGCAGCUAUUAGG - 3'$ है।
$(b)$ $mRNA$ का अनुक्रम $DNA$ की कोडिंग स्ट्रैंड के समान होता है,सिवाय इसके कि $Thymine$ $(T)$ के स्थान पर $Uracil$ $(U)$ होता है। अतः,$mRNA$ का अनुक्रम $5' - AAUGCAGCUAUUAGG - 3'$ है।
0 likes
View Solution118
Medium
सिस्ट्रोन (cistron) को परिभाषित कीजिए। उदाहरण देते हुए मोनोसिस्ट्रोनिक और पॉलीसिस्ट्रोनिक ट्रांसक्रिप्शन इकाई के बीच अंतर स्पष्ट कीजिए।
Solution
(N/A) सिस्ट्रोन $DNA$ का वह खंड है जिसमें एक संपूर्ण पॉलीपेप्टाइड श्रृंखला या एक कार्यात्मक लक्षण के लिए आनुवंशिक जानकारी होती है।
$1.$ मोनोसिस्ट्रोनिक ट्रांसक्रिप्शन इकाई: इसमें एक एकल संरचनात्मक जीन होता है जो एक पॉलीपेप्टाइड के लिए कूटलेखन (coding) करता है। यह सुकेंद्रकी (eukaryotes) जीवों की विशेषता है। उदाहरण: मानव इंसुलिन या हीमोग्लोबिन के लिए जीन।
$2.$ पॉलीसिस्ट्रोनिक ट्रांसक्रिप्शन इकाई: इसमें एक ही प्रमोटर और टर्मिनेटर के नियंत्रण में कई संरचनात्मक जीन होते हैं,जो कई पॉलीपेप्टाइड्स के लिए कूटलेखन करते हैं। यह प्राककेंद्रकी (prokaryotes/bacteria) जीवों की विशेषता है। उदाहरण: $E. coli$ में $lac$ ओपेरॉन।
सुकेंद्रकी जीवों में,मोनोसिस्ट्रोनिक जीन अक्सर 'विभाजित' होते हैं,जिनमें इंट्रॉन्स नामक गैर-कोडिंग अनुक्रम होते हैं। जो कोडिंग अनुक्रम परिपक्व $RNA$ में दिखाई देते हैं,उन्हें एक्सॉन्स कहा जाता है।
$1.$ मोनोसिस्ट्रोनिक ट्रांसक्रिप्शन इकाई: इसमें एक एकल संरचनात्मक जीन होता है जो एक पॉलीपेप्टाइड के लिए कूटलेखन (coding) करता है। यह सुकेंद्रकी (eukaryotes) जीवों की विशेषता है। उदाहरण: मानव इंसुलिन या हीमोग्लोबिन के लिए जीन।
$2.$ पॉलीसिस्ट्रोनिक ट्रांसक्रिप्शन इकाई: इसमें एक ही प्रमोटर और टर्मिनेटर के नियंत्रण में कई संरचनात्मक जीन होते हैं,जो कई पॉलीपेप्टाइड्स के लिए कूटलेखन करते हैं। यह प्राककेंद्रकी (prokaryotes/bacteria) जीवों की विशेषता है। उदाहरण: $E. coli$ में $lac$ ओपेरॉन।
सुकेंद्रकी जीवों में,मोनोसिस्ट्रोनिक जीन अक्सर 'विभाजित' होते हैं,जिनमें इंट्रॉन्स नामक गैर-कोडिंग अनुक्रम होते हैं। जो कोडिंग अनुक्रम परिपक्व $RNA$ में दिखाई देते हैं,उन्हें एक्सॉन्स कहा जाता है।
0 likes
View Solution119
Medium
एक परिपक्व $mRNA$ में $(i)$ मिथाइलेटेड ग्वानोसिन कैप,$(ii)$ पॉली-$A$ टेल के क्या कार्य हैं?
Solution
(N/A) एक परिपक्व $mRNA$ में होने वाले संशोधनों के कार्य निम्नलिखित हैं:
$(i)$ मिथाइलेटेड ग्वानोसिन कैप: यह स्थानांतरण (translation) की शुरुआत के दौरान $mRNA$ को छोटे राइबोसोमल सब-यूनिट से जुड़ने में मदद करता है और एक्सोन्यूक्लीज द्वारा होने वाले क्षरण से $mRNA$ की रक्षा करता है।
$(ii)$ पॉली-$A$ टेल: यह $mRNA$ अणु को स्थिरता और दीर्घायु प्रदान करता है। पॉली-$A$ टेल की लंबाई और कोशिका द्रव्य में $mRNA$ के जीवनकाल के बीच सकारात्मक सहसंबंध (positive correlation) होता है।
$(i)$ मिथाइलेटेड ग्वानोसिन कैप: यह स्थानांतरण (translation) की शुरुआत के दौरान $mRNA$ को छोटे राइबोसोमल सब-यूनिट से जुड़ने में मदद करता है और एक्सोन्यूक्लीज द्वारा होने वाले क्षरण से $mRNA$ की रक्षा करता है।
$(ii)$ पॉली-$A$ टेल: यह $mRNA$ अणु को स्थिरता और दीर्घायु प्रदान करता है। पॉली-$A$ टेल की लंबाई और कोशिका द्रव्य में $mRNA$ के जीवनकाल के बीच सकारात्मक सहसंबंध (positive correlation) होता है।
0 likes
View Solution120
Medium
क्या आप मानते हैं कि एक्सॉन्स की वैकल्पिक स्प्लिसिंग (alternate splicing) एक संरचनात्मक जीन को एक ही जीन से कई आइसोप्रोटीन के लिए कोड करने में सक्षम बना सकती है? यदि हाँ,तो कैसे? यदि नहीं,तो क्यों?
Solution
(A) हाँ,एक्सॉन्स की वैकल्पिक स्प्लिसिंग एक एकल संरचनात्मक जीन को कई आइसोप्रोटीन के लिए कोड करने में सक्षम बनाती है।
संरचनात्मक जीनों के कार्यात्मक $mRNA$ में हमेशा उनके सभी एक्सॉन्स का शामिल होना आवश्यक नहीं है।
वैकल्पिक स्प्लिसिंग की यह प्रक्रिया विनियमित होती है और यह लिंग-विशिष्ट,ऊतक-विशिष्ट या विकासात्मक चरण-विशिष्ट हो सकती है।
$pre-mRNA$ के प्रसंस्करण के दौरान विशिष्ट एक्सॉन्स को पुनर्व्यवस्थित या हटाकर,एक ही जीन कई अलग-अलग आइसोप्रोटीन या समान वर्ग के प्रोटीन के लिए कोड कर सकता है।
ऐसी स्प्लिसिंग के अभाव में,जीव को प्रत्येक प्रोटीन या आइसोप्रोटीन के लिए एक अद्वितीय जीन की आवश्यकता होती,जो आनुवंशिक रूप से अक्षम होता।
इस प्रकार,वैकल्पिक स्प्लिसिंग जीनों की संख्या में आनुपातिक वृद्धि की आवश्यकता के बिना प्रोटीन विविधता को बढ़ाने की अनुमति देती है।
संरचनात्मक जीनों के कार्यात्मक $mRNA$ में हमेशा उनके सभी एक्सॉन्स का शामिल होना आवश्यक नहीं है।
वैकल्पिक स्प्लिसिंग की यह प्रक्रिया विनियमित होती है और यह लिंग-विशिष्ट,ऊतक-विशिष्ट या विकासात्मक चरण-विशिष्ट हो सकती है।
$pre-mRNA$ के प्रसंस्करण के दौरान विशिष्ट एक्सॉन्स को पुनर्व्यवस्थित या हटाकर,एक ही जीन कई अलग-अलग आइसोप्रोटीन या समान वर्ग के प्रोटीन के लिए कोड कर सकता है।
ऐसी स्प्लिसिंग के अभाव में,जीव को प्रत्येक प्रोटीन या आइसोप्रोटीन के लिए एक अद्वितीय जीन की आवश्यकता होती,जो आनुवंशिक रूप से अक्षम होता।
इस प्रकार,वैकल्पिक स्प्लिसिंग जीनों की संख्या में आनुपातिक वृद्धि की आवश्यकता के बिना प्रोटीन विविधता को बढ़ाने की अनुमति देती है।
0 likes
View Solution121
Difficult
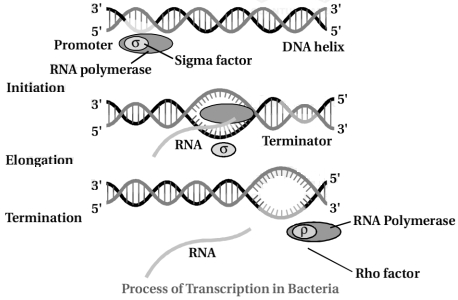
यूकेरियोटिक $mRNA$ के अनुलेखन-पश्चात संशोधनों (post-transcriptional modifications) का विवरण दीजिए।
Solution
