
अ Hindi
Mix Example-Molecular Basis of Inheritance Questions in Hindi
Class 12 Biology · Molecular Basis of Inheritance · Mix Example-Molecular Basis of Inheritance
124+
Questions
Hindi
Language
100%
With Solutions
Showing 50 of 124 questions in Hindi
51
MediumMCQ
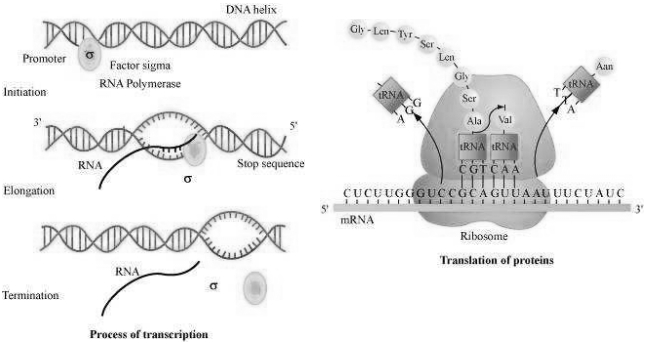
यह आरेख $DNA$ के आनुवंशिक निहितार्थ में एक महत्वपूर्ण अवधारणा को दर्शाता है। रिक्त स्थानों $A$ से $C$ को भरें।
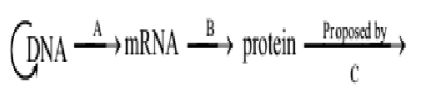
A
$A$ - अनुलेखन (Transcription),$B$ - स्थानांतरण (Translation),$C$ - फ्रांसिस क्रिक
B
$A$ - स्थानांतरण (Translation),$B$ - विस्तार (Extension),$C$ - रोज़ालिंड फ्रैंकलिन
C
$A$ - अनुलेखन (Transcription),$B$ - प्रतिकृति (Replication),$C$ - जेम्स वॉटसन
D
$A$ - स्थानांतरण (Translation),$B$ - अनुलेखन (Transcription),$C$ - इरविन चारगाफ
Solution
(A) सही उत्तर $A$ है।
आनुवंशिक पदार्थ की अभिव्यक्ति सामान्यतः प्रोटीन के उत्पादन के माध्यम से होती है। इसमें दो क्रमिक चरण शामिल हैं: अनुलेखन और स्थानांतरण।
$1$. अनुलेखन $(A)$: $DNA$ मैसेंजर $RNA$ $(mRNA)$ के उत्पादन के लिए कोड करता है।
$2$. स्थानांतरण $(B)$: $mRNA$ कोडित जानकारी को राइबोसोम तक ले जाता है,जो इस जानकारी को पढ़ते हैं और इसका उपयोग प्रोटीन संश्लेषण के लिए करते हैं।
$3$. सेंट्रल डोग्मा $(C)$: $F.H.C.$ क्रिक ने $1958$ में सूचना के इस एकदिशीय प्रवाह को 'आणविक जीव विज्ञान का सेंट्रल डोग्मा' के रूप में वर्णित किया था।
आनुवंशिक पदार्थ की अभिव्यक्ति सामान्यतः प्रोटीन के उत्पादन के माध्यम से होती है। इसमें दो क्रमिक चरण शामिल हैं: अनुलेखन और स्थानांतरण।
$1$. अनुलेखन $(A)$: $DNA$ मैसेंजर $RNA$ $(mRNA)$ के उत्पादन के लिए कोड करता है।
$2$. स्थानांतरण $(B)$: $mRNA$ कोडित जानकारी को राइबोसोम तक ले जाता है,जो इस जानकारी को पढ़ते हैं और इसका उपयोग प्रोटीन संश्लेषण के लिए करते हैं।
$3$. सेंट्रल डोग्मा $(C)$: $F.H.C.$ क्रिक ने $1958$ में सूचना के इस एकदिशीय प्रवाह को 'आणविक जीव विज्ञान का सेंट्रल डोग्मा' के रूप में वर्णित किया था।
0 likes
View Solution52
MediumMCQ
यह चित्र $DNA$ के आनुवंशिक निहितार्थ में एक महत्वपूर्ण अवधारणा को दर्शाता है। रिक्त स्थानों $A, B$ और $C$ को भरें।
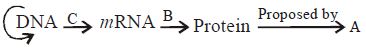
A
$A$-मौरिस विल्किंस,$B$-अनुलेखन (Transcription),$C$-अनुवाद (Translation)
B
$A$-जेम्स वॉटसन,$B$-प्रतिकृतियन (Replication),$C$-विस्तारण (Extension)
C
$A$-इरविन चारगाफ,$B$-अनुवाद (Translation),$C$-प्रतिकृतियन (Replication)
D
$A$-फ्रांसिस क्रिक,$B$-अनुवाद (Translation),$C$-अनुलेखन (Transcription)
Solution
(D) सही उत्तर $(d)$ है।
यह चित्र आणविक जीव विज्ञान के 'सेंट्रल डोग्मा' को दर्शाता है,जो आनुवंशिक जानकारी के एकदिशीय प्रवाह का वर्णन करता है।
$1$. $C$ अनुलेखन (Transcription) को दर्शाता है: यह वह प्रक्रिया है जिसमें $mRNA$ के संश्लेषण के लिए $DNA$ का उपयोग टेम्पलेट के रूप में किया जाता है।
$2$. $B$ अनुवाद (Translation) को दर्शाता है: यह वह प्रक्रिया है जिसमें $mRNA$ में मौजूद जानकारी का उपयोग राइबोसोम पर प्रोटीन संश्लेषण के लिए किया जाता है।
$3$. $A$ फ्रांसिस क्रिक को दर्शाता है: 'सेंट्रल डोग्मा' की अवधारणा $1958$ में फ्रांसिस क्रिक द्वारा प्रस्तावित की गई थी।
यह चित्र आणविक जीव विज्ञान के 'सेंट्रल डोग्मा' को दर्शाता है,जो आनुवंशिक जानकारी के एकदिशीय प्रवाह का वर्णन करता है।
$1$. $C$ अनुलेखन (Transcription) को दर्शाता है: यह वह प्रक्रिया है जिसमें $mRNA$ के संश्लेषण के लिए $DNA$ का उपयोग टेम्पलेट के रूप में किया जाता है।
$2$. $B$ अनुवाद (Translation) को दर्शाता है: यह वह प्रक्रिया है जिसमें $mRNA$ में मौजूद जानकारी का उपयोग राइबोसोम पर प्रोटीन संश्लेषण के लिए किया जाता है।
$3$. $A$ फ्रांसिस क्रिक को दर्शाता है: 'सेंट्रल डोग्मा' की अवधारणा $1958$ में फ्रांसिस क्रिक द्वारा प्रस्तावित की गई थी।
0 likes
View Solution53
MediumMCQ
विशिष्ट इकाई के बारे में निम्नलिखित में से कौन सा कथन सत्य है?
A
सेंट्रोमियर जंतु कोशिकाओं में पाया जाता है,जो कोशिका विभाजन के दौरान एस्टर उत्पन्न करता है।
B
इंसुलिन उत्पन्न करने वाला जीन शरीर की प्रत्येक कोशिका में मौजूद होता है।
C
न्यूक्लियोसोम न्यूक्लियोटाइड्स से बना होता है।
D
$DNA$ आठ हिस्टोन के कोर से बना होता है।
Solution
(B) सही कथन है।
$1$. इंसुलिन उत्पन्न करने वाला जीन शरीर की प्रत्येक कायिक कोशिका में मौजूद होता है क्योंकि सभी कोशिकाएं समसूत्री विभाजन द्वारा युग्मनज से उत्पन्न होती हैं और उनमें समान आनुवंशिक जानकारी होती है। हालाँकि,यह केवल अग्न्याशय की बीटा कोशिकाओं में ही अभिव्यक्त होता है।
$2$. सेंट्रियोल्स (सेंट्रोमियर नहीं) जंतु कोशिकाओं में पाए जाते हैं और कोशिका विभाजन के दौरान एस्टर उत्पन्न करते हैं।
$3$. न्यूक्लियोसोम आठ हिस्टोन प्रोटीन के कोर से बना होता है जिसके चारों ओर $DNA$ लिपटा होता है,न कि न्यूक्लियोटाइड्स से।
$4$. $DNA$ न्यूक्लियोटाइड्स का एक बहुलक है,न कि आठ हिस्टोन के कोर से बनी संरचना।
$1$. इंसुलिन उत्पन्न करने वाला जीन शरीर की प्रत्येक कायिक कोशिका में मौजूद होता है क्योंकि सभी कोशिकाएं समसूत्री विभाजन द्वारा युग्मनज से उत्पन्न होती हैं और उनमें समान आनुवंशिक जानकारी होती है। हालाँकि,यह केवल अग्न्याशय की बीटा कोशिकाओं में ही अभिव्यक्त होता है।
$2$. सेंट्रियोल्स (सेंट्रोमियर नहीं) जंतु कोशिकाओं में पाए जाते हैं और कोशिका विभाजन के दौरान एस्टर उत्पन्न करते हैं।
$3$. न्यूक्लियोसोम आठ हिस्टोन प्रोटीन के कोर से बना होता है जिसके चारों ओर $DNA$ लिपटा होता है,न कि न्यूक्लियोटाइड्स से।
$4$. $DNA$ न्यूक्लियोटाइड्स का एक बहुलक है,न कि आठ हिस्टोन के कोर से बनी संरचना।
0 likes
View Solution54
MediumMCQ
$DNA$ प्रतिकृति (replication) के दौरान बनने वाले रेप्लिकेशन फोर्क को निम्नलिखित में से कौन सा चित्र सही ढंग से दर्शाता है?
A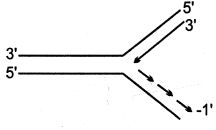
B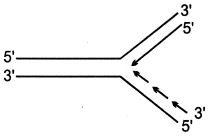
C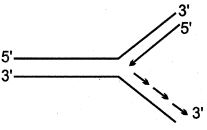
D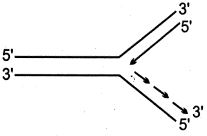
Solution
(C) $DNA$ प्रतिकृति के दौरान,$DNA$ के द्विकुंडलित (double helix) की दो लड़ें अलग होकर एक रेप्लिकेशन फोर्क बनाती हैं। $DNA$ पॉलीमरेज़ एंजाइम नई लड़ों का संश्लेषण केवल $5' \rightarrow 3'$ दिशा में ही करता है।
$1$. $3' \rightarrow 5'$ ध्रुवता वाली टेम्पलेट लड़ पर लीडिंग स्ट्रैंड (leading strand) का संश्लेषण रेप्लिकेशन फोर्क की दिशा में $5' \rightarrow 3'$ दिशा में निरंतर होता है।
$2$. $5' \rightarrow 3'$ ध्रुवता वाली टेम्पलेट लड़ पर लैगिंग स्ट्रैंड (lagging strand) का संश्लेषण ओकाज़ाकी टुकड़ों के रूप में रेप्लिकेशन फोर्क से दूर $5' \rightarrow 3'$ दिशा में असंतत रूप से होता है।
$3$. विकल्प $C$ में,टेम्पलेट लड़ में ऊपर $5'$ और नीचे $3'$ है। ऊपर वाली लड़ $(5' \rightarrow 3')$ लैगिंग स्ट्रैंड के लिए टेम्पलेट के रूप में कार्य करती है,और नीचे वाली लड़ $(3' \rightarrow 5')$ लीडिंग स्ट्रैंड के लिए टेम्पलेट के रूप में कार्य करती है। यह अभिविन्यास नई $DNA$ लड़ों के $5' \rightarrow 3'$ संश्लेषण को सही ढंग से दर्शाता है।
$1$. $3' \rightarrow 5'$ ध्रुवता वाली टेम्पलेट लड़ पर लीडिंग स्ट्रैंड (leading strand) का संश्लेषण रेप्लिकेशन फोर्क की दिशा में $5' \rightarrow 3'$ दिशा में निरंतर होता है।
$2$. $5' \rightarrow 3'$ ध्रुवता वाली टेम्पलेट लड़ पर लैगिंग स्ट्रैंड (lagging strand) का संश्लेषण ओकाज़ाकी टुकड़ों के रूप में रेप्लिकेशन फोर्क से दूर $5' \rightarrow 3'$ दिशा में असंतत रूप से होता है।
$3$. विकल्प $C$ में,टेम्पलेट लड़ में ऊपर $5'$ और नीचे $3'$ है। ऊपर वाली लड़ $(5' \rightarrow 3')$ लैगिंग स्ट्रैंड के लिए टेम्पलेट के रूप में कार्य करती है,और नीचे वाली लड़ $(3' \rightarrow 5')$ लीडिंग स्ट्रैंड के लिए टेम्पलेट के रूप में कार्य करती है। यह अभिविन्यास नई $DNA$ लड़ों के $5' \rightarrow 3'$ संश्लेषण को सही ढंग से दर्शाता है।
0 likes
View Solution55
MediumMCQ
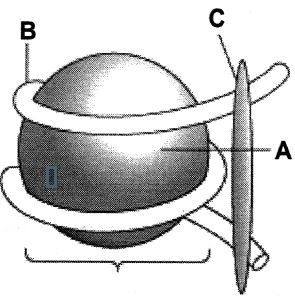
न्यूक्लियोसोम के दिए गए चित्र का अध्ययन करें और उस विकल्प का चयन करें जो $A, B$ और $C$ भागों की सही पहचान करता है।
A
$DNA$ ; हिस्टोन ऑक्टामर ; $H_1$ हिस्टोन
B
हिस्टोन ; $H_1$ हिस्टोन ; $DNA$ ऑक्टामर
C
हिस्टोन ऑक्टामर ; $DNA$ ; $H_1$ हिस्टोन
D
$DNA$ ; $H_1$ हिस्टोन ; हिस्टोन ऑक्टामर
Solution
(C) न्यूक्लियोसोम की संरचना में:
$A$ कोर कण को दर्शाता है,जो हिस्टोन ऑक्टामर है ($H2A, H2B, H3$ और $H4$ के दो-दो अणुओं से बना होता है)।
$B$ उस $DNA$ अणु को दर्शाता है जो हिस्टोन ऑक्टामर के चारों ओर लिपटा होता है।
$C$ $H_1$ हिस्टोन को दर्शाता है,जो उस स्थान पर $DNA$ से जुड़ता है जहाँ यह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है,जिससे संरचना को स्थिर करने में मदद मिलती है।
अतः,सही पहचान $A$ = हिस्टोन ऑक्टामर,$B$ = $DNA$,और $C$ = $H_1$ हिस्टोन है।
$A$ कोर कण को दर्शाता है,जो हिस्टोन ऑक्टामर है ($H2A, H2B, H3$ और $H4$ के दो-दो अणुओं से बना होता है)।
$B$ उस $DNA$ अणु को दर्शाता है जो हिस्टोन ऑक्टामर के चारों ओर लिपटा होता है।
$C$ $H_1$ हिस्टोन को दर्शाता है,जो उस स्थान पर $DNA$ से जुड़ता है जहाँ यह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है,जिससे संरचना को स्थिर करने में मदद मिलती है।
अतः,सही पहचान $A$ = हिस्टोन ऑक्टामर,$B$ = $DNA$,और $C$ = $H_1$ हिस्टोन है।
0 likes
View Solution56
MediumMCQ
निम्नलिखित का मिलान करें:
| स्तंभ-$I$ | स्तंभ-$II$ |
|---|---|
| $(1)$ लाइगेज | $(p)$ $DNA$ का खंड |
| $(2)$ $RNA$ पॉलीमरेज + रो कारक | $(q)$ प्रतिकृति (Replication) |
| $(3)$ $RNA$ पॉलीमरेज | $(r)$ समापन (Termination) |
| $(4)$ सिस्ट्रोन | $(s)$ दीर्घीकरण (Elongation) |
A
$(1-p), (2-q), (3-r), (4-s)$
B
$(1-q), (2-r), (3-s), (4-p)$
C
$(1-r), (2-p), (3-q), (4-s)$
D
$(1-s), (2-q), (3-p), (4-r)$
Solution
(B) सही मिलान इस प्रकार है:
$(1)$ लाइगेज: यह $DNA$ के टुकड़ों को जोड़ने के लिए उपयोग किया जाने वाला एंजाइम है,जो $DNA$ प्रतिकृति में एक महत्वपूर्ण चरण है। अतः,$(1-q)$.