(N/A) प्राथमिक ट्रांसक्रिप्ट्स $(hnRNA)$ में एक्सॉन और इंट्रॉन दोनों होते हैं और ये अक्रियाशील होते हैं। इसलिए,ये 'स्प्लिसिंग' (splicing) नामक प्रक्रिया से गुजरते हैं,जिसमें इंट्रॉन को हटा दिया जाता है और एक्सॉन को एक निश्चित क्रम में जोड़ा जाता है।
इंट्रॉन जीन का वह हिस्सा है जिसे ट्रांसक्राइब तो किया जाता है लेकिन ट्रांसलेट नहीं किया जाता है।
प्रोकेरियोट्स में $hnRNA$ अनुपस्थित होता है,इसलिए स्प्लिसिंग की आवश्यकता नहीं होती है।
$hnRNA$ अतिरिक्त प्रसंस्करण से गुजरता है जिसे 'कैपिंग' (capping) और 'टेलिंग' (tailing) कहा जाता है।
कैपिंग में,$hnRNA$ के $5^{\prime}$-सिरे पर एक असामान्य न्यूक्लियोटाइड (मिथाइल ग्वानोसिन ट्राइफॉस्फेट) जोड़ा जाता है।
टेलिंग में,$3^{\prime}$-सिरे पर टेम्पलेट-स्वतंत्र तरीके से एडेनाइलेट अवशेष $(200-300)$ जोड़े जाते हैं।
यह पूरी तरह से संसाधित $hnRNA$,जिसे अब $mRNA$ कहा जाता है,अनुवाद (translation) के लिए केंद्रक से बाहर ले जाया जाता है।
इंट्रॉन जीन का वह हिस्सा है जिसे ट्रांसक्राइब तो किया जाता है लेकिन ट्रांसलेट नहीं किया जाता है।
प्रोकेरियोट्स में $hnRNA$ अनुपस्थित होता है,इसलिए स्प्लिसिंग की आवश्यकता नहीं होती है।
$hnRNA$ अतिरिक्त प्रसंस्करण से गुजरता है जिसे 'कैपिंग' (capping) और 'टेलिंग' (tailing) कहा जाता है।
कैपिंग में,$hnRNA$ के $5^{\prime}$-सिरे पर एक असामान्य न्यूक्लियोटाइड (मिथाइल ग्वानोसिन ट्राइफॉस्फेट) जोड़ा जाता है।
टेलिंग में,$3^{\prime}$-सिरे पर टेम्पलेट-स्वतंत्र तरीके से एडेनाइलेट अवशेष $(200-300)$ जोड़े जाते हैं।
यह पूरी तरह से संसाधित $hnRNA$,जिसे अब $mRNA$ कहा जाता है,अनुवाद (translation) के लिए केंद्रक से बाहर ले जाया जाता है।
0 likes
View Solution122
EasyMCQ
अनुलेखन (transcription) के दौरान $DNA$ हेलिक्स को खोलने में सहायता करने वाले एंजाइम का नाम बताइए।
A
$RNA$ पॉलीमरेज़
B
$DNA$ लाइगेज़
C
$DNA$ हेलिकेज़
D
$DNA$ पॉलीमरेज़
Solution
(A) अनुलेखन (transcription) की प्रक्रिया के दौरान,$RNA$ पॉलीमरेज़ एंजाइम $DNA$ के दोहरे हेलिक्स को खोलने और $RNA$ स्ट्रैंड के संश्लेषण के लिए जिम्मेदार होता है। प्रतिकृति (replication) के विपरीत,जहाँ हेलिक्स को खोलने के लिए $DNA$ हेलिकेज़ का उपयोग किया जाता है,अनुलेखन में प्रमोटर साइट पर $DNA$ स्ट्रैंड्स को अलग करने की शुरुआत करने के लिए $RNA$ पॉलीमरेज़ होलोएंजाइम का उपयोग किया जाता है।
0 likes
View Solution123
MediumMCQ
अनुलेखन (Transcription) के दौरान $DNA$ कुंडली को खोलने में सहायता करने वाले एंजाइम का नाम पहचानें।
A
$DNA$ लाइगेज
B
$DNA$ हेलिकेज
C
$DNA$ पॉलीमरेज
D
$RNA$ पॉलीमरेज
Solution
(D) अनुलेखन की प्रक्रिया के दौरान,$RNA$ पॉलीमरेज एंजाइम $DNA$ कुंडली को खोलने के लिए जिम्मेदार होता है। $DNA$ प्रतिकृति (Replication) के विपरीत,जिसमें दोहरी कुंडली को खोलने के लिए एक अलग हेलिकेज एंजाइम की आवश्यकता होती है,$RNA$ पॉलीमरेज में $RNA$ का संश्लेषण करने के लिए टेम्पलेट के साथ आगे बढ़ते समय $DNA$ रज्जुक को खोलने की आंतरिक क्षमता होती है।
0 likes
View Solution124
Medium
अनुलेखन इकाई (Transcription unit) और जीन पर एक व्याख्यात्मक टिप्पणी लिखिए।
Solution
(N/A) जीन को वंशागति की कार्यात्मक इकाई के रूप में परिभाषित किया गया है। यद्यपि इसमें कोई संदेह नहीं है कि जीन $DNA$ पर स्थित होते हैं,लेकिन $DNA$ अनुक्रम के संदर्भ में जीन को शाब्दिक रूप से परिभाषित करना कठिन है।
$tRNA$ या $rRNA$ अणु के लिए कोडिंग करने वाला $DNA$ अनुक्रम भी एक जीन को परिभाषित करता है। हालाँकि,$cistron$ (सिस्ट्रॉन) को पॉलीपेप्टाइड के लिए कोडिंग करने वाले $DNA$ के एक खंड के रूप में परिभाषित करके,एक अनुलेखन इकाई में संरचनात्मक जीन को $monocistronic$ (मोनोसिस्ट्रोनिक - मुख्य रूप से यूकेरियोट्स में) या $polycistronic$ (पॉलीसिस्ट्रोनिक - मुख्य रूप से बैक्टीरिया या प्रोकैरियोट्स में) के रूप में वर्णित किया जा सकता है।
यूकेरियोट्स में,$monocistronic$ संरचनात्मक जीन में बाधित कोडिंग अनुक्रम होते हैं - यूकेरियोट्स में जीन विभाजित होते हैं। कोडिंग अनुक्रमों या अभिव्यक्त अनुक्रमों को $exons$ (एक्सॉन) के रूप में परिभाषित किया जाता है। $Exons$ वे अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई देते हैं। $Exons$ को $introns$ (इंट्रॉन) द्वारा बाधित किया जाता है। $Introns$ या मध्यवर्ती अनुक्रम परिपक्व या संसाधित $RNA$ में दिखाई नहीं देते हैं। विभाजित-जीन व्यवस्था $DNA$ खंड के संदर्भ में जीन की परिभाषा को और अधिक जटिल बनाती है।
किसी लक्षण की वंशागति संरचनात्मक जीन के प्रमोटर और नियामक अनुक्रमों से भी प्रभावित होती है। इसलिए,कभी-कभी नियामक अनुक्रमों को नियामक जीन के रूप में ढीले ढंग से परिभाषित किया जाता है,भले ही ये अनुक्रम किसी $RNA$ या प्रोटीन के लिए कोडिंग नहीं करते हों।
$tRNA$ या $rRNA$ अणु के लिए कोडिंग करने वाला $DNA$ अनुक्रम भी एक जीन को परिभाषित करता है। हालाँकि,$cistron$ (सिस्ट्रॉन) को पॉलीपेप्टाइड के लिए कोडिंग करने वाले $DNA$ के एक खंड के रूप में परिभाषित करके,एक अनुलेखन इकाई में संरचनात्मक जीन को $monocistronic$ (मोनोसिस्ट्रोनिक - मुख्य रूप से यूकेरियोट्स में) या $polycistronic$ (पॉलीसिस्ट्रोनिक - मुख्य रूप से बैक्टीरिया या प्रोकैरियोट्स में) के रूप में वर्णित किया जा सकता है।
यूकेरियोट्स में,$monocistronic$ संरचनात्मक जीन में बाधित कोडिंग अनुक्रम होते हैं - यूकेरियोट्स में जीन विभाजित होते हैं। कोडिंग अनुक्रमों या अभिव्यक्त अनुक्रमों को $exons$ (एक्सॉन) के रूप में परिभाषित किया जाता है। $Exons$ वे अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई देते हैं। $Exons$ को $introns$ (इंट्रॉन) द्वारा बाधित किया जाता है। $Introns$ या मध्यवर्ती अनुक्रम परिपक्व या संसाधित $RNA$ में दिखाई नहीं देते हैं। विभाजित-जीन व्यवस्था $DNA$ खंड के संदर्भ में जीन की परिभाषा को और अधिक जटिल बनाती है।