$(2)$ $RNA$ पॉलीमरेज + रो कारक: रो कारक एक प्रोटीन है जो प्रोकैरियोट्स में ट्रांसक्रिप्शन के समापन में मदद करता है। अतः,$(2-r)$.
$(3)$ $RNA$ पॉलीमरेज: यह एंजाइम ट्रांसक्रिप्शन के दौरान $RNA$ श्रृंखला के दीर्घीकरण (Elongation) के लिए जिम्मेदार है। अतः,$(3-s)$.
$(4)$ सिस्ट्रोन: सिस्ट्रोन $DNA$ का एक खंड है जो पॉलीपेप्टाइड के लिए कोड करता है। अतः,$(4-p)$.
इसलिए,सही मिलान $(1-q), (2-r), (3-s), (4-p)$ है।
$(1)$ लाइगेज: यह $DNA$ के टुकड़ों को जोड़ने के लिए उपयोग किया जाने वाला एंजाइम है,जो $DNA$ प्रतिकृति में एक महत्वपूर्ण चरण है। अतः,$(1-q)$.
$(2)$ $RNA$ पॉलीमरेज + रो कारक: रो कारक एक प्रोटीन है जो प्रोकैरियोट्स में ट्रांसक्रिप्शन के समापन में मदद करता है। अतः,$(2-r)$.
$(3)$ $RNA$ पॉलीमरेज: यह एंजाइम ट्रांसक्रिप्शन के दौरान $RNA$ श्रृंखला के दीर्घीकरण (Elongation) के लिए जिम्मेदार है। अतः,$(3-s)$.
$(4)$ सिस्ट्रोन: सिस्ट्रोन $DNA$ का एक खंड है जो पॉलीपेप्टाइड के लिए कोड करता है। अतः,$(4-p)$.
इसलिए,सही मिलान $(1-q), (2-r), (3-s), (4-p)$ है।
0 likes
View Solution57
MediumMCQ
आरेख का उपयोग करके,$X$ और $Y$ के लिए सही विकल्प चुनें।

A
प्रतिकृति (Replication),प्रोटीन
B
कोशिका विभाजन,प्रोटीन
C
प्रतिकृति (Replication),अमीनो एसिड
D
$t-RNA$,$r-RNA$
Solution
(A) दिया गया आरेख आणविक जीव विज्ञान के सेंट्रल डोग्मा (Central Dogma) को दर्शाता है।
$1$. $DNA$ से $DNA$ बनने की प्रक्रिया को प्रतिकृति (Replication) कहा जाता है,जिसे $X$ द्वारा दर्शाया गया है।
$2$. $DNA$ से $mRNA$ बनने की प्रक्रिया को अनुलेखन (Transcription) कहा जाता है।
$3$. $mRNA$ से प्रोटीन बनने की प्रक्रिया को स्थानांतरण (Translation) कहा जाता है,जिसके परिणामस्वरूप $Y$ (प्रोटीन) का निर्माण होता है।
अतः,$X$ प्रतिकृति है और $Y$ प्रोटीन है।
$1$. $DNA$ से $DNA$ बनने की प्रक्रिया को प्रतिकृति (Replication) कहा जाता है,जिसे $X$ द्वारा दर्शाया गया है।
$2$. $DNA$ से $mRNA$ बनने की प्रक्रिया को अनुलेखन (Transcription) कहा जाता है।
$3$. $mRNA$ से प्रोटीन बनने की प्रक्रिया को स्थानांतरण (Translation) कहा जाता है,जिसके परिणामस्वरूप $Y$ (प्रोटीन) का निर्माण होता है।
अतः,$X$ प्रतिकृति है और $Y$ प्रोटीन है।
0 likes
View Solution58
MediumMCQ
यूकेरियोटिक जीनोम,प्रोकैरियोटिक जीनोम से अलग है क्योंकि . . . . . . .
A
प्रोकैरियोट्स में $DNA$ हिस्टोन के साथ जुड़ा होता है।
B
यूकेरियोट्स में पुनरावृत्ति अनुक्रम (repetitive sequences) मौजूद होते हैं।
C
यूकेरियोट्स में जीन ओपेरॉन के रूप में व्यवस्थित होते हैं।
D
प्रोकैरियोट्स में $DNA$ गोलाकार और एकल-सूत्री होता है।
Solution
(B) यूकेरियोटिक जीनोम प्रोकैरियोटिक जीनोम से कई तरह से भिन्न होता है। एक मुख्य अंतर यह है कि यूकेरियोट्स में पुनरावृत्ति $DNA$ अनुक्रम (repetitive sequences) मौजूद होते हैं,जो प्रोकैरियोट्स में अनुपस्थित होते हैं या बहुत कम होते हैं।
अन्य विकल्पों के बारे में:
विकल्प $A$ गलत है क्योंकि हिस्टोन प्रोटीन यूकेरियोटिक $DNA$ की विशेषता है,प्रोकैरियोटिक की नहीं।
विकल्प $C$ गलत है क्योंकि ओपेरॉन प्रोकैरियोटिक जीन विनियमन की विशेषता है,यूकेरियोटिक की नहीं।
विकल्प $D$ गलत है क्योंकि प्रोकैरियोटिक $DNA$ गोलाकार होता है लेकिन यह द्वि-सूत्री (double-stranded) होता है,एकल-सूत्री नहीं।
अन्य विकल्पों के बारे में:
विकल्प $A$ गलत है क्योंकि हिस्टोन प्रोटीन यूकेरियोटिक $DNA$ की विशेषता है,प्रोकैरियोटिक की नहीं।
विकल्प $C$ गलत है क्योंकि ओपेरॉन प्रोकैरियोटिक जीन विनियमन की विशेषता है,यूकेरियोटिक की नहीं।
विकल्प $D$ गलत है क्योंकि प्रोकैरियोटिक $DNA$ गोलाकार होता है लेकिन यह द्वि-सूत्री (double-stranded) होता है,एकल-सूत्री नहीं।
0 likes
View Solution59
MediumMCQ
$DNA$ में $A=T$ और $G=C$ युग्मों में क्षारों की वैकल्पिक संयोजकता अवस्थाओं को क्या कहा जाता है?
A
टोटोमेरिक शिफ्ट (Tautomeric shifts)
B
ट्रांजिशन म्यूटेशन
C
फ्रेमशिफ्ट म्यूटेशन
D
पॉइंट म्यूटेशन
Solution
(A) टोटोमेरिक शिफ्ट $DNA$ में नाइट्रोजनस क्षारों की आणविक संरचना में होने वाले स्वतःस्फूर्त परिवर्तन हैं।
इन परिवर्तनों में हाइड्रोजन परमाणु का स्थानांतरण शामिल होता है,जो क्षार को उसके मानक कीटो रूप से इमीनो या एनोल रूप में बदल देता है।
ये वैकल्पिक संयोजकता अवस्थाएं दुर्लभ और गलत बेस पेयरिंग (जैसे $A$ का $T$ के बजाय $C$ के साथ जुड़ना) की अनुमति देती हैं,जो $DNA$ प्रतिकृति के दौरान उत्परिवर्तन (mutations) का कारण बन सकती हैं।
इन परिवर्तनों में हाइड्रोजन परमाणु का स्थानांतरण शामिल होता है,जो क्षार को उसके मानक कीटो रूप से इमीनो या एनोल रूप में बदल देता है।
ये वैकल्पिक संयोजकता अवस्थाएं दुर्लभ और गलत बेस पेयरिंग (जैसे $A$ का $T$ के बजाय $C$ के साथ जुड़ना) की अनुमति देती हैं,जो $DNA$ प्रतिकृति के दौरान उत्परिवर्तन (mutations) का कारण बन सकती हैं।
0 likes
View Solution60
EasyMCQ
$1$ जीन $1$ एंजाइम संबंध सबसे पहले .......... में स्थापित किया गया था।
A
न्यूरोस्पोरा क्रासा
B
साल्मोनेला टाइफिम्यूरियम
C
एस्चेरिचिया कोलाई
D
डिप्लोकोकस न्यूमोनी
Solution
(A) $1$ जीन $1$ एंजाइम परिकल्पना जॉर्ज बीडल और एडवर्ड टैटम द्वारा $1941$ में प्रस्तावित की गई थी।
उन्होंने ब्रेड मोल्ड $Neurospora$ $crassa$ पर प्रयोग किए थे।
$X$-किरणों का उपयोग करके उत्परिवर्तन प्रेरित करने पर, उन्होंने देखा कि विशिष्ट उत्परिवर्तन विशिष्ट एंजाइमी गतिविधियों के नुकसान का कारण बनते हैं, जिससे यह सिद्ध हुआ कि प्रत्येक जीन एक विशिष्ट एंजाइम के संश्लेषण के लिए जिम्मेदार है।
उन्होंने ब्रेड मोल्ड $Neurospora$ $crassa$ पर प्रयोग किए थे।
$X$-किरणों का उपयोग करके उत्परिवर्तन प्रेरित करने पर, उन्होंने देखा कि विशिष्ट उत्परिवर्तन विशिष्ट एंजाइमी गतिविधियों के नुकसान का कारण बनते हैं, जिससे यह सिद्ध हुआ कि प्रत्येक जीन एक विशिष्ट एंजाइम के संश्लेषण के लिए जिम्मेदार है।
0 likes
View Solution61
MediumMCQ
चित्र $DNA$ के प्रभाव की एक महत्वपूर्ण अवधारणा को दर्शाता है। $A$ से $C$ तक रिक्त स्थानों की पूर्ति करें।
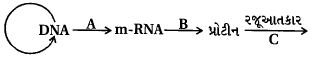
A
$A$ - अनुवाद,$B$ - वृद्धि,$C$ - रोज़ालिंड फ्रैंकलिन
B
$A$ - अनुलेखन,$B$ - प्रतिकृति,$C$ - जेम्स वॉटसन
C
$A$ - अनुवाद,$B$ - अनुलेखन,$C$ - इरविन चारगाफ
D
$A$ - अनुलेखन,$B$ - अनुवाद,$C$ - फ्रांसिस क्रिक
Solution
(D) दी गई आकृति आणविक जीव विज्ञान के सेंट्रल डोग्मा (Central Dogma) को दर्शाती है।
$1$. $DNA$ से $mRNA$ बनने की प्रक्रिया को अनुलेखन (Transcription) $(A)$ कहा जाता है।
$2$. $mRNA$ से प्रोटीन बनने की प्रक्रिया को अनुवाद (Translation) $(B)$ कहा जाता है।
$3$. सेंट्रल डोग्मा की अवधारणा फ्रांसिस क्रिक $(C)$ द्वारा प्रस्तावित की गई थी।
$1$. $DNA$ से $mRNA$ बनने की प्रक्रिया को अनुलेखन (Transcription) $(A)$ कहा जाता है।
$2$. $mRNA$ से प्रोटीन बनने की प्रक्रिया को अनुवाद (Translation) $(B)$ कहा जाता है।
$3$. सेंट्रल डोग्मा की अवधारणा फ्रांसिस क्रिक $(C)$ द्वारा प्रस्तावित की गई थी।
0 likes
View Solution62
MediumMCQ
निम्नलिखित में से कौन सा युग्म सही सुमेलित नहीं है?
A
ट्रांसक्रिप्शन $\to$ $DNA$ से $RNA$ में जानकारी लिखना
B
ट्रांसलेशन $\to$ $mRNA$ पर मौजूद जानकारी का उपयोग करके प्रोटीन का संश्लेषण करना
C
रिप्रेसर प्रोटीन $\to$ एंजाइम संश्लेषण को रोकने के लिए ऑपरेटर से जुड़ता है
D
ओपेरॉन $\to$ संरचनात्मक जीन,ऑपरेटर और प्रमोटर
Solution
(NONE) आणविक जीवविज्ञान के संदर्भ में दिए गए सभी विकल्प सही सुमेलित हैं:
$1$. ट्रांसक्रिप्शन वह प्रक्रिया है जिसमें $DNA$ की एक रज्जुक से आनुवंशिक जानकारी को $RNA$ में कॉपी किया जाता है।
$2$. ट्रांसलेशन वह प्रक्रिया है जिसमें $mRNA$ पर मौजूद कोडोन के अनुक्रम के आधार पर अमीनो एसिड के बहुलकीकरण से पॉलीपेप्टाइड का निर्माण होता है।
$3$. रिप्रेसर प्रोटीन ओपेरॉन के ऑपरेटर क्षेत्र से जुड़ता है ताकि संरचनात्मक जीन का ट्रांसक्रिप्शन रुक सके,जिससे एंजाइम का संश्लेषण बंद हो जाता है।
$4$. ओपेरॉन एक सामान्य प्रमोटर और नियामक जीन (ऑपरेटर सहित) द्वारा नियंत्रित पॉलीसिस्ट्रोनिक संरचनात्मक जीन से बना होता है।
चूंकि सभी विकल्प सही हैं,इसलिए सूची में कोई भी युग्म गलत नहीं है।
$1$. ट्रांसक्रिप्शन वह प्रक्रिया है जिसमें $DNA$ की एक रज्जुक से आनुवंशिक जानकारी को $RNA$ में कॉपी किया जाता है।
$2$. ट्रांसलेशन वह प्रक्रिया है जिसमें $mRNA$ पर मौजूद कोडोन के अनुक्रम के आधार पर अमीनो एसिड के बहुलकीकरण से पॉलीपेप्टाइड का निर्माण होता है।
$3$. रिप्रेसर प्रोटीन ओपेरॉन के ऑपरेटर क्षेत्र से जुड़ता है ताकि संरचनात्मक जीन का ट्रांसक्रिप्शन रुक सके,जिससे एंजाइम का संश्लेषण बंद हो जाता है।
$4$. ओपेरॉन एक सामान्य प्रमोटर और नियामक जीन (ऑपरेटर सहित) द्वारा नियंत्रित पॉलीसिस्ट्रोनिक संरचनात्मक जीन से बना होता है।
चूंकि सभी विकल्प सही हैं,इसलिए सूची में कोई भी युग्म गलत नहीं है।
0 likes
View Solution63
MediumMCQ
$T_4$ बैक्टीरियोफेज की $rII$ उत्परिवर्ती (mutant) प्रजाति $E. coli$ को तोड़ने (lyse) में विफल रहती है। हालाँकि,जब दो प्रजातियों $rII^X$ और $rII^Y$ को मिश्रित किया जाता है,तो वे $E. coli$ को तोड़ देती हैं। इसका संभावित कारण क्या है?
A
बैक्टीरियोफेज असंगठित रूप में परिवर्तित हो जाता है।
B
उनमें कोई उत्परिवर्तन नहीं होता है।
C
दोनों प्रजातियों में समान सिस्ट्रोन होते हैं।
D
दोनों प्रजातियों में अलग-अलग सिस्ट्रोन होते हैं।
Solution
(D) यह प्रयोग सीमोर बेंजर द्वारा किए गए कॉम्प्लीमेंटेशन टेस्ट (complementation test) पर आधारित है।
$1$. $T_4$ बैक्टीरियोफेज के $rII$ म्यूटेंट $E. coli$ की $K$ प्रजाति पर विकसित नहीं हो पाते हैं।
$2$. जब दो अलग-अलग $rII$ म्यूटेंट को एक ही $E. coli$ कोशिका में प्रवेश कराया जाता है,तो यदि उत्परिवर्तन अलग-अलग कार्यात्मक इकाइयों (सिस्ट्रोन) में होते हैं,तो वे एक-दूसरे की कमी को पूरा (complement) कर सकते हैं।
$3$. यदि उत्परिवर्तन अलग-अलग सिस्ट्रोन में होते हैं,तो एक म्यूटेंट में अनुपस्थित कार्यात्मक प्रोटीन दूसरे द्वारा प्रदान किया जाता है,जिससे फेज प्रतिकृति (replicate) कर सकता है और मेजबान कोशिका को तोड़ सकता है।
$4$. इसलिए,लिसिस (lysis) होता है क्योंकि दोनों प्रजातियों में अलग-अलग सिस्ट्रोन में उत्परिवर्तन होते हैं,जो एक-दूसरे के पूरक बनकर वाइल्ड-टाइप कार्य को बहाल करते हैं।
$1$. $T_4$ बैक्टीरियोफेज के $rII$ म्यूटेंट $E. coli$ की $K$ प्रजाति पर विकसित नहीं हो पाते हैं।
$2$. जब दो अलग-अलग $rII$ म्यूटेंट को एक ही $E. coli$ कोशिका में प्रवेश कराया जाता है,तो यदि उत्परिवर्तन अलग-अलग कार्यात्मक इकाइयों (सिस्ट्रोन) में होते हैं,तो वे एक-दूसरे की कमी को पूरा (complement) कर सकते हैं।
$3$. यदि उत्परिवर्तन अलग-अलग सिस्ट्रोन में होते हैं,तो एक म्यूटेंट में अनुपस्थित कार्यात्मक प्रोटीन दूसरे द्वारा प्रदान किया जाता है,जिससे फेज प्रतिकृति (replicate) कर सकता है और मेजबान कोशिका को तोड़ सकता है।
$4$. इसलिए,लिसिस (lysis) होता है क्योंकि दोनों प्रजातियों में अलग-अलग सिस्ट्रोन में उत्परिवर्तन होते हैं,जो एक-दूसरे के पूरक बनकर वाइल्ड-टाइप कार्य को बहाल करते हैं।
0 likes
View Solution64
EasyMCQ
दी गई आकृति एक न्यूक्लियोसोम की संरचना को दर्शाती है,जिसके भागों को $A, B$ और $C$ के रूप में नामांकित किया गया है। $A, B$ और $C$ की पहचान करें।
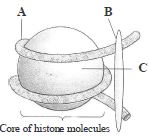
A
$A - DNA$; $B - H_1$ हिस्टोन; $C -$ हिस्टोन ऑक्टामर
B
$A - H_1$ हिस्टोन; $B - DNA$; $C -$ हिस्टोन ऑक्टामर
C
$A -$ हिस्टोन ऑक्टामर; $B - RNA$; $C - H_1$ हिस्टोन
D
$A - RNA$; $B - H_1$ हिस्टोन; $C -$ हिस्टोन ऑक्टामर
Solution
(A) न्यूक्लियोसोम यूकेरियोटिक क्रोमैटिन की मूल संरचनात्मक इकाई है,जो हिस्टोन प्रोटीन के एक कोर के चारों ओर लिपटे $DNA$ के एक खंड से बनी होती है।
दी गई आकृति में:
$A$ उस $DNA$ अणु को दर्शाता है जो हिस्टोन कोर के चारों ओर लिपटा होता है।
$B$ उस $H_1$ हिस्टोन प्रोटीन को दर्शाता है,जो $DNA$ के साथ वहां जुड़ता है जहां वह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है।
$C$ हिस्टोन ऑक्टामर को दर्शाता है,जो चार हिस्टोन प्रोटीन ($H2A, H2B, H3,$ और $H4$) में से प्रत्येक के दो अणुओं से बना कोर कॉम्प्लेक्स है।
अतः,सही पहचान $A - DNA, B - H_1$ हिस्टोन,और $C -$ हिस्टोन ऑक्टामर है।
दी गई आकृति में:
$A$ उस $DNA$ अणु को दर्शाता है जो हिस्टोन कोर के चारों ओर लिपटा होता है।
$B$ उस $H_1$ हिस्टोन प्रोटीन को दर्शाता है,जो $DNA$ के साथ वहां जुड़ता है जहां वह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है।
$C$ हिस्टोन ऑक्टामर को दर्शाता है,जो चार हिस्टोन प्रोटीन ($H2A, H2B, H3,$ और $H4$) में से प्रत्येक के दो अणुओं से बना कोर कॉम्प्लेक्स है।
अतः,सही पहचान $A - DNA, B - H_1$ हिस्टोन,और $C -$ हिस्टोन ऑक्टामर है।
0 likes
View Solution65
MediumMCQ
कथन : हिस्टोन यूकेरियोटिक $DNA$ की पैकेजिंग में प्रमुख महत्व वाले क्षारीय (basic) प्रोटीन हैं। $DNA$ और हिस्टोन मिलकर क्रोमैटिन बनाते हैं जो यूकेरियोटिक गुणसूत्र का मुख्य भाग है।
कारण : हिस्टोन पांच प्रमुख प्रकार के होते हैं: $H_1, H_2A, H_2B, H_3$ और $H_4$ ।
कारण : हिस्टोन पांच प्रमुख प्रकार के होते हैं: $H_1, H_2A, H_2B, H_3$ और $H_4$ ।
A
यदि कथन और कारण दोनों सही हैं और कारण,कथन की सही व्याख्या है।
B
यदि कथन और कारण दोनों सही हैं लेकिन कारण,कथन की सही व्याख्या नहीं है।
C
यदि कथन सही है लेकिन कारण गलत है।
D
यदि कथन और कारण दोनों गलत हैं।
Solution
(B) हिस्टोन यूकेरियोटिक गुणसूत्रों में पाए जाने वाले क्षारीय प्रोटीन हैं,जो लाइसिन और आर्जिनिन जैसे धनावेशित अमीनो एसिड से भरपूर होते हैं।
ये प्रोटीन ऋणावेशित $DNA$ को क्रोमैटिन में पैक करने के लिए आवश्यक हैं।
हिस्टोन प्रोटीन के पांच प्रमुख प्रकार हैं: $H_1, H_2A, H_2B, H_3$ और $H_4$ ।
यद्यपि कथन और कारण दोनों वैज्ञानिक रूप से सही हैं,लेकिन कारण केवल हिस्टोन के प्रकारों का वर्णन करता है,यह सीधे तौर पर यह नहीं समझाता कि वे पैकेजिंग के लिए महत्वपूर्ण क्यों हैं (जो उनके क्षारीय स्वभाव और आवेश से संबंधित है)।
इसलिए,कारण,कथन की सही व्याख्या नहीं है।
ये प्रोटीन ऋणावेशित $DNA$ को क्रोमैटिन में पैक करने के लिए आवश्यक हैं।
हिस्टोन प्रोटीन के पांच प्रमुख प्रकार हैं: $H_1, H_2A, H_2B, H_3$ और $H_4$ ।
यद्यपि कथन और कारण दोनों वैज्ञानिक रूप से सही हैं,लेकिन कारण केवल हिस्टोन के प्रकारों का वर्णन करता है,यह सीधे तौर पर यह नहीं समझाता कि वे पैकेजिंग के लिए महत्वपूर्ण क्यों हैं (जो उनके क्षारीय स्वभाव और आवेश से संबंधित है)।
इसलिए,कारण,कथन की सही व्याख्या नहीं है।
0 likes
View Solution66
Medium
निम्नलिखित के बीच अंतर स्पष्ट कीजिए:
$(a)$ पुनरावृत्त $DNA$ और सैटेलाइट $DNA$
$(b)$ $mRNA$ और $tRNA$
$(c)$ टेम्पलेट रज्जुक और कोडिंग रज्जुक
$(a)$ पुनरावृत्त $DNA$ और सैटेलाइट $DNA$
$(b)$ $mRNA$ और $tRNA$
$(c)$ टेम्पलेट रज्जुक और कोडिंग रज्जुक
Solution
(N/A) पुनरावृत्त $DNA$ और सैटेलाइट $DNA$
$(b)$ $mRNA$ और $tRNA$
$(c)$ टेम्पलेट रज्जुक और कोडिंग रज्जुक
| पुनरावृत्त $DNA$ | सैटेलाइट $DNA$ |
|---|---|
| $DNA$ अनुक्रम जिनमें छोटे खंड जीनोम में कई बार दोहराए जाते हैं। | पुनरावृत्त $DNA$ का एक उपसमुच्चय जिसमें अत्यधिक पुनरावृत्त अनुक्रम होते हैं जो घनत्व प्रवणता सेंट्रीफ्यूजेशन के दौरान अलग बैंड बनाते हैं। |
$(b)$ $mRNA$ और $tRNA$
| संख्या | $mRNA$ (मैसेंजर $RNA$) | $tRNA$ (ट्रांसफर $RNA$) |
|---|---|---|
| $1.$ | प्रोटीन संश्लेषण के लिए $DNA$ से आनुवंशिक जानकारी ले जाने वाले टेम्पलेट के रूप में कार्य करता है। | अनुवाद के दौरान राइबोसोम तक विशिष्ट अमीनो एसिड ले जाने वाले एडेप्टर अणु के रूप में कार्य करता है। |
| $2.$ | यह एक रैखिक अणु है। | इसकी विशिष्ट क्लोवर-लीफ द्वितीयक संरचना (या $L$-आकार की $3D$ संरचना) होती है। |
$(c)$ टेम्पलेट रज्जुक और कोडिंग रज्जुक
| संख्या | टेम्पलेट रज्जुक | कोडिंग रज्जुक |
|---|---|---|
| $1.$ | $RNA$ संश्लेषण के लिए टेम्पलेट के रूप में कार्य करता है; इसका अनुक्रम $mRNA$ का पूरक होता है। | टेम्पलेट के रूप में कार्य नहीं करता; इसका अनुक्रम $mRNA$ के समान होता है ($T$ के स्थान पर $U$ को छोड़कर)। |
| $2.$ | यह $3' \to 5'$ दिशा में चलता है। | यह $5' \to 3'$ दिशा में चलता है। |
0 likes
View Solution67
Difficult
निम्नलिखित का संक्षिप्त वर्णन कीजिए:
$(a)$ अनुलेखन (Transcription)
$(b)$ बहुरूपता (Polymorphism)
$(c)$ स्थानांतरण (Translation)
$(d)$ जैव सूचना विज्ञान (Bioinformatics)
$(a)$ अनुलेखन (Transcription)
$(b)$ बहुरूपता (Polymorphism)
$(c)$ स्थानांतरण (Translation)
$(d)$ जैव सूचना विज्ञान (Bioinformatics)
Solution
(N/A) अनुलेखन: अनुलेखन $DNA$ टेम्पलेट से $RNA$ के संश्लेषण की प्रक्रिया है। इस प्रक्रिया के दौरान $DNA$ का एक खंड $mRNA$ में कॉपी हो जाता है। यह प्रक्रिया प्रमोटर क्षेत्र से शुरू होती है और टर्मिनेटर क्षेत्र पर समाप्त होती है। इन दो क्षेत्रों के बीच के $DNA$ खंड को अनुलेखन इकाई कहा जाता है। इसके लिए $RNA$ पॉलीमरेज़ एंजाइम,$DNA$ टेम्पलेट,चार प्रकार के राइबोन्यूक्लियोटाइड्स और $Mg^{2+}$ जैसे सह-कारकों की आवश्यकता होती है। इसके तीन चरण हैं: दीक्षा,बढ़ाव और समापन। $DNA$-निर्भर $RNA$ पॉलीमरेज़ और दीक्षा कारक $(\sigma)$ प्रमोटर से जुड़ते हैं। एंजाइम $DNA$ को खोलता है और $mRNA$ बनाने के लिए टेम्पलेट स्ट्रैंड का उपयोग करता है। टर्मिनेटर पर पहुँचने पर,समापन कारक $(\rho)$ की मदद से $mRNA$ और एंजाइम मुक्त हो जाते हैं।
$(b)$ बहुरूपता: बहुरूपता आनुवंशिक भिन्नता का एक रूप है जिसमें $DNA$ अणु के एक विशिष्ट स्थान पर अलग न्यूक्लियोटाइड अनुक्रम मौजूद हो सकते हैं। यह वंशानुगत उत्परिवर्तन आबादी में उच्च आवृत्ति पर देखा जाता है। यह दैहिक या जनन कोशिकाओं में उत्परिवर्तन के कारण उत्पन्न होता है। जनन कोशिका का उत्परिवर्तन संतानों में स्थानांतरित हो जाता है,जो विकास और प्रजाति निर्माण के लिए महत्वपूर्ण है।
$(c)$ स्थानांतरण: स्थानांतरण पॉलीपेप्टाइड श्रृंखला बनाने के लिए अमीनो एसिड के बहुलकीकरण की प्रक्रिया है। $mRNA$ में बेस जोड़े का ट्रिपलेट अनुक्रम अमीनो एसिड का क्रम निर्धारित करता है। इसमें दीक्षा,बढ़ाव और समापन शामिल हैं। $tRNA$ को $ATP$ का उपयोग करके चार्ज किया जाता है। छोटा राइबोसोमल सबयूनिट $mRNA$ के स्टार्ट कोडोन $(AUG)$ से जुड़ता है,जिसके बाद बड़ा सबयूनिट जुड़ता है। बढ़ाव के दौरान,राइबोसोम $mRNA$ पर आगे बढ़ता है और अमीनो एसिड पेप्टाइड बॉन्ड द्वारा जुड़ जाते हैं। जब राइबोसोम $STOP$ कोडोन ($UAA, UAG,$ या $UGA$) पर पहुँचता है,तो स्थानांतरण समाप्त हो जाता है और पॉलीपेप्टाइड श्रृंखला मुक्त हो जाती है।