किसी लक्षण की वंशागति संरचनात्मक जीन के प्रमोटर और नियामक अनुक्रमों से भी प्रभावित होती है। इसलिए,कभी-कभी नियामक अनुक्रमों को नियामक जीन के रूप में ढीले ढंग से परिभाषित किया जाता है,भले ही ये अनुक्रम किसी $RNA$ या प्रोटीन के लिए कोडिंग नहीं करते हों।
0 likes
View Solution125
Medium
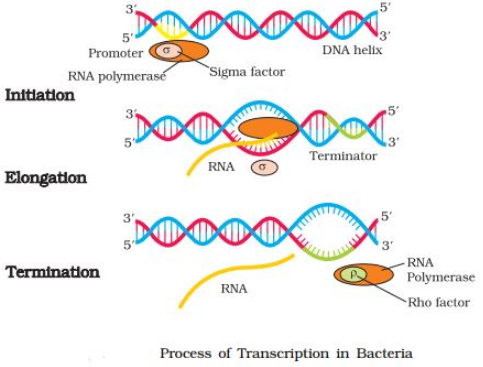
$RNA$ के विभिन्न प्रकारों को समझाइए और अनुलेखन (transcription) की प्रक्रिया की व्याख्या कीजिए।
Solution
(N/A) बैक्टीरिया में पाए जाने वाले $RNA$ के तीन मुख्य प्रकार निम्नलिखित हैं:
$(i)$ $mRNA$ (मैसेंजर $RNA$): यह स्थानांतरण (translation) के लिए टेम्पलेट प्रदान करता है।
$(ii)$ $tRNA$ (ट्रांसफर $RNA$): यह अमीनो एसिड लाता है और आनुवंशिक कोड को पढ़ता है।
$(iii)$ $rRNA$ (राइबोसोमल $RNA$): यह स्थानांतरण के दौरान संरचनात्मक और उत्प्रेरक भूमिका निभाता है।
कोशिका में प्रोटीन के संश्लेषण के लिए तीनों $RNA$ की आवश्यकता होती है।
बैक्टीरिया में सभी प्रकार के $RNA$ के अनुलेखन को उत्प्रेरित करने के लिए एक ही $DNA$ पर निर्भर $RNA$ पॉलीमरेज़ होता है।
बैक्टीरिया में अनुलेखन की प्रक्रिया तीन चरणों में होती है:
$1$. प्रारंभन (Initiation): $RNA$ पॉलीमरेज़ $DNA$ पर प्रमोटर क्षेत्र से जुड़ता है और अनुलेखन शुरू करता है। प्रक्रिया शुरू करने के लिए यह प्रारंभिक कारक $(\sigma)$ के साथ अस्थायी रूप से जुड़ता है।
$2$. दीर्घीकरण (Elongation): $RNA$ पॉलीमरेज़ न्यूक्लियोसाइड ट्राइफॉस्फेट का उपयोग सब्सट्रेट के रूप में करता है और पूरकता के नियम का पालन करते हुए टेम्पलेट-निर्भर तरीके से पॉलीमराइज़ेशन करता है। यह $DNA$ हेलिक्स को खोलने में मदद करता है और दीर्घीकरण जारी रखता है।
$3$. समापन (Termination): जैसे ही पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँचता है, नवजात $RNA$ और $RNA$ पॉलीमरेज़ दोनों अलग हो जाते हैं। अनुलेखन को समाप्त करने के लिए यह समापन कारक $(\rho)$ के साथ जुड़ता है। इन कारकों ($\sigma$ और $\rho$) के साथ जुड़ने से $RNA$ पॉलीमरेज़ की विशिष्टता बदल जाती है, जो प्रक्रिया को शुरू या समाप्त करने में मदद करती है।
$(i)$ $mRNA$ (मैसेंजर $RNA$): यह स्थानांतरण (translation) के लिए टेम्पलेट प्रदान करता है।
$(ii)$ $tRNA$ (ट्रांसफर $RNA$): यह अमीनो एसिड लाता है और आनुवंशिक कोड को पढ़ता है।
$(iii)$ $rRNA$ (राइबोसोमल $RNA$): यह स्थानांतरण के दौरान संरचनात्मक और उत्प्रेरक भूमिका निभाता है।
कोशिका में प्रोटीन के संश्लेषण के लिए तीनों $RNA$ की आवश्यकता होती है।
बैक्टीरिया में सभी प्रकार के $RNA$ के अनुलेखन को उत्प्रेरित करने के लिए एक ही $DNA$ पर निर्भर $RNA$ पॉलीमरेज़ होता है।
बैक्टीरिया में अनुलेखन की प्रक्रिया तीन चरणों में होती है:
$1$. प्रारंभन (Initiation): $RNA$ पॉलीमरेज़ $DNA$ पर प्रमोटर क्षेत्र से जुड़ता है और अनुलेखन शुरू करता है। प्रक्रिया शुरू करने के लिए यह प्रारंभिक कारक $(\sigma)$ के साथ अस्थायी रूप से जुड़ता है।
$2$. दीर्घीकरण (Elongation): $RNA$ पॉलीमरेज़ न्यूक्लियोसाइड ट्राइफॉस्फेट का उपयोग सब्सट्रेट के रूप में करता है और पूरकता के नियम का पालन करते हुए टेम्पलेट-निर्भर तरीके से पॉलीमराइज़ेशन करता है। यह $DNA$ हेलिक्स को खोलने में मदद करता है और दीर्घीकरण जारी रखता है।
$3$. समापन (Termination): जैसे ही पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँचता है, नवजात $RNA$ और $RNA$ पॉलीमरेज़ दोनों अलग हो जाते हैं। अनुलेखन को समाप्त करने के लिए यह समापन कारक $(\rho)$ के साथ जुड़ता है। इन कारकों ($\sigma$ और $\rho$) के साथ जुड़ने से $RNA$ पॉलीमरेज़ की विशिष्टता बदल जाती है, जो प्रक्रिया को शुरू या समाप्त करने में मदद करती है।
0 likes
View Solution126
Easy
वैज्ञानिक कारण दीजिए: अनुलेखन (Transcription) के दौरान $DNA$ की दोनों रज्जुक (strands) की प्रतिलिपि नहीं बनती है।
Solution
(N/A) यदि अनुलेखन के दौरान $DNA$ की दोनों रज्जुक की प्रतिलिपि बनती,तो दो अलग-अलग $RNA$ अणु उत्पन्न होते जो एक-दूसरे के पूरक होते।
ये दो पूरक $RNA$ अणु आपस में जुड़कर एक द्वि-रज्जुक $RNA$ $(dsRNA)$ अणु बना लेते।
यह $dsRNA$ स्थानांतरण (translation) की प्रक्रिया को रोक देता,क्योंकि राइबोसोम द्वि-रज्जुक संरचनाओं को पॉलीपेप्टाइड में स्थानांतरित नहीं कर सकते हैं।
इसके अतिरिक्त,यदि $DNA$ का एक खंड दो अलग-अलग पॉलीपेप्टाइड के लिए कूटलेखन (code) करता,तो आनुवंशिक सूचना तंत्र अत्यंत जटिल और अस्पष्ट हो जाता,जिससे प्रोटीन संश्लेषण में विरोधाभास उत्पन्न होता।
ये दो पूरक $RNA$ अणु आपस में जुड़कर एक द्वि-रज्जुक $RNA$ $(dsRNA)$ अणु बना लेते।
यह $dsRNA$ स्थानांतरण (translation) की प्रक्रिया को रोक देता,क्योंकि राइबोसोम द्वि-रज्जुक संरचनाओं को पॉलीपेप्टाइड में स्थानांतरित नहीं कर सकते हैं।
इसके अतिरिक्त,यदि $DNA$ का एक खंड दो अलग-अलग पॉलीपेप्टाइड के लिए कूटलेखन (code) करता,तो आनुवंशिक सूचना तंत्र अत्यंत जटिल और अस्पष्ट हो जाता,जिससे प्रोटीन संश्लेषण में विरोधाभास उत्पन्न होता।
0 likes
View Solution127
Easy
वैज्ञानिक कारण दीजिए: प्रोकैरियोटिक कोशिका में अनुलेखन (transcription) और स्थानांतरण (translation) एक साथ हो सकते हैं,लेकिन यूकैरियोटिक कोशिका में नहीं।
Solution