$(d)$ जैव सूचना विज्ञान: जैव सूचना विज्ञान आणविक जीव विज्ञान में कम्प्यूटेशनल और सांख्यिकीय तकनीकों का अनुप्रयोग है। यह जैविक डेटा के प्रबंधन और विश्लेषण की समस्याओं का समाधान करता है। यह मानव जीनोम परियोजना $(HGP)$ के बाद विकसित हुआ है। इसमें जैविक डेटाबेस बनाना और प्रोटीन संरचना,कार्यों और अनुक्रमों के बीच संबंधों का विश्लेषण करने के लिए एल्गोरिदम विकसित करना शामिल है।
$(b)$ बहुरूपता: बहुरूपता आनुवंशिक भिन्नता का एक रूप है जिसमें $DNA$ अणु के एक विशिष्ट स्थान पर अलग न्यूक्लियोटाइड अनुक्रम मौजूद हो सकते हैं। यह वंशानुगत उत्परिवर्तन आबादी में उच्च आवृत्ति पर देखा जाता है। यह दैहिक या जनन कोशिकाओं में उत्परिवर्तन के कारण उत्पन्न होता है। जनन कोशिका का उत्परिवर्तन संतानों में स्थानांतरित हो जाता है,जो विकास और प्रजाति निर्माण के लिए महत्वपूर्ण है।
$(c)$ स्थानांतरण: स्थानांतरण पॉलीपेप्टाइड श्रृंखला बनाने के लिए अमीनो एसिड के बहुलकीकरण की प्रक्रिया है। $mRNA$ में बेस जोड़े का ट्रिपलेट अनुक्रम अमीनो एसिड का क्रम निर्धारित करता है। इसमें दीक्षा,बढ़ाव और समापन शामिल हैं। $tRNA$ को $ATP$ का उपयोग करके चार्ज किया जाता है। छोटा राइबोसोमल सबयूनिट $mRNA$ के स्टार्ट कोडोन $(AUG)$ से जुड़ता है,जिसके बाद बड़ा सबयूनिट जुड़ता है। बढ़ाव के दौरान,राइबोसोम $mRNA$ पर आगे बढ़ता है और अमीनो एसिड पेप्टाइड बॉन्ड द्वारा जुड़ जाते हैं। जब राइबोसोम $STOP$ कोडोन ($UAA, UAG,$ या $UGA$) पर पहुँचता है,तो स्थानांतरण समाप्त हो जाता है और पॉलीपेप्टाइड श्रृंखला मुक्त हो जाती है।
$(d)$ जैव सूचना विज्ञान: जैव सूचना विज्ञान आणविक जीव विज्ञान में कम्प्यूटेशनल और सांख्यिकीय तकनीकों का अनुप्रयोग है। यह जैविक डेटा के प्रबंधन और विश्लेषण की समस्याओं का समाधान करता है। यह मानव जीनोम परियोजना $(HGP)$ के बाद विकसित हुआ है। इसमें जैविक डेटाबेस बनाना और प्रोटीन संरचना,कार्यों और अनुक्रमों के बीच संबंधों का विश्लेषण करने के लिए एल्गोरिदम विकसित करना शामिल है।
0 likes
View Solution68
Medium
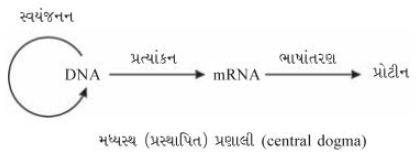
आणविक जीवविज्ञान में केंद्रीय सिद्धांत (Central Dogma) के बारे में समझाइए।
Solution
(N/A) आणविक जीवविज्ञान में केंद्रीय सिद्धांत (Central Dogma) फ्रांसिस क्रिक द्वारा प्रस्तावित किया गया था।
यह बताता है कि आनुवंशिक जानकारी का प्रवाह इस दिशा में होता है: $DNA \to mRNA \to$ प्रोटीन।
$1$. प्रतिकृति (Replication): $DNA$ अपनी स्वयं की प्रतिलिपि बनाता है।
$2$. अनुलेखन (Transcription): $DNA$ को $mRNA$ में बदला जाता है।
$3$. स्थानांतरण (Translation): $mRNA$ को प्रोटीन अनुक्रम में अनुवादित किया जाता है।
यह बताता है कि आनुवंशिक जानकारी का प्रवाह इस दिशा में होता है: $DNA \to mRNA \to$ प्रोटीन।
$1$. प्रतिकृति (Replication): $DNA$ अपनी स्वयं की प्रतिलिपि बनाता है।
$2$. अनुलेखन (Transcription): $DNA$ को $mRNA$ में बदला जाता है।
$3$. स्थानांतरण (Translation): $mRNA$ को प्रोटीन अनुक्रम में अनुवादित किया जाता है।
0 likes
View Solution69
Medium
अंतर स्पष्ट कीजिए: $m-RNA$ और $t-RNA$.
Solution
(N/A)
| $m-RNA$ | $t-RNA$ |
|---|---|
| $(1)$ यह प्रोटीन संश्लेषण के लिए आनुवंशिक जानकारी को केंद्रक से कोशिका द्रव्य तक ले जाता है। | $(1)$ यह विशिष्ट अमीनो एसिड से जुड़ता है और उन्हें राइबोसोम की सतह तक ले जाता है। |
| $(2)$ जीन अभिव्यक्ति के आधार पर कोशिका में अलग-अलग समय पर कई $m-RNA$ इकाइयां सक्रिय होती हैं। | $(2)$ $20$ प्रकार के अमीनो एसिड के परिवहन के लिए $61$ प्रकार के $t-RNA$ संभव हैं (जो $61$ कोडोन के अनुरूप हैं)। |
| $(3)$ $m-RNA$ अपना कार्य पूरा करने के बाद विघटित हो जाता है। | $(3)$ $t-RNA$ अणु आमतौर पर स्थिर होते हैं और आसानी से विघटित नहीं होते हैं। |
| $(4)$ $m-RNA$ में न्यूक्लियोटाइड का क्रम प्रोटीन संरचना में अमीनो एसिड के क्रम और स्थिति को निर्धारित करता है। | $(4)$ प्रत्येक $t-RNA$ एक विशिष्ट प्रकार के अमीनो एसिड का वहन करता है। |
0 likes
View Solution70
Medium
परिभाषा / व्याख्या कीजिए:
$1.$ न्यूक्लियोटाइड
$2.$ सेंट्रल डोग्मा (केंद्रीय सिद्धांत)
$1.$ न्यूक्लियोटाइड
$2.$ सेंट्रल डोग्मा (केंद्रीय सिद्धांत)
Solution
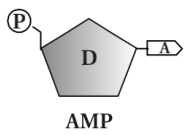
(N/A) $1.$ न्यूक्लियोटाइड: जब एक फॉस्फेट समूह एक न्यूक्लियोसाइड के $5'-OH$ समूह के साथ फॉस्फोएस्टर बंधन द्वारा जुड़ता है, तो न्यूक्लियोटाइड का निर्माण होता है।
$2.$ सेंट्रल डोग्मा: आनुवंशिक जानकारी का प्रवाह $DNA$ से $mRNA$ में अनुलेखन (transcription) के माध्यम से होता है, जिसे बाद में अनुवाद (translation) प्रक्रिया द्वारा प्रोटीन संश्लेषण में बदला जाता है। इस प्रवाह को इस प्रकार दर्शाया जाता है: $DNA \rightarrow mRNA \rightarrow \text{प्रोटीन}$.
$2.$ सेंट्रल डोग्मा: आनुवंशिक जानकारी का प्रवाह $DNA$ से $mRNA$ में अनुलेखन (transcription) के माध्यम से होता है, जिसे बाद में अनुवाद (translation) प्रक्रिया द्वारा प्रोटीन संश्लेषण में बदला जाता है। इस प्रवाह को इस प्रकार दर्शाया जाता है: $DNA \rightarrow mRNA \rightarrow \text{प्रोटीन}$.
0 likes
View Solution71
Medium
निम्नलिखित शब्दों के बीच अंतर स्पष्ट कीजिए:
$1.$ लीडिंग स्ट्रैंड - लैगिंग स्ट्रैंड
$2.$ $t-RNA$ - $m-RNA$
$3.$ मोनोसिस्ट्रोनिक - पॉलिसिस्ट्रोनिक
$1.$ लीडिंग स्ट्रैंड - लैगिंग स्ट्रैंड
$2.$ $t-RNA$ - $m-RNA$
$3.$ मोनोसिस्ट्रोनिक - पॉलिसिस्ट्रोनिक
Solution
(N/A) लीडिंग स्ट्रैंड: $DNA$ प्रतिकृति के दौरान,वह स्ट्रैंड जिसका संश्लेषण $5^{\prime} \rightarrow 3^{\prime}$ दिशा में निरंतर होता है,उसे लीडिंग स्ट्रैंड कहा जाता है।
लैगिंग स्ट्रैंड: वह स्ट्रैंड जिसका संश्लेषण $5^{\prime} \rightarrow 3^{\prime}$ दिशा में छोटे टुकड़ों (ओकाजाकी खंडों) के रूप में असंतत होता है,उसे लैगिंग स्ट्रैंड कहा जाता है।
$t-RNA$: यह एक एडाप्टर अणु के रूप में कार्य करता है जो प्रोटीन संश्लेषण के दौरान विशिष्ट अमीनो एसिड को राइबोसोम तक ले जाता है।
$m-RNA$: यह $DNA$ से प्रोटीन संश्लेषण के लिए आनुवंशिक जानकारी को राइबोसोम तक ले जाता है।
मोनोसिस्ट्रोनिक: एक संरचनात्मक जीन जो एक एकल पॉलीपेप्टाइड श्रृंखला के लिए कूटलेखन (code) करता है,जो आमतौर पर यूकेरियोट्स में पाया जाता है।
पॉलिसिस्ट्रोनिक: एक संरचनात्मक जीन जो कई पॉलीपेप्टाइड श्रृंखलाओं के लिए कूटलेखन करता है,जो आमतौर पर प्रोकैरियोट्स में पाया जाता है।
लैगिंग स्ट्रैंड: वह स्ट्रैंड जिसका संश्लेषण $5^{\prime} \rightarrow 3^{\prime}$ दिशा में छोटे टुकड़ों (ओकाजाकी खंडों) के रूप में असंतत होता है,उसे लैगिंग स्ट्रैंड कहा जाता है।
$t-RNA$: यह एक एडाप्टर अणु के रूप में कार्य करता है जो प्रोटीन संश्लेषण के दौरान विशिष्ट अमीनो एसिड को राइबोसोम तक ले जाता है।
$m-RNA$: यह $DNA$ से प्रोटीन संश्लेषण के लिए आनुवंशिक जानकारी को राइबोसोम तक ले जाता है।
मोनोसिस्ट्रोनिक: एक संरचनात्मक जीन जो एक एकल पॉलीपेप्टाइड श्रृंखला के लिए कूटलेखन (code) करता है,जो आमतौर पर यूकेरियोट्स में पाया जाता है।
पॉलिसिस्ट्रोनिक: एक संरचनात्मक जीन जो कई पॉलीपेप्टाइड श्रृंखलाओं के लिए कूटलेखन करता है,जो आमतौर पर प्रोकैरियोट्स में पाया जाता है।
0 likes
View Solution72
Medium
निम्नलिखित वैज्ञानिकों की भूमिका स्पष्ट कीजिए:
$1.$ एवेरी, मैकलियोड और मैक्कार्टी $(1933-44)$
$2.$ मैथ्यू मेसेलसन और फ्रैंकलिन स्टाहल $(1958)$
$1.$ एवेरी, मैकलियोड और मैक्कार्टी $(1933-44)$
$2.$ मैथ्यू मेसेलसन और फ्रैंकलिन स्टाहल $(1958)$
Solution
(N/A) $1.$ ओसवाल्ड एवेरी, कॉलिन मैकलियोड और मैकलिन मैक्कार्टी $(1933-44)$: इन्होंने ग्रिफिथ के प्रयोग में 'रूपांतरणकारी सिद्धांत' $(transforming\, principle)$ की जैव-रासायनिक प्रकृति निर्धारित करने के लिए कार्य किया। इन्होंने DNase, RNase और प्रोटीएज जैसे एंजाइमों का उपयोग करके यह सिद्ध किया कि $DNA$ ही आनुवंशिक पदार्थ है, न कि प्रोटीन या $RNA$।
$2.$ मैथ्यू मेसेलसन और फ्रैंकलिन स्टाहल $(1958)$: इन्होंने $^{15}N$ (भारी नाइट्रोजन) युक्त माध्यम में विकसित $E. coli$ का उपयोग करके प्रयोग किया और फिर उन्हें $^{14}N$ (हल्के नाइट्रोजन) माध्यम में स्थानांतरित किया। इनके परिणामों ने सिद्ध किया कि $DNA$ का प्रतिकृतियन अर्ध-संरक्षी $(semi-conservative)$ होता है।
$2.$ मैथ्यू मेसेलसन और फ्रैंकलिन स्टाहल $(1958)$: इन्होंने $^{15}N$ (भारी नाइट्रोजन) युक्त माध्यम में विकसित $E. coli$ का उपयोग करके प्रयोग किया और फिर उन्हें $^{14}N$ (हल्के नाइट्रोजन) माध्यम में स्थानांतरित किया। इनके परिणामों ने सिद्ध किया कि $DNA$ का प्रतिकृतियन अर्ध-संरक्षी $(semi-conservative)$ होता है।
0 likes
View Solution73
Medium
सेंट्रल डोग्मा (Central Dogma) क्या है और $DNA$ हेलिक्स की पैकेजिंग का वर्णन कीजिए?