(N/A) प्रोकैरियोट्स में,संश्लेषित $mRNA$ को सक्रिय होने के लिए किसी प्रसंस्करण (processing) की आवश्यकता नहीं होती है और अनुलेखन तथा स्थानांतरण दोनों एक ही कोशिकाद्रव्य (cytosol) में होते हैं। इसके विपरीत,यूकेरियोट्स में,प्राथमिक ट्रांसक्रिप्ट में एक्सॉन और इंट्रॉन दोनों होते हैं और यह 'स्प्लिसिंग' नामक प्रक्रिया से गुजरता है,जहाँ इंट्रॉन को हटा दिया जाता है और एक्सॉन को एक निश्चित क्रम में जोड़कर परिपक्व $mRNA$ बनाया जाता है। इसके अलावा,यूकेरियोट्स में अनुलेखन केंद्रक में होता है,जबकि स्थानांतरण कोशिकाद्रव्य में होता है,जो इन दोनों प्रक्रियाओं के बीच एक भौतिक अलगाव पैदा करता है।
0 likes
View Solution128
Easy
परिभाषित करें/समझाएं: प्रमोटर और संरचनात्मक जीन (structural gene)।
Solution
(N/A) प्रमोटर एक $DNA$ अनुक्रम है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है। यह संरचनात्मक जीन के $5'$ सिरे पर स्थित होता है।
- ट्रांसक्रिप्शन इकाई में संरचनात्मक जीन $DNA$ का वह खंड है जो पॉलीपेप्टाइड या $RNA$ अणु के लिए कोड करता है और यह प्रमोटर और टर्मिनेटर के बीच स्थित होता है।
- ट्रांसक्रिप्शन इकाई में संरचनात्मक जीन $DNA$ का वह खंड है जो पॉलीपेप्टाइड या $RNA$ अणु के लिए कोड करता है और यह प्रमोटर और टर्मिनेटर के बीच स्थित होता है।
0 likes
View Solution129
MediumMCQ
अनुलेखन (Transcription) का अर्थ है.........
A
$DNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ प्रोटीन
B
$RNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ प्रोटीन
C
$RNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ $DNA$
D
$DNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ $RNA$
Solution
(D) अनुलेखन वह प्रक्रिया है जिसमें $DNA$ के एक रज्जुक (strand) से आनुवंशिक जानकारी को $RNA$ में कॉपी किया जाता है।
इस प्रक्रिया में,$DNA$ का केवल एक खंड और दो रज्जुक में से केवल एक रज्जुक ही $RNA$ में कॉपी होता है।
इसलिए,आनुवंशिक जानकारी का प्रवाह $DNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ $RNA$ के रूप में दर्शाया जाता है।
इस प्रक्रिया में,$DNA$ का केवल एक खंड और दो रज्जुक में से केवल एक रज्जुक ही $RNA$ में कॉपी होता है।
इसलिए,आनुवंशिक जानकारी का प्रवाह $DNA \rightarrow$ (आनुवंशिक जानकारी) $\rightarrow$ $RNA$ के रूप में दर्शाया जाता है।
0 likes
View Solution130
EasyMCQ
अनुलेखन (transcription) की प्रक्रिया किस सिद्धांत का पालन करती है?
A
उत्प्रेरक का सिद्धांत
B
पूरकता का सिद्धांत
C
चारगाफ का नियम
D
पुनरावृत्ति का सिद्धांत
Solution
(B) अनुलेखन की प्रक्रिया में $DNA$ टेम्पलेट से $RNA$ का संश्लेषण होता है। यह प्रक्रिया पूरकता के सिद्धांत (principle of complementarity) द्वारा संचालित होती है,जहाँ $RNA$ स्ट्रैंड के नाइट्रोजनस बेस $DNA$ टेम्पलेट स्ट्रैंड के पूरक होते हैं (उदाहरण के लिए,$Adenine$ का $Uracil$ के साथ और $Cytosine$ का $Guanine$ के साथ युग्मन)। अतः,सही उत्तर पूरकता का सिद्धांत है।
0 likes
View Solution131
MediumMCQ
अनुलेखन (transcription) की प्रक्रिया के लिए कौन सा कथन गलत है?
A
$DNA$ की दोनों रज्जुक (strands) $RNA$ में अनुलेखित होती हैं।
B
एडेनिन,यूरेसिल के साथ युग्म बनाता है।
C
$DNA$ से $RNA$ का संश्लेषण होता है।
D
$DNA$ की केवल एक रज्जुक टेम्पलेट के रूप में कार्य करती है।
Solution
(A) अनुलेखन की प्रक्रिया में,$DNA$ का केवल एक खंड और दो रज्जुक में से केवल एक रज्जुक ही $RNA$ में प्रतिलिपिबद्ध होता है।
यदि $DNA$ की दोनों रज्जुक टेम्पलेट के रूप में कार्य करतीं,तो वे अलग-अलग अनुक्रम वाले $RNA$ अणुओं के लिए कोड करतीं,और यदि वे प्रोटीन के लिए कोड करतीं,तो प्रोटीन में अमीनो एसिड का अनुक्रम अलग होता।
इसके अलावा,एक साथ उत्पन्न होने वाले दो $RNA$ अणु एक-दूसरे के पूरक होते,इसलिए वे द्वि-रज्जुक $RNA$ बनाते।
यह $RNA$ को प्रोटीन में अनुवादित होने से रोकता,जिससे अनुलेखन की प्रक्रिया व्यर्थ हो जाती।
इसलिए,यह कथन कि $DNA$ की दोनों रज्जुक $RNA$ में अनुलेखित होती हैं,गलत है।
यदि $DNA$ की दोनों रज्जुक टेम्पलेट के रूप में कार्य करतीं,तो वे अलग-अलग अनुक्रम वाले $RNA$ अणुओं के लिए कोड करतीं,और यदि वे प्रोटीन के लिए कोड करतीं,तो प्रोटीन में अमीनो एसिड का अनुक्रम अलग होता।
इसके अलावा,एक साथ उत्पन्न होने वाले दो $RNA$ अणु एक-दूसरे के पूरक होते,इसलिए वे द्वि-रज्जुक $RNA$ बनाते।
यह $RNA$ को प्रोटीन में अनुवादित होने से रोकता,जिससे अनुलेखन की प्रक्रिया व्यर्थ हो जाती।
इसलिए,यह कथन कि $DNA$ की दोनों रज्जुक $RNA$ में अनुलेखित होती हैं,गलत है।
0 likes
View Solution132
MediumMCQ
यदि $DNA$ की दोनों श्रृंखलाएँ अनुलेखन (transcription) के दौरान टेम्पलेट के रूप में कार्य करें,तो:
A
$RNA$ अणुओं के अलग-अलग अनुक्रम संश्लेषित होंगे।
B
दो $RNA$ अणु उत्पन्न होंगे,जो एक-दूसरे के पूरक होंगे।
C
द्वि-रज्जुक $RNA$ बनेगा,जो स्थानांतरण (translation) को रोक देगा।
D
उपरोक्त सभी।
Solution
(D) यदि $DNA$ की दोनों श्रृंखलाएँ अनुलेखन के दौरान टेम्पलेट के रूप में कार्य करती हैं,तो वे अलग-अलग अनुक्रम वाले दो $RNA$ अणुओं का निर्माण करेंगी। चूँकि $DNA$ की दोनों श्रृंखलाएँ एक-दूसरे की पूरक होती हैं,इसलिए उत्पन्न होने वाले $RNA$ अणु भी एक-दूसरे के पूरक होंगे। ये पूरक $RNA$ अणु आपस में जुड़कर द्वि-रज्जुक $RNA$ $(dsRNA)$ बना लेंगे। यह $dsRNA$ स्थानांतरण (translation) की प्रक्रिया को रोक देगा क्योंकि यह प्रोटीन संश्लेषण के लिए आवश्यक राइबोसोम के साथ नहीं जुड़ पाएगा। अतः,दिए गए सभी विकल्प सही हैं।
0 likes
View Solution133
EasyMCQ
अनुलेखन इकाई (Transcription unit) किसमें पाई जाती है?