Solution
(N/A) फ्रांसिस क्रिक ने आणविक जीवविज्ञान में सेंट्रल डोग्मा का प्रस्ताव रखा, जो बताता है कि आनुवंशिक जानकारी का प्रवाह $DNA \to RNA \to$ प्रोटीन की दिशा में होता है।
कुछ वायरस में सूचना का प्रवाह विपरीत दिशा में होता है, यानी $RNA$ से $DNA$ की ओर।
दो क्रमिक बेस पेयर के बीच की दूरी को $0.34 \, nm$ $(0.34 \times 10^{-9} \, m)$ मानते हुए, यदि एक विशिष्ट स्तनधारी कोशिका में $DNA$ डबल हेलिक्स की लंबाई की गणना की जाए (कुल $bp$ की संख्या को दो क्रमिक $bp$ के बीच की दूरी से गुणा करके, यानी $6.6 \times 10^9 \, bp \times 0.34 \times 10^{-9} \, m/bp$), तो यह लगभग $2.2 \, \text{मीटर}$ आती है।
यह लंबाई एक विशिष्ट केंद्रक के आयाम (लगभग $10^{-6} \, m$) से कहीं अधिक है।
प्रोकैरियोट्स में, जैसे $E. coli$, हालांकि उनके पास एक परिभाषित केंद्रक नहीं होता है, फिर भी $DNA$ पूरी कोशिका में बिखरा हुआ नहीं होता है। $DNA$ (ऋणात्मक रूप से आवेशित होने के कारण) कुछ प्रोटीन (जिनमें धनात्मक आवेश होता है) के साथ 'न्यूक्लियोइड' नामक क्षेत्र में बंधा होता है। न्यूक्लियोइड में $DNA$ प्रोटीन द्वारा पकड़े गए बड़े लूप में व्यवस्थित होता है।
यूकेरियोट्स में, यह संगठन बहुत अधिक जटिल है। इसमें हिस्टोन नामक धनात्मक रूप से आवेशित, क्षारीय प्रोटीन का एक समूह होता है। एक प्रोटीन आवेशित साइड चेन वाले अमीनो एसिड अवशेषों की प्रचुरता के आधार पर आवेश प्राप्त करता है। हिस्टोन क्षारीय अमीनो एसिड अवशेषों लाइसिन और आर्जिनिन में समृद्ध होते हैं। ये दोनों अमीनो एसिड अवशेष अपनी साइड चेन में धनात्मक आवेश रखते हैं।
कुछ वायरस में सूचना का प्रवाह विपरीत दिशा में होता है, यानी $RNA$ से $DNA$ की ओर।
दो क्रमिक बेस पेयर के बीच की दूरी को $0.34 \, nm$ $(0.34 \times 10^{-9} \, m)$ मानते हुए, यदि एक विशिष्ट स्तनधारी कोशिका में $DNA$ डबल हेलिक्स की लंबाई की गणना की जाए (कुल $bp$ की संख्या को दो क्रमिक $bp$ के बीच की दूरी से गुणा करके, यानी $6.6 \times 10^9 \, bp \times 0.34 \times 10^{-9} \, m/bp$), तो यह लगभग $2.2 \, \text{मीटर}$ आती है।
यह लंबाई एक विशिष्ट केंद्रक के आयाम (लगभग $10^{-6} \, m$) से कहीं अधिक है।
प्रोकैरियोट्स में, जैसे $E. coli$, हालांकि उनके पास एक परिभाषित केंद्रक नहीं होता है, फिर भी $DNA$ पूरी कोशिका में बिखरा हुआ नहीं होता है। $DNA$ (ऋणात्मक रूप से आवेशित होने के कारण) कुछ प्रोटीन (जिनमें धनात्मक आवेश होता है) के साथ 'न्यूक्लियोइड' नामक क्षेत्र में बंधा होता है। न्यूक्लियोइड में $DNA$ प्रोटीन द्वारा पकड़े गए बड़े लूप में व्यवस्थित होता है।
यूकेरियोट्स में, यह संगठन बहुत अधिक जटिल है। इसमें हिस्टोन नामक धनात्मक रूप से आवेशित, क्षारीय प्रोटीन का एक समूह होता है। एक प्रोटीन आवेशित साइड चेन वाले अमीनो एसिड अवशेषों की प्रचुरता के आधार पर आवेश प्राप्त करता है। हिस्टोन क्षारीय अमीनो एसिड अवशेषों लाइसिन और आर्जिनिन में समृद्ध होते हैं। ये दोनों अमीनो एसिड अवशेष अपनी साइड चेन में धनात्मक आवेश रखते हैं।
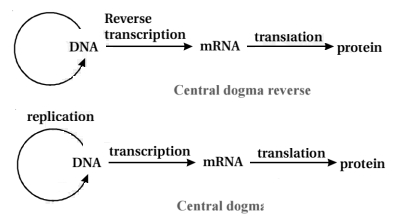
0 likes
View Solution74
Medium
$DNA$ और $RNA$ के गुणों पर एक तुलनात्मक टिप्पणी लिखिए।
Solution
(N/A) हर्षे-चेज़ प्रयोग से यह एक स्थापित तथ्य बन गया कि $DNA$ ही आनुवंशिक पदार्थ के रूप में कार्य करता है।
हालाँकि,बाद में यह स्पष्ट हो गया कि कुछ वायरस में $RNA$ आनुवंशिक पदार्थ होता है (उदाहरण के लिए,टोबैको मोज़ेक वायरस,$QB$ बैक्टीरियोफेज आदि)।
एक अणु जो आनुवंशिक पदार्थ के रूप में कार्य कर सकता है,उसे निम्नलिखित मानदंडों को पूरा करना चाहिए:
$(i)$ इसे अपनी प्रतिकृति (Replication) बनाने में सक्षम होना चाहिए।
$(ii)$ इसे रासायनिक और संरचनात्मक रूप से स्थिर होना चाहिए।
$(iii)$ इसे विकास के लिए आवश्यक धीमे परिवर्तनों (उत्परिवर्तन) के लिए गुंजाइश प्रदान करनी चाहिए।
$(iv)$ इसे 'मेंडेलियन लक्षणों' के रूप में खुद को व्यक्त करने में सक्षम होना चाहिए।
इन आवश्यकताओं की तुलना:
- बेस पेयरिंग और पूरकता के नियम के कारण,दोनों न्यूक्लिक एसिड ($DNA$ और $RNA$) अपनी प्रतिकृति बनाने की क्षमता रखते हैं।
- प्रोटीन पहले मानदंड को पूरा करने में विफल रहते हैं।
- स्थिरता: आनुवंशिक पदार्थ इतना स्थिर होना चाहिए कि वह जीवन चक्र के विभिन्न चरणों,उम्र या शरीर क्रिया विज्ञान में बदलाव के साथ न बदले। ग्रिफिथ के प्रयोग ने दिखाया कि गर्मी ने आनुवंशिक पदार्थ $(DNA)$ के गुणों को नष्ट नहीं किया।
- रासायनिक स्थिरता: $RNA$ में प्रत्येक न्यूक्लियोटाइड पर मौजूद $2'-OH$ समूह एक प्रतिक्रियाशील समूह है,जो $RNA$ को अस्थिर और आसानी से विघटित होने योग्य बनाता है। $RNA$ उत्प्रेरक भी है,इसलिए यह अधिक प्रतिक्रियाशील है।
- $DNA$ रासायनिक रूप से कम प्रतिक्रियाशील और $RNA$ की तुलना में संरचनात्मक रूप से अधिक स्थिर है। यूरेसिल के स्थान पर थाइमिन की उपस्थिति $DNA$ को अतिरिक्त स्थिरता प्रदान करती है।
- उत्परिवर्तन: $DNA$ और $RNA$ दोनों उत्परिवर्तित हो सकते हैं। $RNA$ अस्थिर होने के कारण,तेज दर से उत्परिवर्तित होता है। परिणामस्वरूप,$RNA$ जीनोम वाले वायरस तेजी से विकसित होते हैं।
- अभिव्यक्ति: $RNA$ सीधे प्रोटीन संश्लेषण के लिए कोड कर सकता है,जबकि $DNA$ प्रोटीन संश्लेषण के लिए $RNA$ पर निर्भर है। प्रोटीन संश्लेषण की मशीनरी $RNA$ के चारों ओर विकसित हुई है।
निष्कर्ष: दोनों आनुवंशिक पदार्थ के रूप में कार्य कर सकते हैं,लेकिन $DNA$ अपनी स्थिरता के कारण आनुवंशिक जानकारी के भंडारण के लिए बेहतर है,जबकि $RNA$ आनुवंशिक जानकारी के संचरण के लिए बेहतर है।
हालाँकि,बाद में यह स्पष्ट हो गया कि कुछ वायरस में $RNA$ आनुवंशिक पदार्थ होता है (उदाहरण के लिए,टोबैको मोज़ेक वायरस,$QB$ बैक्टीरियोफेज आदि)।
एक अणु जो आनुवंशिक पदार्थ के रूप में कार्य कर सकता है,उसे निम्नलिखित मानदंडों को पूरा करना चाहिए:
$(i)$ इसे अपनी प्रतिकृति (Replication) बनाने में सक्षम होना चाहिए।
$(ii)$ इसे रासायनिक और संरचनात्मक रूप से स्थिर होना चाहिए।
$(iii)$ इसे विकास के लिए आवश्यक धीमे परिवर्तनों (उत्परिवर्तन) के लिए गुंजाइश प्रदान करनी चाहिए।
$(iv)$ इसे 'मेंडेलियन लक्षणों' के रूप में खुद को व्यक्त करने में सक्षम होना चाहिए।
इन आवश्यकताओं की तुलना:
- बेस पेयरिंग और पूरकता के नियम के कारण,दोनों न्यूक्लिक एसिड ($DNA$ और $RNA$) अपनी प्रतिकृति बनाने की क्षमता रखते हैं।
- प्रोटीन पहले मानदंड को पूरा करने में विफल रहते हैं।
- स्थिरता: आनुवंशिक पदार्थ इतना स्थिर होना चाहिए कि वह जीवन चक्र के विभिन्न चरणों,उम्र या शरीर क्रिया विज्ञान में बदलाव के साथ न बदले। ग्रिफिथ के प्रयोग ने दिखाया कि गर्मी ने आनुवंशिक पदार्थ $(DNA)$ के गुणों को नष्ट नहीं किया।
- रासायनिक स्थिरता: $RNA$ में प्रत्येक न्यूक्लियोटाइड पर मौजूद $2'-OH$ समूह एक प्रतिक्रियाशील समूह है,जो $RNA$ को अस्थिर और आसानी से विघटित होने योग्य बनाता है। $RNA$ उत्प्रेरक भी है,इसलिए यह अधिक प्रतिक्रियाशील है।
- $DNA$ रासायनिक रूप से कम प्रतिक्रियाशील और $RNA$ की तुलना में संरचनात्मक रूप से अधिक स्थिर है। यूरेसिल के स्थान पर थाइमिन की उपस्थिति $DNA$ को अतिरिक्त स्थिरता प्रदान करती है।
- उत्परिवर्तन: $DNA$ और $RNA$ दोनों उत्परिवर्तित हो सकते हैं। $RNA$ अस्थिर होने के कारण,तेज दर से उत्परिवर्तित होता है। परिणामस्वरूप,$RNA$ जीनोम वाले वायरस तेजी से विकसित होते हैं।
- अभिव्यक्ति: $RNA$ सीधे प्रोटीन संश्लेषण के लिए कोड कर सकता है,जबकि $DNA$ प्रोटीन संश्लेषण के लिए $RNA$ पर निर्भर है। प्रोटीन संश्लेषण की मशीनरी $RNA$ के चारों ओर विकसित हुई है।
निष्कर्ष: दोनों आनुवंशिक पदार्थ के रूप में कार्य कर सकते हैं,लेकिन $DNA$ अपनी स्थिरता के कारण आनुवंशिक जानकारी के भंडारण के लिए बेहतर है,जबकि $RNA$ आनुवंशिक जानकारी के संचरण के लिए बेहतर है।
0 likes
View Solution75
Medium
स्तंभों का मिलान करें।
| स्तंभ-$I$ | स्तंभ-$II$ |
| $(a)$ स्प्लिसिंग | $(1)$ लैक ओपेरॉन |
| $(b)$ ओकाज़ाकी खंड | $(2)$ लैगिंग स्ट्रैंड्स |
| $(c)$ जैकब और मोनोड | $(3)$ लैक्टोज़ |
| $(d)$ इंड्यूसर | $(4)$ इंट्रॉन्स को हटाना |
Solution
$(A)$ सही मिलान इस प्रकार है:
$(a)$ स्प्लिसिंग का अर्थ है प्री-mRNA से इंट्रॉन्स को हटाना और एक्सॉन्स को जोड़ना, जो $(4)$ से मेल खाता है।
$(b)$ ओकाज़ाकी खंड $DNA$ प्रतिकृति के दौरान लैगिंग स्ट्रैंड पर असतत रूप से संश्लेषित छोटे $DNA$ अनुक्रम हैं, जो $(2)$ से मेल खाते हैं।
$(c)$ जैकब और मोनोड वे वैज्ञानिक थे जिन्होंने ओपेरॉन मॉडल, विशेष रूप से लैक ओपेरॉन का प्रस्ताव दिया था, जो $(1)$ से मेल खाता है।
$(d)$ इंड्यूसर एक ऐसा अणु है जो रिप्रेसर प्रोटीन से जुड़कर जीन अभिव्यक्ति को नियंत्रित करता है; लैक ओपेरॉन में, लैक्टोज़ इंड्यूसर के रूप में कार्य करता है, जो $(3)$ से मेल खाता है।
अतः, सही मिलान $(a-4, b-2, c-1, d-3)$ है।
$(a)$ स्प्लिसिंग का अर्थ है प्री-mRNA से इंट्रॉन्स को हटाना और एक्सॉन्स को जोड़ना, जो $(4)$ से मेल खाता है।
$(b)$ ओकाज़ाकी खंड $DNA$ प्रतिकृति के दौरान लैगिंग स्ट्रैंड पर असतत रूप से संश्लेषित छोटे $DNA$ अनुक्रम हैं, जो $(2)$ से मेल खाते हैं।
$(c)$ जैकब और मोनोड वे वैज्ञानिक थे जिन्होंने ओपेरॉन मॉडल, विशेष रूप से लैक ओपेरॉन का प्रस्ताव दिया था, जो $(1)$ से मेल खाता है।
$(d)$ इंड्यूसर एक ऐसा अणु है जो रिप्रेसर प्रोटीन से जुड़कर जीन अभिव्यक्ति को नियंत्रित करता है; लैक ओपेरॉन में, लैक्टोज़ इंड्यूसर के रूप में कार्य करता है, जो $(3)$ से मेल खाता है।
अतः, सही मिलान $(a-4, b-2, c-1, d-3)$ है।
0 likes
View Solution76
Easy
निम्नलिखित शब्दों को परिभाषित कीजिए: रेप्लिकेशन फोर्क (प्रतिकृति द्विशाख) और ट्रांसक्रिप्शन (अनुलेखन)।
Solution
(N/A) $1$. रेप्लिकेशन फोर्क: लंबे $DNA$ अणुओं के लिए,चूंकि $DNA$ की दोनों लड़ियाँ अपनी पूरी लंबाई में अलग नहीं हो सकती हैं,इसलिए प्रतिकृति $DNA$ हेलिक्स के एक छोटे से खुले हिस्से के भीतर होती है,जिसे रेप्लिकेशन फोर्क कहा जाता है।
$2$. ट्रांसक्रिप्शन: $DNA$ की एक लड़ी से आनुवंशिक जानकारी को $RNA$ में कॉपी करने की प्रक्रिया को ट्रांसक्रिप्शन (अनुलेखन) कहा जाता है।
$2$. ट्रांसक्रिप्शन: $DNA$ की एक लड़ी से आनुवंशिक जानकारी को $RNA$ में कॉपी करने की प्रक्रिया को ट्रांसक्रिप्शन (अनुलेखन) कहा जाता है।
0 likes
View Solution77
MediumMCQ
निम्नलिखित में से कौन सा आनुवंशिकी (Genetics) के अध्ययन से संबंधित नहीं है?
A
माता-पिता के लक्षणों का संतानों में स्थानांतरित होने की घटना
B
संतानों का अपने माता-पिता से भिन्न होना
C
$DNA$ से $RNA$ और उससे प्रोटीन का निर्माण
D
$A$ और $B$ दोनों
Solution
(C) आनुवंशिकी जीव विज्ञान की वह शाखा है जो आनुवंशिकता और विभिन्नता के अध्ययन से संबंधित है।
$1$. आनुवंशिकता (Inheritance) वह प्रक्रिया है जिसके द्वारा लक्षण माता-पिता से संतानों में स्थानांतरित होते हैं।
$2$. विभिन्नता (Variation) वह सीमा है जिससे संतानों में अपने माता-पिता से अंतर पाया जाता है।
$3$. $DNA$ से $RNA$ (अनुलेखन) और $RNA$ से प्रोटीन (अनुवाद) का संश्लेषण आणविक जीव विज्ञान के 'सेंट्रल डोग्मा' का हिस्सा है,जो यह बताता है कि कोशिका के भीतर आनुवंशिक जानकारी कैसे प्रवाहित होती है।
हालांकि आनुवंशिकी में जीन और उनकी अभिव्यक्ति का अध्ययन शामिल है,लेकिन $DNA$ से $RNA$ और प्रोटीन संश्लेषण की विशिष्ट प्रक्रिया को 'आणविक जीव विज्ञान' (Molecular Biology) के अंतर्गत वर्गीकृत किया जाता है,जबकि आनुवंशिकी का मुख्य केंद्र आनुवंशिकता और विभिन्नता पर होता है। इसलिए,विकल्प $C$ आनुवंशिकता और विभिन्नता के संदर्भ में आनुवंशिकी की शास्त्रीय परिभाषा से सबसे कम सीधे तौर पर जुड़ा हुआ है।
$1$. आनुवंशिकता (Inheritance) वह प्रक्रिया है जिसके द्वारा लक्षण माता-पिता से संतानों में स्थानांतरित होते हैं।
$2$. विभिन्नता (Variation) वह सीमा है जिससे संतानों में अपने माता-पिता से अंतर पाया जाता है।
$3$. $DNA$ से $RNA$ (अनुलेखन) और $RNA$ से प्रोटीन (अनुवाद) का संश्लेषण आणविक जीव विज्ञान के 'सेंट्रल डोग्मा' का हिस्सा है,जो यह बताता है कि कोशिका के भीतर आनुवंशिक जानकारी कैसे प्रवाहित होती है।
हालांकि आनुवंशिकी में जीन और उनकी अभिव्यक्ति का अध्ययन शामिल है,लेकिन $DNA$ से $RNA$ और प्रोटीन संश्लेषण की विशिष्ट प्रक्रिया को 'आणविक जीव विज्ञान' (Molecular Biology) के अंतर्गत वर्गीकृत किया जाता है,जबकि आनुवंशिकी का मुख्य केंद्र आनुवंशिकता और विभिन्नता पर होता है। इसलिए,विकल्प $C$ आनुवंशिकता और विभिन्नता के संदर्भ में आनुवंशिकी की शास्त्रीय परिभाषा से सबसे कम सीधे तौर पर जुड़ा हुआ है।
0 likes
View Solution78
DifficultMCQ
सिकल-सेल एनीमिया में,$DNA$ की उस श्रृंखला पर दोषपूर्ण नाइट्रोजन बेस का क्रम क्या है जो टेम्पलेट के रूप में कार्य नहीं करती है?
A
$GAG$
B
$GTG$
C
$CTC$
D
$CAC$
Solution
(B) सिकल-सेल एनीमिया हीमोग्लोबिन के $\beta$-ग्लोबिन जीन में बिंदु उत्परिवर्तन (point mutation) के कारण होता है।
सामान्य जीन में,टेम्पलेट श्रृंखला पर $CTC$ क्रम होता है,जो mRNA में $GAG$ के लिए कोड करता है,जिसके परिणामस्वरूप ग्लूटेमिक एसिड अमीनो एसिड बनता है।
उत्परिवर्तित जीन में,टेम्पलेट श्रृंखला पर $CTC$ क्रम बदलकर $CAC$ हो जाता है।
परिणामस्वरूप,नॉन-टेम्पलेट (कोडिंग) श्रृंखला,जिसमें mRNA के समान क्रम होता है ($U$ के स्थान पर $T$ के साथ),वह $GAG$ से बदलकर $GTG$ हो जाती है।
अतः,नॉन-टेम्पलेट श्रृंखला पर दोषपूर्ण क्रम $GTG$ है।
सामान्य जीन में,टेम्पलेट श्रृंखला पर $CTC$ क्रम होता है,जो mRNA में $GAG$ के लिए कोड करता है,जिसके परिणामस्वरूप ग्लूटेमिक एसिड अमीनो एसिड बनता है।
उत्परिवर्तित जीन में,टेम्पलेट श्रृंखला पर $CTC$ क्रम बदलकर $CAC$ हो जाता है।
परिणामस्वरूप,नॉन-टेम्पलेट (कोडिंग) श्रृंखला,जिसमें mRNA के समान क्रम होता है ($U$ के स्थान पर $T$ के साथ),वह $GAG$ से बदलकर $GTG$ हो जाती है।
अतः,नॉन-टेम्पलेट श्रृंखला पर दोषपूर्ण क्रम $GTG$ है।
0 likes
View Solution79
MediumMCQ
निम्नलिखित में से किसमें आनुवंशिक सूचना का प्रवाह विपरीत दिशा में होता है?
A
वायरस
B
बैक्टीरिया
C
पादप
D
जंतु
Solution
(A) आणविक जीवविज्ञान के सेंट्रल डोग्मा के अनुसार, आनुवंशिक सूचना का प्रवाह $DNA \rightarrow RNA \rightarrow \text{प्रोटीन}$ दिशा में होता है।
कुछ वायरस में, विशेष रूप से $HIV$ जैसे रेट्रोवायरस में, रिवर्स ट्रांसक्रिप्टेज एंजाइम मौजूद होता है।
यह एंजाइम आनुवंशिक सूचना को $RNA$ से वापस $DNA$ में प्रवाहित होने देता है, जिसे रिवर्स ट्रांसक्रिप्शन कहा जाता है।
इसलिए, आनुवंशिक सूचना का विपरीत दिशा में प्रवाह वायरस में होता है।
कुछ वायरस में, विशेष रूप से $HIV$ जैसे रेट्रोवायरस में, रिवर्स ट्रांसक्रिप्टेज एंजाइम मौजूद होता है।
यह एंजाइम आनुवंशिक सूचना को $RNA$ से वापस $DNA$ में प्रवाहित होने देता है, जिसे रिवर्स ट्रांसक्रिप्शन कहा जाता है।
इसलिए, आनुवंशिक सूचना का विपरीत दिशा में प्रवाह वायरस में होता है।
0 likes
View Solution80
MediumMCQ
किस प्रक्रिया में न्यूक्लिक एसिड से न्यूक्लिक एसिड का संश्लेषण होता है?
A
प्रतिकृतियन (Replication)
B
अनुलेखन (Transcription)
C
स्थानांतरण (Translation)
D
$A$ और $B$ दोनों
Solution
(D) प्रतिकृतियन (Replication) वह प्रक्रिया है जिसमें $DNA$ टेम्पलेट से $DNA$ का संश्लेषण होता है।
अनुलेखन (Transcription) वह प्रक्रिया है जिसमें $DNA$ टेम्पलेट से $RNA$ का संश्लेषण होता है।
दोनों प्रक्रियाओं में,एक न्यूक्लिक एसिड (टेम्पलेट) का उपयोग करके दूसरे न्यूक्लिक एसिड (नया स्ट्रैंड) का निर्माण किया जाता है।
अतः,सही उत्तर $A$ और $B$ दोनों है।
अनुलेखन (Transcription) वह प्रक्रिया है जिसमें $DNA$ टेम्पलेट से $RNA$ का संश्लेषण होता है।
दोनों प्रक्रियाओं में,एक न्यूक्लिक एसिड (टेम्पलेट) का उपयोग करके दूसरे न्यूक्लिक एसिड (नया स्ट्रैंड) का निर्माण किया जाता है।
अतः,सही उत्तर $A$ और $B$ दोनों है।
0 likes
View Solution81
MediumMCQ
निम्नलिखित स्तंभों का सही मिलान करें:
| स्तंभ-$I$ | स्तंभ-$II$ |
| $(W)$ ग्रिफिथ | $(1)$ $DNA$ आनुवंशिक पदार्थ है |
| $(X)$ एवरी,मैकलियोड | $(2)$ अर्ध-संरक्षी प्रतिकृति |
| $(Y)$ मेसेलसन-स्टाल | $(3)$ रूपांतरण सिद्धांत |
| $(Z)$ हर्षे और चेस | $(4)$ $DNase$ द्वारा रूपांतरण प्रक्रिया बाधित होती है |
A
$W-1, X-3, Y-2, Z-4$
B
$W-3, X-4, Y-2, Z-1$
C
$W-4, X-3, Y-2, Z-1$
D
$W-1, X-2, Y-4, Z-3$
Solution
(B) सही मिलान इस प्रकार है:
$(W)$ ग्रिफिथ: $Streptococcus$ $pneumoniae$ पर अपने प्रयोगों के माध्यम से 'रूपांतरण सिद्धांत' प्रस्तावित किया $(3)$।
$(X)$ एवरी,मैकलियोड और मैक्कार्टी: प्रदर्शित किया कि $DNase$ रूपांतरण प्रक्रिया को रोकता है,जिससे यह सिद्ध हुआ कि $DNA$ ही रूपांतरण करने वाला पदार्थ है $(4)$।
$(Y)$ मेसेलसन-स्टाल: $DNA$ प्रतिकृति की अर्ध-संरक्षी विधि के लिए प्रायोगिक प्रमाण प्रदान किए $(2)$।
$(Z)$ हर्षे और चेस: बैक्टीरियोफेज का उपयोग करके यह सिद्ध किया कि $DNA$ आनुवंशिक पदार्थ है $(1)$।
अतः,सही क्रम $W-3, X-4, Y-2, Z-1$ है।
$(W)$ ग्रिफिथ: $Streptococcus$ $pneumoniae$ पर अपने प्रयोगों के माध्यम से 'रूपांतरण सिद्धांत' प्रस्तावित किया $(3)$।
$(X)$ एवरी,मैकलियोड और मैक्कार्टी: प्रदर्शित किया कि $DNase$ रूपांतरण प्रक्रिया को रोकता है,जिससे यह सिद्ध हुआ कि $DNA$ ही रूपांतरण करने वाला पदार्थ है $(4)$।
$(Y)$ मेसेलसन-स्टाल: $DNA$ प्रतिकृति की अर्ध-संरक्षी विधि के लिए प्रायोगिक प्रमाण प्रदान किए $(2)$।
$(Z)$ हर्षे और चेस: बैक्टीरियोफेज का उपयोग करके यह सिद्ध किया कि $DNA$ आनुवंशिक पदार्थ है $(1)$।
अतः,सही क्रम $W-3, X-4, Y-2, Z-1$ है।
0 likes
View Solution82
MediumMCQ
सूची-$I$ में दिए गए एंजाइमों का सूची-$II$ में उनके कार्यों के साथ मिलान करें :
| सूची-$I$ | सूची-$II$ |
| $(a)$ हेलिकेज | $(i)$ $DNA$ पर आधारित $DNA$ संश्लेषण |
| $(b)$ राइबोन्यूक्लिएज | $(ii)$ $RNA$ का पाचन |
| $(c)$ रिवर्स ट्रांसक्रिप्टेज | $(iii)$ $DNA$ की दो श्रृंखलाओं के बीच हाइड्रोजन बंध तोड़ना |
| $(d)$ $DNA$ पॉलीमरेज | $(iv)$ $RNA$ पर आधारित $DNA$ संश्लेषण |
A
$a-iii, b-ii, c-i, d-iv$
B
$a-iii, b-ii, c-iv, d-i$
C
$a-ii, b-iii, c-i, d-iv$
D
$a-i, b-iv, c-iii, d-ii$
Solution
(B) सही मिलान इस प्रकार है:
$(a)$ हेलिकेज: यह एंजाइम $DNA$ की दो श्रृंखलाओं के बीच हाइड्रोजन बंधों को तोड़कर $DNA$ हेलिक्स को खोलने के लिए जिम्मेदार है, जो $(iii)$ से मेल खाता है।
$(b)$ राइबोन्यूक्लिएज: यह एंजाइम विशेष रूप से $RNA$ अणुओं के पाचन या अपघटन को उत्प्रेरित करता है, जो $(ii)$ से मेल खाता है।
$(c)$ रिवर्स ट्रांसक्रिप्टेज: यह एंजाइम $RNA$ टेम्पलेट का उपयोग करके $DNA$ का संश्लेषण करता है, जिसे रिवर्स ट्रांसक्रिप्शन कहा जाता है, जो $(iv)$ से मेल खाता है।
$(d)$ $DNA$ पॉलीमरेज: यह एंजाइम मौजूदा $DNA$ टेम्पलेट का उपयोग करके एक नई $DNA$ श्रृंखला को संश्लेषित करने के लिए जिम्मेदार है, जो $(i)$ से मेल खाता है।
अतः, सही क्रम $a-iii, b-ii, c-iv, d-i$ है।
$(a)$ हेलिकेज: यह एंजाइम $DNA$ की दो श्रृंखलाओं के बीच हाइड्रोजन बंधों को तोड़कर $DNA$ हेलिक्स को खोलने के लिए जिम्मेदार है, जो $(iii)$ से मेल खाता है।
$(b)$ राइबोन्यूक्लिएज: यह एंजाइम विशेष रूप से $RNA$ अणुओं के पाचन या अपघटन को उत्प्रेरित करता है, जो $(ii)$ से मेल खाता है।
$(c)$ रिवर्स ट्रांसक्रिप्टेज: यह एंजाइम $RNA$ टेम्पलेट का उपयोग करके $DNA$ का संश्लेषण करता है, जिसे रिवर्स ट्रांसक्रिप्शन कहा जाता है, जो $(iv)$ से मेल खाता है।
$(d)$ $DNA$ पॉलीमरेज: यह एंजाइम मौजूदा $DNA$ टेम्पलेट का उपयोग करके एक नई $DNA$ श्रृंखला को संश्लेषित करने के लिए जिम्मेदार है, जो $(i)$ से मेल खाता है।
अतः, सही क्रम $a-iii, b-ii, c-iv, d-i$ है।
0 likes
View Solution83
MediumMCQ
निम्नलिखित स्तंभों का सही मिलान कीजिए :
| स्तंभ-$I$ | स्तंभ-$II$ | स्तंभ-$III$ |
| $(1) \ 1952$ | $(a)$ वॉटसन और क्रिक | $(i)$ $DNA$ का द्विकुंडलित मॉडल |
| $(2) \ 1928$ | $(b)$ फ्रेडरिक मिशर | $(ii)$ $DNA$ आनुवंशिक पदार्थ है, इसका प्रमाण |
| $(3) \ 1869$ | $(c)$ ग्रिफिथ | $(iii)$ न्यूक्लिन |
| $(4) \ 1953$ | $(d)$ हर्षे और चेज़ | $(iv)$ रूपांतरण सिद्धांत |
A
$1-a-ii, 2-c-iii, 3-d-i, 4-b-iv$
B
$1-c-iv, 2-d-i, 3-a-iii, 4-b-i$
C
$1-b-ii, 2-a-ii, 3-c-i, 4-d-iv$
D
$1-d-ii, 2-c-iv, 3-b-iii, 4-a-i$
Solution
(D) सही मिलान इस प्रकार है:
$1$. $1952$: हर्षे और चेज़ $(d)$ ने सिद्ध किया कि $DNA$ आनुवंशिक पदार्थ है $(ii)$.