A
$RNA$
B
$DNA$
C
प्रोटीन
D
लिपिड
Solution
(B) अनुलेखन इकाई $DNA$ का एक खंड है जिसे $RNA$ अणु में अनुलेखित किया जाता है। इसमें तीन मुख्य क्षेत्र होते हैं: प्रमोटर,संरचनात्मक जीन और टर्मिनेटर। इसलिए,अनुलेखन इकाई $DNA$ में पाई जाती है।
0 likes
View Solution134
MediumMCQ
अनुलेखन इकाई कितने भागों से बनी होती है?
A
$1$
B
$2$
C
$3$
D
$4$
Solution
(C) $DNA$ में एक अनुलेखन इकाई मुख्य रूप से $DNA$ के तीन क्षेत्रों द्वारा परिभाषित होती है:
$1$. प्रमोटर (Promoter)
$2$. संरचनात्मक जीन (Structural gene)
$3$. टर्मिनेटर (Terminator)
अतः,एक अनुलेखन इकाई $3$ भागों से बनी होती है।
$1$. प्रमोटर (Promoter)
$2$. संरचनात्मक जीन (Structural gene)
$3$. टर्मिनेटर (Terminator)
अतः,एक अनुलेखन इकाई $3$ भागों से बनी होती है।
0 likes
View Solution135
MediumMCQ
निम्नलिखित में से कौन सा भाग अनुलेखन इकाई (transcription unit) का हिस्सा नहीं है?
A
प्रमोटर
B
संरचनात्मक जीन
C
प्रतिकृतियन की उत्पत्ति (Origin of replication)
D
समापक (Terminator)
Solution
(C) $DNA$ में एक अनुलेखन इकाई मुख्य रूप से तीन क्षेत्रों द्वारा परिभाषित होती है:
$1$. प्रमोटर: वह स्थान जहाँ $RNA$ पॉलीमरेज़ अनुलेखन शुरू करने के लिए जुड़ता है।
$2$. संरचनात्मक जीन: $DNA$ का वह खंड जिसका $RNA$ में अनुलेखन होता है।
$3$. समापक (Terminator): वह स्थान जो अनुलेखन प्रक्रिया के अंत का संकेत देता है।
'प्रतिकृतियन की उत्पत्ति' $(ori)$ $DNA$ में एक विशिष्ट अनुक्रम है जहाँ प्रतिकृतियन (replication) शुरू होता है,जो $DNA$ प्रतिकृतियन की विशेषता है,अनुलेखन की नहीं।
$1$. प्रमोटर: वह स्थान जहाँ $RNA$ पॉलीमरेज़ अनुलेखन शुरू करने के लिए जुड़ता है।
$2$. संरचनात्मक जीन: $DNA$ का वह खंड जिसका $RNA$ में अनुलेखन होता है।
$3$. समापक (Terminator): वह स्थान जो अनुलेखन प्रक्रिया के अंत का संकेत देता है।
'प्रतिकृतियन की उत्पत्ति' $(ori)$ $DNA$ में एक विशिष्ट अनुक्रम है जहाँ प्रतिकृतियन (replication) शुरू होता है,जो $DNA$ प्रतिकृतियन की विशेषता है,अनुलेखन की नहीं।
0 likes
View Solution136
MediumMCQ
$RNA$ पॉलीमरेज़ किस दिशा में पॉलिमराइजेशन (बहुलीकरण) करता है?
A
$3' \rightarrow 5'$
B
$5' \rightarrow 3'$
C
$5' \rightarrow 5'$
D
$3' \rightarrow 3'$
Solution
(B) $RNA$ पॉलीमरेज़ $5' \rightarrow 3'$ दिशा में राइबोन्यूक्लियोटाइड्स का पॉलिमराइजेशन करता है।
इसका कारण यह है कि एंजाइम बढ़ती हुई $RNA$ श्रृंखला के $3'$-$OH$ समूह में नए न्यूक्लियोटाइड्स जोड़ता है।
$DNA$ की टेम्पलेट श्रृंखला को एंजाइम द्वारा $3' \rightarrow 5'$ दिशा में पढ़ा जाता है,जिसके परिणामस्वरूप $RNA$ श्रृंखला का संश्लेषण $5' \rightarrow 3'$ दिशा में होता है।
इसका कारण यह है कि एंजाइम बढ़ती हुई $RNA$ श्रृंखला के $3'$-$OH$ समूह में नए न्यूक्लियोटाइड्स जोड़ता है।
$DNA$ की टेम्पलेट श्रृंखला को एंजाइम द्वारा $3' \rightarrow 5'$ दिशा में पढ़ा जाता है,जिसके परिणामस्वरूप $RNA$ श्रृंखला का संश्लेषण $5' \rightarrow 3'$ दिशा में होता है।
0 likes
View Solution137
MediumMCQ
अनुलेखन इकाई में कौन सी रज्जुक (strands) क्रमशः टेम्पलेट रज्जुक और कोडिंग रज्जुक के रूप में कार्य करती हैं?
A
$3' \rightarrow 5', 5' \rightarrow 3'$
B
$5' \rightarrow 3', 3' \rightarrow 5'$
C
$3' \rightarrow 3', 5' \rightarrow 5'$
D
$5' \rightarrow 5', 3' \rightarrow 3'$
Solution
(A) अनुलेखन इकाई में,$DNA$ के द्विकुंडलित (double helix) में दो विपरीत ध्रुवता वाली रज्जुक होती हैं।
जो रज्जुक $3' \rightarrow 5'$ ध्रुवता रखती है,वह टेम्पलेट रज्जुक के रूप में कार्य करती है क्योंकि $RNA$ पॉलीमरेज़ एंजाइम इस रज्जुक का उपयोग करके $5' \rightarrow 3'$ दिशा में $RNA$ का संश्लेषण करता है।
दूसरी रज्जुक,जिसकी ध्रुवता $5' \rightarrow 3'$ होती है,उसे कोडिंग रज्जुक कहा जाता है क्योंकि इसका अनुक्रम उत्पादित $RNA$ के समान होता है (केवल थाइमिन के स्थान पर यूरेसिल होता है)।
अतः,टेम्पलेट रज्जुक $3' \rightarrow 5'$ है और कोडिंग रज्जुक $5' \rightarrow 3'$ है।
जो रज्जुक $3' \rightarrow 5'$ ध्रुवता रखती है,वह टेम्पलेट रज्जुक के रूप में कार्य करती है क्योंकि $RNA$ पॉलीमरेज़ एंजाइम इस रज्जुक का उपयोग करके $5' \rightarrow 3'$ दिशा में $RNA$ का संश्लेषण करता है।
दूसरी रज्जुक,जिसकी ध्रुवता $5' \rightarrow 3'$ होती है,उसे कोडिंग रज्जुक कहा जाता है क्योंकि इसका अनुक्रम उत्पादित $RNA$ के समान होता है (केवल थाइमिन के स्थान पर यूरेसिल होता है)।
अतः,टेम्पलेट रज्जुक $3' \rightarrow 5'$ है और कोडिंग रज्जुक $5' \rightarrow 3'$ है।
0 likes
View Solution138
MediumMCQ
यदि एक अनुलेखन इकाई में कोडिंग रज्जुक (coding strand) का अनुक्रम $GACTTAGCCA$ है,तो इस अनुलेखन इकाई से बनने वाले $RNA$ का अनुक्रम क्या होगा?
A
$CTGAATCGGT$
B
$CUGAAUCGGU$
C
$GACTTAGCCA$
D
$GACUUAGCCA$
Solution
(D) एक अनुलेखन इकाई में,कोडिंग रज्जुक का अनुक्रम $RNA$ अणु के समान ही होता है,केवल $DNA$ में उपस्थित $Thymine$ $(T)$ के स्थान पर $RNA$ में $Uracil$ $(U)$ होता है।
दिया गया कोडिंग रज्जुक अनुक्रम: $GACTTAGCCA$।
$T$ को $U$ से प्रतिस्थापित करने पर $RNA$ अनुक्रम प्राप्त होता है: $GACUUAGCCA$।
दिया गया कोडिंग रज्जुक अनुक्रम: $GACTTAGCCA$।
$T$ को $U$ से प्रतिस्थापित करने पर $RNA$ अनुक्रम प्राप्त होता है: $GACUUAGCCA$।
0 likes
View Solution139
EasyMCQ
$RNA$ पॉलीमरेज़ $DNA$ से कहाँ जुड़ता है?
A
समापक (Terminator)
B
संरचनात्मक जीन (Structural gene)
C
प्रमोटर (Promoter)
D
ऑपरेटर (Operator)
Solution
(C) अनुलेखन (Transcription) की प्रक्रिया में,$RNA$ पॉलीमरेज़ एंजाइम $DNA$ टेम्पलेट से $RNA$ के संश्लेषण के लिए जिम्मेदार होता है।
यह एंजाइम विशेष रूप से $DNA$ के उस अनुक्रम को पहचानता है और उससे जुड़ता है जिसे $Promoter$ क्षेत्र कहा जाता है।
$Promoter$ संरचनात्मक जीन के अपस्ट्रीम (upstream) स्थित होता है और यह अनुलेखन के लिए दीक्षा स्थल (initiation site) के रूप में कार्य करता है।
एक बार $Promoter$ से जुड़ने के बाद,$RNA$ पॉलीमरेज़ $DNA$ के द्विकुंडलित (double helix) को खोलकर $RNA$ श्रृंखला का संश्लेषण शुरू करता है।
यह एंजाइम विशेष रूप से $DNA$ के उस अनुक्रम को पहचानता है और उससे जुड़ता है जिसे $Promoter$ क्षेत्र कहा जाता है।
$Promoter$ संरचनात्मक जीन के अपस्ट्रीम (upstream) स्थित होता है और यह अनुलेखन के लिए दीक्षा स्थल (initiation site) के रूप में कार्य करता है।
एक बार $Promoter$ से जुड़ने के बाद,$RNA$ पॉलीमरेज़ $DNA$ के द्विकुंडलित (double helix) को खोलकर $RNA$ श्रृंखला का संश्लेषण शुरू करता है।
0 likes
View Solution140
MediumMCQ
एक संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) और $3'$ सिरे (डाउनस्ट्रीम) की ओर स्थित क्षेत्रों को क्रमशः क्या कहा जाता है?
A
समापक (Terminator) और प्रमोटर
B
प्रमोटर और समापक (Terminator)
C
समापक और नियामक
D
नियामक और प्रमोटर
Solution
(B) अनुलेखन इकाई में,संरचनात्मक जीन एक प्रमोटर और एक समापक (Terminator) के बीच स्थित होता है।
$1$. प्रमोटर संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) की ओर स्थित होता है।
$2$. समापक संरचनात्मक जीन के $3'$ सिरे (डाउनस्ट्रीम) की ओर स्थित होता है।
अतः,$5'$ सिरे के अपस्ट्रीम क्षेत्र को प्रमोटर और $3'$ सिरे के डाउनस्ट्रीम क्षेत्र को समापक कहा जाता है।
$1$. प्रमोटर संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) की ओर स्थित होता है।
$2$. समापक संरचनात्मक जीन के $3'$ सिरे (डाउनस्ट्रीम) की ओर स्थित होता है।
अतः,$5'$ सिरे के अपस्ट्रीम क्षेत्र को प्रमोटर और $3'$ सिरे के डाउनस्ट्रीम क्षेत्र को समापक कहा जाता है।
0 likes
View Solution141
MediumMCQ
टेम्पलेट और कोडिंग रज्जुक (strands) का निर्धारण किसकी उपस्थिति द्वारा होता है?
A
प्रमोटर
B
संरचनात्मक जीन
C
ऑपरेटर
D
समापक (Terminator)
Solution
(A) अनुलेखन (Transcription) की प्रक्रिया में,$DNA$ के द्विकुंडलित (double helix) में दो रज्जुक होते हैं। एक रज्जुक टेम्पलेट रज्जुक ($3'$ से $5'$ ध्रुवता) के रूप में और दूसरा कोडिंग रज्जुक ($5'$ से $3'$ ध्रुवता) के रूप में कार्य करता है।
टेम्पलेट रज्जुक की ध्रुवता प्रमोटर की स्थिति द्वारा निर्धारित होती है।
प्रमोटर संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) पर स्थित $DNA$ का एक अनुक्रम है।
यह $RNA$ पॉलीमरेज़ के लिए बंधन स्थल प्रदान करता है और यह निर्धारित करता है कि कौन सा रज्जुक अनुलेखन के लिए टेम्पलेट के रूप में कार्य करेगा।
टेम्पलेट रज्जुक की ध्रुवता प्रमोटर की स्थिति द्वारा निर्धारित होती है।
प्रमोटर संरचनात्मक जीन के $5'$ सिरे (अपस्ट्रीम) पर स्थित $DNA$ का एक अनुक्रम है।
यह $RNA$ पॉलीमरेज़ के लिए बंधन स्थल प्रदान करता है और यह निर्धारित करता है कि कौन सा रज्जुक अनुलेखन के लिए टेम्पलेट के रूप में कार्य करेगा।
0 likes
View Solution142
MediumMCQ
कोडिंग अनुक्रम (अभिव्यक्त अनुक्रम) के लिए उपयुक्त विकल्प चुनें।
A
इंट्रॉन
B
एक्सट्रॉन
C
हेक्सामर
D
एक्सॉन्स
Solution
(D) यूकेरियोटिक जीन अभिव्यक्ति में,प्राथमिक ट्रांसक्रिप्ट $(pre-mRNA)$ में कोडिंग और नॉन-कोडिंग दोनों अनुक्रम होते हैं।
$1$. वे कोडिंग अनुक्रम जो अंतिम परिपक्व $mRNA$ में व्यक्त होते हैं,उन्हें $Exons$ (एक्सॉन्स) के रूप में जाना जाता है।
$2$. वे नॉन-कोडिंग अनुक्रम जिन्हें $RNA$ स्प्लिसिंग के दौरान हटा दिया जाता है,उन्हें $Introns$ (इंट्रॉन) कहा जाता है।
$3$. इसलिए,अभिव्यक्त अनुक्रम के लिए सही शब्द $Exons$ है।
$1$. वे कोडिंग अनुक्रम जो अंतिम परिपक्व $mRNA$ में व्यक्त होते हैं,उन्हें $Exons$ (एक्सॉन्स) के रूप में जाना जाता है।
$2$. वे नॉन-कोडिंग अनुक्रम जिन्हें $RNA$ स्प्लिसिंग के दौरान हटा दिया जाता है,उन्हें $Introns$ (इंट्रॉन) कहा जाता है।
$3$. इसलिए,अभिव्यक्त अनुक्रम के लिए सही शब्द $Exons$ है।
0 likes
View Solution143
MediumMCQ
परिपक्व $RNA$ में क्या अनुपस्थित होता है?
A
इंटरफेरॉन
B
इंट्रॉन्स
C
इंटरल्यूकिन
D
एक्सॉन्स
Solution
(B) यूकेरियोटिक कोशिकाओं में,प्राथमिक ट्रांसक्रिप्ट (pre-$mRNA$) में कोडिंग अनुक्रम जिन्हें $Exons$ कहा जाता है और गैर-कोडिंग अनुक्रम जिन्हें $Introns$ कहा जाता है,दोनों मौजूद होते हैं।
ट्रांसक्रिप्शन के बाद के संशोधनों के दौरान,$Introns$ को स्प्लिसिंग (splicing) नामक प्रक्रिया के माध्यम से हटा दिया जाता है।
शेष $Exons$ को एक निश्चित क्रम में जोड़कर परिपक्व $mRNA$ बनाया जाता है।
इसलिए,परिपक्व $RNA$ में $Introns$ अनुपस्थित होते हैं।
ट्रांसक्रिप्शन के बाद के संशोधनों के दौरान,$Introns$ को स्प्लिसिंग (splicing) नामक प्रक्रिया के माध्यम से हटा दिया जाता है।
शेष $Exons$ को एक निश्चित क्रम में जोड़कर परिपक्व $mRNA$ बनाया जाता है।
इसलिए,परिपक्व $RNA$ में $Introns$ अनुपस्थित होते हैं।
0 likes
View Solution144
MediumMCQ
कौन से अनुक्रम $RNA$ या प्रोटीन के लिए कूटलेखन (coding) नहीं करते हैं?