$2$. $1928$: ग्रिफिथ $(c)$ ने रूपांतरण सिद्धांत प्रस्तावित किया $(iv)$.
$3$. $1869$: फ्रेडरिक मिशर $(b)$ ने $DNA$ की पहचान की और इसे न्यूक्लिन $(iii)$ नाम दिया।
$4$. $1953$: वॉटसन और क्रिक $(a)$ ने $DNA$ का द्विकुंडलित मॉडल प्रस्तावित किया $(i)$.
अतः, सही क्रम $1-d-ii, 2-c-iv, 3-b-iii, 4-a-i$ है।
$1$. $1952$: हर्षे और चेज़ $(d)$ ने सिद्ध किया कि $DNA$ आनुवंशिक पदार्थ है $(ii)$.
$2$. $1928$: ग्रिफिथ $(c)$ ने रूपांतरण सिद्धांत प्रस्तावित किया $(iv)$.
$3$. $1869$: फ्रेडरिक मिशर $(b)$ ने $DNA$ की पहचान की और इसे न्यूक्लिन $(iii)$ नाम दिया।
$4$. $1953$: वॉटसन और क्रिक $(a)$ ने $DNA$ का द्विकुंडलित मॉडल प्रस्तावित किया $(i)$.
अतः, सही क्रम $1-d-ii, 2-c-iv, 3-b-iii, 4-a-i$ है।
0 likes
View Solution84
EasyMCQ
निम्नलिखित स्तंभों का मिलान कीजिए:
| स्तंभ-$I$ | स्तंभ-$II$ |
| $(p)$ $AUG$ | $(a)$ ट्रांसपोसॉन्स |
| $(q)$ $UGA$ | $(b)$ जैकब और मोनोड |
| $(r)$ जंपिंग जींस | $(c)$ समापन कोडोन |
| $(s)$ ओपेरॉन मॉडल | $(d)$ मेथियोनीन |
A
$p-d, q-c, r-b, s-a$
B
$p-d, q-c, r-a, s-b$
C
$p-c, q-b, r-a, s-d$
D
$p-a, q-c, r-b, s-d$
Solution
(B) $(p) AUG$ एक प्रारंभिक कोडोन (start codon) है जो मेथियोनीन $(d)$ अमीनो एसिड के लिए कोड करता है।
$(q) UGA$ तीन समापन कोडोन (termination codons) में से एक है $(c)$।
$(r)$ जंपिंग जींस को ट्रांसपोसॉन्स $(a)$ के रूप में भी जाना जाता है।
$(s)$ ओपेरॉन मॉडल जैकब और मोनोड $(b)$ द्वारा प्रस्तावित किया गया था।
अतः, सही मिलान $p-d, q-c, r-a, s-b$ है।
$(q) UGA$ तीन समापन कोडोन (termination codons) में से एक है $(c)$।
$(r)$ जंपिंग जींस को ट्रांसपोसॉन्स $(a)$ के रूप में भी जाना जाता है।
$(s)$ ओपेरॉन मॉडल जैकब और मोनोड $(b)$ द्वारा प्रस्तावित किया गया था।
अतः, सही मिलान $p-d, q-c, r-a, s-b$ है।
0 likes
View Solution85
MediumMCQ
निम्नलिखित स्तंभों का मिलान करें :
| स्तंभ-$I$ | स्तंभ-$II$ |
| $(a)$ एक्सॉन | $(I)$ नॉन-कोडिंग अनुक्रम |
| $(b)$ इंट्रॉन | $(II)$ कोडिंग अनुक्रम |
| $(c)$ आनुवंशिक कूट | $(III)$ न्यूक्लियोसोम |
| $(d)$ $DNA$ पैकेजिंग | $(IV)$ नायरनबर्ग,खुराना और मथाई |
A
$a-II, b-I, c-IV, d-III$
B
$a-III, b-I, c-II, d-IV$
C
$a-II, b-I, c-III, d-IV$
D
$a-I, b-II, c-III, d-IV$
Solution
(A) सही मिलान इस प्रकार है:
$(a)$ एक्सॉन: ये जीन में कोडिंग अनुक्रम होते हैं जो परिपक्व $RNA$ में दिखाई देते हैं। अतः,$(a-II)$।
$(b)$ इंट्रॉन: ये नॉन-कोडिंग अनुक्रम होते हैं जिन्हें $RNA$ स्प्लिसिंग के दौरान हटा दिया जाता है। अतः,$(b-I)$।
$(c)$ आनुवंशिक कूट: आनुवंशिक कूट को डिकोड करने में नायरनबर्ग,खुराना और मथाई ने महत्वपूर्ण योगदान दिया था। अतः,$(c-IV)$।
$(d)$ $DNA$ पैकेजिंग: सुकेंद्रकी जीवों में $DNA$ न्यूक्लियोसोम नामक संरचनाओं में पैक होता है। अतः,$(d-III)$।
इसलिए,सही क्रम $a-II, b-I, c-IV, d-III$ है।
$(a)$ एक्सॉन: ये जीन में कोडिंग अनुक्रम होते हैं जो परिपक्व $RNA$ में दिखाई देते हैं। अतः,$(a-II)$।
$(b)$ इंट्रॉन: ये नॉन-कोडिंग अनुक्रम होते हैं जिन्हें $RNA$ स्प्लिसिंग के दौरान हटा दिया जाता है। अतः,$(b-I)$।
$(c)$ आनुवंशिक कूट: आनुवंशिक कूट को डिकोड करने में नायरनबर्ग,खुराना और मथाई ने महत्वपूर्ण योगदान दिया था। अतः,$(c-IV)$।
$(d)$ $DNA$ पैकेजिंग: सुकेंद्रकी जीवों में $DNA$ न्यूक्लियोसोम नामक संरचनाओं में पैक होता है। अतः,$(d-III)$।
इसलिए,सही क्रम $a-II, b-I, c-IV, d-III$ है।
0 likes
View Solution86
MediumMCQ
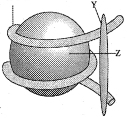
ऊपर दिखाई गई आकृति क्या दर्शाती है?
A
न्यूक्लियोइड
B
न्यूक्लियोसोम
C
क्रोमैटिन
D
हिस्टोन ऑक्टामर
Solution
(B) यह आकृति हिस्टोन प्रोटीन कोर के चारों ओर लिपटे हुए $DNA$ का एक खंड दर्शाती है। इस संरचना को न्यूक्लियोसोम के रूप में जाना जाता है।
इस आरेख में,'$Z$' हिस्टोन ऑक्टामर (आठ हिस्टोन प्रोटीन का एक समूह) को दर्शाता है,और '$Y$' '$H1$' हिस्टोन प्रोटीन को दर्शाता है जो $DNA$ के लिपटने की प्रक्रिया को स्थिर करने में मदद करता है।
इस आरेख में,'$Z$' हिस्टोन ऑक्टामर (आठ हिस्टोन प्रोटीन का एक समूह) को दर्शाता है,और '$Y$' '$H1$' हिस्टोन प्रोटीन को दर्शाता है जो $DNA$ के लिपटने की प्रक्रिया को स्थिर करने में मदद करता है।
0 likes
View Solution87
MediumMCQ
दी गई आकृति में $Y$ क्या दर्शाता है?
A
$H_1$ हिस्टोन
B
$DNA$
C
हिस्टोन ऑक्टामर
D
$H_2$ हिस्टोन
Solution
(A) दी गई आकृति एक न्यूक्लियोसोम को दर्शाती है,जो यूकेरियोट्स में $DNA$ पैकेजिंग की मूल इकाई है।
इस संरचना में,ऋणात्मक रूप से आवेशित $DNA$ एक धनात्मक रूप से आवेशित हिस्टोन ऑक्टामर (जिसे $Z$ के रूप में लेबल किया गया है) के चारों ओर लिपटा होता है।
हिस्टोन ऑक्टामर में चार हिस्टोन प्रोटीन $(H_2A, H_2B, H_3, H_4)$ के प्रत्येक के दो अणु होते हैं।
$H_1$ हिस्टोन (जिसे $Y$ के रूप में लेबल किया गया है) उस $DNA$ से जुड़ता है जहाँ यह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है,जो संरचना को स्थिर करने में मदद करता है।
इस संरचना में,ऋणात्मक रूप से आवेशित $DNA$ एक धनात्मक रूप से आवेशित हिस्टोन ऑक्टामर (जिसे $Z$ के रूप में लेबल किया गया है) के चारों ओर लिपटा होता है।
हिस्टोन ऑक्टामर में चार हिस्टोन प्रोटीन $(H_2A, H_2B, H_3, H_4)$ के प्रत्येक के दो अणु होते हैं।
$H_1$ हिस्टोन (जिसे $Y$ के रूप में लेबल किया गया है) उस $DNA$ से जुड़ता है जहाँ यह न्यूक्लियोसोम में प्रवेश करता है और बाहर निकलता है,जो संरचना को स्थिर करने में मदद करता है।
0 likes
View Solution88
MediumMCQ
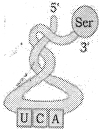
चित्र में दिखाई गई संरचना को पहचानें।
A
$m-RNA$
B
$r-RNA$
C
$t-RNA$
D
$DNA$
Solution
(C) यह चित्र $t-RNA$ (ट्रांसफर $RNA$) के क्लोवर-लीफ मॉडल को दर्शाता है।
इसमें $5'$ और $3'$ सिरे,एक अमीनो एसिड अटैचमेंट साइट (जो सेरीन,$Ser$ ले जा रहा है),और $UCA$ अनुक्रम वाला एक एंटीकोडोन लूप दिखाई देता है।
इसमें $5'$ और $3'$ सिरे,एक अमीनो एसिड अटैचमेंट साइट (जो सेरीन,$Ser$ ले जा रहा है),और $UCA$ अनुक्रम वाला एक एंटीकोडोन लूप दिखाई देता है।
0 likes
View Solution89
EasyMCQ
एक जनक से इकाई के रूप में विरासत में मिले गुणसूत्रों या कोशिका जीनों के पूर्ण सेट को क्या कहा जाता है?
A
जीनोम (Genome)
B
जीनोटाइप (Genotype)
C
कैरियोटाइप (Karyotype)
D
गुणसूत्र (Chromosomes)
Solution
(A) सही उत्तर जीनोम (Genome) है।
गुणसूत्रों के एक पूर्ण सेट या युग्मक (gamete) में मौजूद गुणसूत्रों की अगुणित संख्या को जीनोम कहा जाता है। यह एक जनक से युग्मक के माध्यम से विरासत में प्राप्त संपूर्ण आनुवंशिक सामग्री का प्रतिनिधित्व करता है।
गुणसूत्रों के एक पूर्ण सेट या युग्मक (gamete) में मौजूद गुणसूत्रों की अगुणित संख्या को जीनोम कहा जाता है। यह एक जनक से युग्मक के माध्यम से विरासत में प्राप्त संपूर्ण आनुवंशिक सामग्री का प्रतिनिधित्व करता है।
0 likes
View Solution90
MediumMCQ
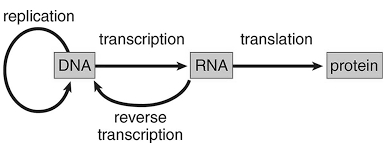
आधुनिक जीव विज्ञान में सूचना का प्रवाह या सेंट्रल डोग्मा (Central Dogma) क्या है?