A
प्रमोटर
B
समापक (Terminator)
C
नियामक अनुक्रम
D
उपरोक्त सभी
Solution
(D) अनुलेखन (transcription) की प्रक्रिया में,जीन को $DNA$ के उस अनुक्रम के रूप में परिभाषित किया जाता है जो $RNA$ या प्रोटीन अणुओं के लिए कूटलेखन करता है।
हालाँकि,संरचनात्मक जीन प्रमोटर और समापक अनुक्रमों से घिरा होता है।
- $Promoter$ एक $DNA$ अनुक्रम है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है और इसका $RNA$ में अनुलेखन नहीं होता है।
- $Terminator$ एक $DNA$ अनुक्रम है जो अनुलेखन के अंत का संकेत देता है और यह अंतिम $RNA$ उत्पाद का हिस्सा नहीं होता है।
- $Regulatory$ अनुक्रम $DNA$ के वे क्षेत्र हैं जो जीन की अभिव्यक्ति को नियंत्रित करते हैं लेकिन वे स्वयं $RNA$ या प्रोटीन के लिए कूटलेखन नहीं करते हैं।
इसलिए,ये सभी अनुक्रम (प्रमोटर,समापक और नियामक अनुक्रम) $RNA$ या प्रोटीन के लिए कूटलेखन नहीं करते हैं।
हालाँकि,संरचनात्मक जीन प्रमोटर और समापक अनुक्रमों से घिरा होता है।
- $Promoter$ एक $DNA$ अनुक्रम है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है और इसका $RNA$ में अनुलेखन नहीं होता है।
- $Terminator$ एक $DNA$ अनुक्रम है जो अनुलेखन के अंत का संकेत देता है और यह अंतिम $RNA$ उत्पाद का हिस्सा नहीं होता है।
- $Regulatory$ अनुक्रम $DNA$ के वे क्षेत्र हैं जो जीन की अभिव्यक्ति को नियंत्रित करते हैं लेकिन वे स्वयं $RNA$ या प्रोटीन के लिए कूटलेखन नहीं करते हैं।
इसलिए,ये सभी अनुक्रम (प्रमोटर,समापक और नियामक अनुक्रम) $RNA$ या प्रोटीन के लिए कूटलेखन नहीं करते हैं।
0 likes
View Solution145
MediumMCQ
अनुलेखन (Transcription) की प्रक्रिया के लिए मुख्य रूप से कौन सा एंजाइम आवश्यक है?
A
$RNA$-निर्भर $RNA$ पॉलीमरेज़
B
$RNA$-निर्भर $DNA$ पॉलीमरेज़
C
$DNA$-निर्भर $RNA$ पॉलीमरेज़
D
$DNA$-निर्भर $DNA$ पॉलीमरेज़
Solution
(C) अनुलेखन वह प्रक्रिया है जिसमें $DNA$ की एक रज्जुक (strand) से आनुवंशिक जानकारी को $RNA$ में कॉपी किया जाता है।
यह प्रक्रिया $DNA$-निर्भर $RNA$ पॉलीमरेज़ एंजाइम द्वारा उत्प्रेरित होती है।
यह एंजाइम पूरक $RNA$ रज्जुक के संश्लेषण के लिए $DNA$ को टेम्पलेट के रूप में उपयोग करता है।
अतः,सही विकल्प $C$ है।
यह प्रक्रिया $DNA$-निर्भर $RNA$ पॉलीमरेज़ एंजाइम द्वारा उत्प्रेरित होती है।
यह एंजाइम पूरक $RNA$ रज्जुक के संश्लेषण के लिए $DNA$ को टेम्पलेट के रूप में उपयोग करता है।
अतः,सही विकल्प $C$ है।
0 likes
View Solution146
EasyMCQ
निम्नलिखित में से कौन $RNA$ पॉलीमरेज़ एंजाइम के लिए सब्सट्रेट (प्रक्रियाधार) के रूप में कार्य करता है?
A
न्यूक्लियोसाइड
B
नाइट्रोजनस बेस
C
न्यूक्लियोसाइड मोनोफॉस्फेट
D
न्यूक्लियोसाइड ट्राइफॉस्फेट
Solution
(D) $RNA$ पॉलीमरेज़ वह एंजाइम है जो ट्रांसक्रिप्शन (अनुलेखन) के लिए जिम्मेदार है,जो $DNA$ टेम्पलेट से $RNA$ को संश्लेषित करने की प्रक्रिया है।
ट्रांसक्रिप्शन प्रक्रिया के दौरान,$RNA$ पॉलीमरेज़ एंजाइम सब्सट्रेट के रूप में राइबोन्यूक्लियोसाइड ट्राइफॉस्फेट $(NTPs)$ का उपयोग करता है।
ये $NTPs$ (जैसे $ATP$,$GTP$,$CTP$,और $UTP$) पॉलीमराइजेशन प्रतिक्रिया के लिए आवश्यक बिल्डिंग ब्लॉक्स (न्यूक्लियोटाइड्स) और उच्च-ऊर्जा फॉस्फेट बॉन्ड के हाइड्रोलिसिस के माध्यम से आवश्यक ऊर्जा दोनों प्रदान करते हैं।
ट्रांसक्रिप्शन प्रक्रिया के दौरान,$RNA$ पॉलीमरेज़ एंजाइम सब्सट्रेट के रूप में राइबोन्यूक्लियोसाइड ट्राइफॉस्फेट $(NTPs)$ का उपयोग करता है।
ये $NTPs$ (जैसे $ATP$,$GTP$,$CTP$,और $UTP$) पॉलीमराइजेशन प्रतिक्रिया के लिए आवश्यक बिल्डिंग ब्लॉक्स (न्यूक्लियोटाइड्स) और उच्च-ऊर्जा फॉस्फेट बॉन्ड के हाइड्रोलिसिस के माध्यम से आवश्यक ऊर्जा दोनों प्रदान करते हैं।
0 likes
View Solution147
MediumMCQ
प्रोकैरियोटिक $RNA$ पॉलीमरेज़ की प्रतिलेखन (transcription) की प्रक्रिया में मुख्य भूमिका क्या है?
A
प्रारंभन (Initiation)
B
दीर्घीकरण (Elongation)
C
समापन (Termination)
D
उपरोक्त सभी
Solution
(D) प्रोकैरियोट्स में, एक ही प्रकार का $RNA$ पॉलीमरेज़ सभी प्रकार के $RNA$ ($mRNA$, $tRNA$, और $rRNA$) के प्रतिलेखन के लिए उत्तरदायी होता है।
यह एंजाइम प्रतिलेखन के तीन मुख्य चरणों का पालन करता है:
$1$. प्रारंभन: $RNA$ पॉलीमरेज़ सिग्मा ($\sigma$) कारक की सहायता से प्रमोटर क्षेत्र से जुड़ता है।
$2$. दीर्घीकरण: यह एंजाइम $RNA$ श्रृंखला बनाने के लिए राइबोन्यूक्लियोटाइड्स के बहुलकीकरण की प्रक्रिया को सुगम बनाता है।
$3$. समापन: यह एंजाइम टर्मिनेटर अनुक्रम को पहचानता है और रो ($\rho$) कारक की सहायता से नवनिर्मित $RNA$ श्रृंखला को मुक्त करता है।
चूंकि $RNA$ पॉलीमरेज़ तीनों चरणों में शामिल है, इसलिए सही उत्तर $D$ है।
यह एंजाइम प्रतिलेखन के तीन मुख्य चरणों का पालन करता है:
$1$. प्रारंभन: $RNA$ पॉलीमरेज़ सिग्मा ($\sigma$) कारक की सहायता से प्रमोटर क्षेत्र से जुड़ता है।
$2$. दीर्घीकरण: यह एंजाइम $RNA$ श्रृंखला बनाने के लिए राइबोन्यूक्लियोटाइड्स के बहुलकीकरण की प्रक्रिया को सुगम बनाता है।
$3$. समापन: यह एंजाइम टर्मिनेटर अनुक्रम को पहचानता है और रो ($\rho$) कारक की सहायता से नवनिर्मित $RNA$ श्रृंखला को मुक्त करता है।
चूंकि $RNA$ पॉलीमरेज़ तीनों चरणों में शामिल है, इसलिए सही उत्तर $D$ है।
0 likes
View Solution148
MediumMCQ
निम्नलिखित में से कौन सा कार्य $RNA$ पॉलीमरेज़ का नहीं है?
A
दीर्घीकरण (Elongation)
B
राइबोन्यूक्लियोटाइड्स का बहुलकीकरण (Polymerization)
C
डीऑक्सीराइबोन्यूक्लियोटाइड्स का बहुलकीकरण
D
$DNA$ हेलिक्स को खोलना
Solution
(C) $RNA$ पॉलीमरेज़ वह एंजाइम है जो कोशिकाओं में अनुलेखन (Transcription) की प्रक्रिया के लिए जिम्मेदार होता है।
इसके मुख्य कार्यों में शामिल हैं:
$1$. टेम्पलेट स्ट्रैंड को उजागर करने के लिए $DNA$ हेलिक्स को खोलना।
$2$. $RNA$ श्रृंखला को संश्लेषित करने के लिए राइबोन्यूक्लियोटाइड्स का बहुलकीकरण करना।
$3$. $RNA$ ट्रांसक्रिप्ट का दीर्घीकरण (Elongation) करना।
विकल्प $C$ में 'डीऑक्सीराइबोन्यूक्लियोटाइड्स का बहुलकीकरण' दिया गया है,जो $DNA$ प्रतिकृति (Replication) के दौरान $DNA$ पॉलीमरेज़ का कार्य है,न कि $RNA$ पॉलीमरेज़ का। इसलिए,यह $RNA$ पॉलीमरेज़ का कार्य नहीं है।
इसके मुख्य कार्यों में शामिल हैं:
$1$. टेम्पलेट स्ट्रैंड को उजागर करने के लिए $DNA$ हेलिक्स को खोलना।
$2$. $RNA$ श्रृंखला को संश्लेषित करने के लिए राइबोन्यूक्लियोटाइड्स का बहुलकीकरण करना।
$3$. $RNA$ ट्रांसक्रिप्ट का दीर्घीकरण (Elongation) करना।
विकल्प $C$ में 'डीऑक्सीराइबोन्यूक्लियोटाइड्स का बहुलकीकरण' दिया गया है,जो $DNA$ प्रतिकृति (Replication) के दौरान $DNA$ पॉलीमरेज़ का कार्य है,न कि $RNA$ पॉलीमरेज़ का। इसलिए,यह $RNA$ पॉलीमरेज़ का कार्य नहीं है।
0 likes
View Solution149
MediumMCQ
अनुलेखन (Transcription) की प्रक्रिया किस स्थान पर समाप्त होती है?
A
समापक (Terminator)
B
प्रमोटर (Promoter)
C
ऑपरेटर (Operator)
D
संरचनात्मक जीन (Structural gene)
Solution
(A) अनुलेखन की प्रक्रिया में तीन मुख्य चरण होते हैं: प्रारंभन, दीर्घीकरण और समापन।
$1$. $Promoter$ वह स्थान है जहाँ $RNA$ पॉलीमरेज़ जुड़कर अनुलेखन शुरू करता है।
$2$. $Structural gene$ $DNA$ का वह खंड है जिसका अनुलेखन $RNA$ में होता है।
$3$. $Terminator$ अनुलेखन इकाई के अंत में स्थित वह विशिष्ट $DNA$ अनुक्रम है जहाँ अनुलेखन की प्रक्रिया रुक जाती है या समाप्त हो जाती है।
अतः, सही उत्तर $Terminator$ (समापक) है।
$1$. $Promoter$ वह स्थान है जहाँ $RNA$ पॉलीमरेज़ जुड़कर अनुलेखन शुरू करता है।
$2$. $Structural gene$ $DNA$ का वह खंड है जिसका अनुलेखन $RNA$ में होता है।
$3$. $Terminator$ अनुलेखन इकाई के अंत में स्थित वह विशिष्ट $DNA$ अनुक्रम है जहाँ अनुलेखन की प्रक्रिया रुक जाती है या समाप्त हो जाती है।
अतः, सही उत्तर $Terminator$ (समापक) है।
0 likes
View Solution150
MediumMCQ
प्रोकैरियोट्स में अनुलेखन (transcription) की प्रक्रिया में कौन-से कारक भाग लेते हैं?
A
प्रारंभन कारक
B
दीर्घीकरण कारक
C
समापन कारक
D
$A$ और $C$ दोनों
Solution
(D) प्रोकैरियोट्स में, अनुलेखन की प्रक्रिया $DNA$ पर निर्भर $RNA$ पॉलीमरेज़ द्वारा उत्प्रेरित होती है।
$1$. प्रारंभन: $RNA$ पॉलीमरेज़ प्रारंभन कारक, जिसे सिग्मा $(\sigma)$ कारक के रूप में जाना जाता है, की मदद से प्रमोटर साइट से जुड़ता है।
$2$. दीर्घीकरण: $RNA$ पॉलीमरेज़ $RNA$ श्रृंखला के दीर्घीकरण में सहायता करता है।
$3$. समापन: एक बार जब पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँच जाता है, तो नवजात $RNA$ अलग हो जाता है, जो समापन कारक, जिसे रो $(\rho)$ कारक के रूप में जाना जाता है, द्वारा सुगम होता है।
चूंकि प्रारंभन कारक $(\sigma)$ और समापन कारक $(\rho)$ दोनों प्रोकैरियोटिक अनुलेखन प्रक्रिया के आवश्यक घटक हैं, इसलिए सही उत्तर $A$ और $C$ दोनों है।
$1$. प्रारंभन: $RNA$ पॉलीमरेज़ प्रारंभन कारक, जिसे सिग्मा $(\sigma)$ कारक के रूप में जाना जाता है, की मदद से प्रमोटर साइट से जुड़ता है।
$2$. दीर्घीकरण: $RNA$ पॉलीमरेज़ $RNA$ श्रृंखला के दीर्घीकरण में सहायता करता है।
$3$. समापन: एक बार जब पॉलीमरेज़ टर्मिनेटर क्षेत्र तक पहुँच जाता है, तो नवजात $RNA$ अलग हो जाता है, जो समापन कारक, जिसे रो $(\rho)$ कारक के रूप में जाना जाता है, द्वारा सुगम होता है।
चूंकि प्रारंभन कारक $(\sigma)$ और समापन कारक $(\rho)$ दोनों प्रोकैरियोटिक अनुलेखन प्रक्रिया के आवश्यक घटक हैं, इसलिए सही उत्तर $A$ और $C$ दोनों है।
0 likes
View SolutionMolecular Basis of Inheritance — Transcription · Frequently Asked Questions
1Are these Molecular Basis of Inheritance questions useful for JEE and NEET?
Yes. All questions in this section are mapped to JEE Main and NEET exam patterns. Previous year questions from JEE Main, NEET, GUJCET and state-level exams are included with full solutions.
2Can I switch to Hindi or Gujarati for these questions?
Yes. Use the language tabs in the hero section or the sidebar to view the same questions and solutions in English, Hindi or Gujarati.
3How do I generate a question paper from this subtopic?
Use the Vedclass Exam Paper Generator — select the chapter and subtopic, set difficulty, and generate Sets A, B, C, D automatically. First 3 chapters of every subject are free.
Vedclass Products
For Students
Vedclass Test Series
Mock tests in real JEE/NEET style with performance analysis. 5-day free trial.
Start Free TrialFor Teachers
Exam Paper Generator
Generate Set A/B/C/D papers from this chapter in 2 minutes. 3 chapters free.
Try FreeFor Institutes
Online Exam Module
Live online exams with unlimited students, 360° analytics & white-label branding.
See DemoFor Teachers & Institutes
Generate a Molecular Basis of Inheritance Exam Paper in 2 Minutes
Select subtopic & difficulty — Sets A, B, C, D auto-generated with No Repeat logic.
First 3 chapters of every subject are free — no payment required.