A
$RNA \rightarrow Proteins \rightarrow DNA$
B
$DNA \rightarrow RNA \rightarrow RNA$
C
$RNA \rightarrow DNA \rightarrow Proteins$
D
$DNA \rightarrow RNA \rightarrow Proteins$
Solution
(D) 'सेंट्रल डोग्मा' शब्द फ्रांसिस क्रिक द्वारा $1958$ में प्रस्तावित किया गया था। यह आनुवंशिक सूचना के $DNA$ से $RNA$ और फिर प्रोटीन (पॉलीपेप्टाइड) की ओर एकदिशीय प्रवाह का वर्णन करता है। $DNA$ से $RNA$ बनने की प्रक्रिया को ट्रांसक्रिप्शन (अनुलेखन) कहा जाता है,और $RNA$ से प्रोटीन बनने की प्रक्रिया को ट्रांसलेशन (अनुवादन) कहा जाता है।
0 likes
View Solution91
MediumMCQ
दिए गए कथनों $(i-iv)$ में से कितने कथन सही हैं?
$i.$ अनुलेखन (transcription) में,एडेनोसिन यूरेसिल के साथ जुड़ता है।
$ii.$ रिप्रेसर द्वारा लैक ओपेरॉन का विनियमन धनात्मक विनियमन कहलाता है।
$iii.$ मानव जीनोम में लगभग $50,000$ जीन होते हैं।
$iv.$ हीमोफिलिया एक लिंग-सहलग्न अप्रभावी रोग है।
$i.$ अनुलेखन (transcription) में,एडेनोसिन यूरेसिल के साथ जुड़ता है।
$ii.$ रिप्रेसर द्वारा लैक ओपेरॉन का विनियमन धनात्मक विनियमन कहलाता है।
$iii.$ मानव जीनोम में लगभग $50,000$ जीन होते हैं।
$iv.$ हीमोफिलिया एक लिंग-सहलग्न अप्रभावी रोग है।
A
दो
B
तीन
C
चार
D
एक
Solution
(A) कथन $(i)$ सही है: अनुलेखन के दौरान,$RNA$ में एडेनोसिन $(A)$ यूरेसिल $(U)$ के साथ जुड़ता है।
कथन $(ii)$ गलत है: रिप्रेसर द्वारा लैक ओपेरॉन का विनियमन ऋणात्मक विनियमन कहलाता है,क्योंकि रिप्रेसर प्रोटीन अनुलेखन को रोकने के लिए ऑपरेटर से जुड़ता है।
कथन $(iii)$ गलत है: मानव जीनोम में लगभग $20,000-25,000$ जीन होते हैं,न कि $50,000$।
कथन $(iv)$ सही है: हीमोफिलिया एक ज्ञात लिंग-सहलग्न अप्रभावी विकार है।
अतः,कथन $(i)$ और $(iv)$ सही हैं। सही कथनों की कुल संख्या $2$ है।
कथन $(ii)$ गलत है: रिप्रेसर द्वारा लैक ओपेरॉन का विनियमन ऋणात्मक विनियमन कहलाता है,क्योंकि रिप्रेसर प्रोटीन अनुलेखन को रोकने के लिए ऑपरेटर से जुड़ता है।
कथन $(iii)$ गलत है: मानव जीनोम में लगभग $20,000-25,000$ जीन होते हैं,न कि $50,000$।
कथन $(iv)$ सही है: हीमोफिलिया एक ज्ञात लिंग-सहलग्न अप्रभावी विकार है।
अतः,कथन $(i)$ और $(iv)$ सही हैं। सही कथनों की कुल संख्या $2$ है।
0 likes
View Solution92
MediumMCQ
जीन के भीतर न्यूक्लियोटाइड अनुक्रम को बदलने वाले उत्परिवर्तन को क्या कहा जाता है?
A
फ्रेम-शिफ्ट उत्परिवर्तन
B
बेस पेयर प्रतिस्थापन
C
$(a)$ और $(b)$ दोनों
D
इनमें से कोई नहीं
Solution
(C) फ्रेम-शिफ्ट उत्परिवर्तन में,बेस अनुक्रम का रीडिंग फ्रेम एक या अधिक न्यूक्लियोटाइड के जुड़ने के कारण आगे की दिशा में या एक या अधिक न्यूक्लियोटाइड के विलोपन के कारण पीछे की दिशा में खिसक जाता है।
बेस पेयर प्रतिस्थापन में,एक बेस पेयर को दूसरे बेस द्वारा बदल दिया जाता है,जिसके परिणामस्वरूप न्यूक्लियोटाइड अनुक्रम में परिवर्तन होता है।
चूंकि ये दोनों प्रक्रियाएं जीन के भीतर न्यूक्लियोटाइड अनुक्रम को बदलती हैं,इसलिए सही उत्तर $(a)$ और $(b)$ दोनों है।
बेस पेयर प्रतिस्थापन में,एक बेस पेयर को दूसरे बेस द्वारा बदल दिया जाता है,जिसके परिणामस्वरूप न्यूक्लियोटाइड अनुक्रम में परिवर्तन होता है।
चूंकि ये दोनों प्रक्रियाएं जीन के भीतर न्यूक्लियोटाइड अनुक्रम को बदलती हैं,इसलिए सही उत्तर $(a)$ और $(b)$ दोनों है।
0 likes
View Solution93
MediumMCQ
सही मिलान को चिह्नित करें।
A
बैक्टीरिया में उत्प्रेरक $RNA$ - $16S$ $rRNA$ और $23S$ $rRNA$ राइबोजाइम के रूप में।
B
$Val$ ओपेरॉन - यूकेरियोट्स में पाया जाता है।
C
सेंगर विधि - केवल प्रोटीन में अमीनो एसिड अनुक्रम का निर्धारण।
D
$VNTR$ - इंट्रॉन।
Solution
(A) $16S$ $rRNA$ और $23S$ $rRNA$ बैक्टीरियल राइबोसोम के घटक हैं। विशेष रूप से,$23S$ $rRNA$ बैक्टीरिया में राइबोजाइम (पेप्टिडिल ट्रांसफरेज) के रूप में कार्य करता है,जो प्रोटीन संश्लेषण के दौरान पेप्टाइड बॉन्ड के निर्माण को उत्प्रेरित करता है।
$Val$ ओपेरॉन मौजूद नहीं होता है; ओपेरॉन प्रोकैरियोट्स की विशेषता है,यूकेरियोट्स की नहीं।
सेंगर विधि का उपयोग मुख्य रूप से $DNA$ अनुक्रमण के लिए किया जाता है,न कि प्रोटीन अनुक्रमण के लिए।
$VNTR$ का अर्थ 'वेरिएबल नंबर टैंडम रिपीट्स' है,जो जीनोम में पाए जाने वाले दोहराव वाले $DNA$ अनुक्रम हैं,न कि विशेष रूप से इंट्रॉन।
$Val$ ओपेरॉन मौजूद नहीं होता है; ओपेरॉन प्रोकैरियोट्स की विशेषता है,यूकेरियोट्स की नहीं।
सेंगर विधि का उपयोग मुख्य रूप से $DNA$ अनुक्रमण के लिए किया जाता है,न कि प्रोटीन अनुक्रमण के लिए।
$VNTR$ का अर्थ 'वेरिएबल नंबर टैंडम रिपीट्स' है,जो जीनोम में पाए जाने वाले दोहराव वाले $DNA$ अनुक्रम हैं,न कि विशेष रूप से इंट्रॉन।
0 likes
View Solution94
MediumMCQ
$A$ : $5S$ $rRNA$ और आसपास का प्रोटीन कॉम्प्लेक्स $tRNA$ के लिए बाइंडिंग साइट प्रदान करता है।
$R$ : $tRNA$ असामान्य बेस वाला घुलनशील $RNA$ है।
$R$ : $tRNA$ असामान्य बेस वाला घुलनशील $RNA$ है।
A
अभिकथन और कारण दोनों सही हैं और कारण अभिकथन की सही व्याख्या है।
B
अभिकथन और कारण दोनों सही हैं लेकिन कारण अभिकथन की सही व्याख्या नहीं है।
C
अभिकथन सही है,लेकिन कारण गलत है।
D
अभिकथन और कारण दोनों गलत हैं।
Solution
(C) अभिकथन गलत है क्योंकि $5S$ $rRNA$ बड़े राइबोसोमल सबयूनिट (यूकेरियोट्स में $60S$ या प्रोकैरियोट्स में $50S$) का एक घटक है,लेकिन यह विशेष रूप से $tRNA$ के लिए बाइंडिंग साइट प्रदान नहीं करता है। $tRNA$ बाइंडिंग साइट्स ($A$,$P$,और $E$ साइट्स) राइबोसोम के भीतर $rRNA$ और राइबोसोमल प्रोटीन की जटिल संरचना द्वारा बनती हैं,न कि केवल $5S$ $rRNA$ द्वारा।
कारण सही है। $tRNA$ (ट्रांसफर $RNA$) को वास्तव में घुलनशील $RNA$ $(sRNA)$ के रूप में जाना जाता है क्योंकि यह सेंट्रीफ्यूजेशन के बाद सुपरनेटेंट में रहता है। इसमें स्यूडोयूरिडिन,डाइहाइड्रॉयूरिडिन और मिथाइलगुआनोसिन जैसे असामान्य या संशोधित बेस होते हैं,जो इसकी संरचना की विशेषता हैं।
कारण सही है। $tRNA$ (ट्रांसफर $RNA$) को वास्तव में घुलनशील $RNA$ $(sRNA)$ के रूप में जाना जाता है क्योंकि यह सेंट्रीफ्यूजेशन के बाद सुपरनेटेंट में रहता है। इसमें स्यूडोयूरिडिन,डाइहाइड्रॉयूरिडिन और मिथाइलगुआनोसिन जैसे असामान्य या संशोधित बेस होते हैं,जो इसकी संरचना की विशेषता हैं।
0 likes
View Solution95
MediumMCQ
$A$: टेमिनिज़्म सूचना का एकदिशीय प्रवाह है।
$R$: इसके लिए $DNA$-निर्भर $RNA$ पॉलीमरेज़ एंजाइम की आवश्यकता होती है।
$R$: इसके लिए $DNA$-निर्भर $RNA$ पॉलीमरेज़ एंजाइम की आवश्यकता होती है।
A
अभिकथन और कारण दोनों सही हैं और कारण अभिकथन की सही व्याख्या है।
B
अभिकथन और कारण दोनों सही हैं लेकिन कारण अभिकथन की सही व्याख्या नहीं है।
C
अभिकथन सही है,लेकिन कारण गलत है।
D
अभिकथन और कारण दोनों गलत हैं।
Solution
(D) टेमिनिज़्म,जिसे रिवर्स ट्रांसक्रिप्शन के रूप में भी जाना जाता है,$RNA$ टेम्पलेट से $DNA$ के संश्लेषण को संदर्भित करता है। यह प्रक्रिया रिवर्स ट्रांसक्रिप्टेज़ ($RNA$-निर्भर $DNA$ पॉलीमरेज़) एंजाइम द्वारा उत्प्रेरित होती है,न कि $DNA$-निर्भर $RNA$ पॉलीमरेज़ द्वारा।
चूंकि टेमिनिज़्म में सूचना का प्रवाह $RNA$ से $DNA$ की ओर होता है,यह सेंट्रल डोग्मा के एकदिशीय प्रवाह $(DNA \rightarrow RNA \rightarrow Protein)$ की अवधारणा का खंडन करता है।
इसलिए,अभिकथन गलत है क्योंकि टेमिनिज़्म मानक एकदिशीय प्रवाह से विचलन का प्रतिनिधित्व करता है,और कारण भी गलत है क्योंकि इसमें गलत एंजाइम का उल्लेख किया गया है।
चूंकि टेमिनिज़्म में सूचना का प्रवाह $RNA$ से $DNA$ की ओर होता है,यह सेंट्रल डोग्मा के एकदिशीय प्रवाह $(DNA \rightarrow RNA \rightarrow Protein)$ की अवधारणा का खंडन करता है।
इसलिए,अभिकथन गलत है क्योंकि टेमिनिज़्म मानक एकदिशीय प्रवाह से विचलन का प्रतिनिधित्व करता है,और कारण भी गलत है क्योंकि इसमें गलत एंजाइम का उल्लेख किया गया है।
0 likes
View Solution96
MediumMCQ
मूल सिद्धान्त (सेन्ट्रल डोग्मा) का पूर्ण प्रवाह चित्र है:
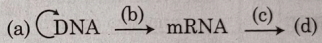
A
$(a)-$प्रतिकृतिकरण (Replication); $(b)-$अनुलेखन (Transcription); $(c)-$अनुवादन (Translation); $(d)-$प्रोटीन
B
$(a)-$रूपांतरण (Transformation); $(b)-$प्रतिकृतिकरण; $(c)-$अनुलेखन; $(d)-$अनुवादन
C
$(a)-$प्रतिकृतिकरण; $(b)-$अनुलेखन; $(c)-$रूपांतरण; $(d)-$प्रोटीन
D
$(a)-$अनुवादन; $(b)-$रूपांतरण; $(c)-$प्रतिकृतिकरण; $(d)-$प्रोटीन
Solution
(A) आण्विक जीवविज्ञान का सेन्ट्रल डोग्मा एक जैविक प्रणाली के भीतर आनुवंशिक जानकारी के प्रवाह का वर्णन करता है।
$1$. $(a)$ प्रतिकृतिकरण (Replication) को दर्शाता है,जहाँ $DNA$ अपनी स्वयं की प्रतिलिपि बनाता है।
$2$. $(b)$ अनुलेखन (Transcription) को दर्शाता है,जहाँ $DNA$ का उपयोग $mRNA$ को संश्लेषित करने के लिए किया जाता है।
$3$. $(c)$ अनुवादन (Translation) को दर्शाता है,जहाँ $mRNA$ का उपयोग पॉलीपेप्टाइड श्रृंखला या प्रोटीन $(d)$ को संश्लेषित करने के लिए किया जाता है।
अतः,सही क्रम $(a)-$प्रतिकृतिकरण,$(b)-$अनुलेखन,$(c)-$अनुवादन,$(d)-$प्रोटीन है।
$1$. $(a)$ प्रतिकृतिकरण (Replication) को दर्शाता है,जहाँ $DNA$ अपनी स्वयं की प्रतिलिपि बनाता है।
$2$. $(b)$ अनुलेखन (Transcription) को दर्शाता है,जहाँ $DNA$ का उपयोग $mRNA$ को संश्लेषित करने के लिए किया जाता है।
$3$. $(c)$ अनुवादन (Translation) को दर्शाता है,जहाँ $mRNA$ का उपयोग पॉलीपेप्टाइड श्रृंखला या प्रोटीन $(d)$ को संश्लेषित करने के लिए किया जाता है।
अतः,सही क्रम $(a)-$प्रतिकृतिकरण,$(b)-$अनुलेखन,$(c)-$अनुवादन,$(d)-$प्रोटीन है।
0 likes
View Solution97
MediumMCQ
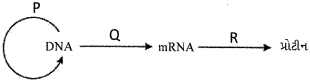
आणविक जीवविज्ञान का केंद्रीय सिद्धांत (Central Dogma) नीचे दर्शाया गया है। प्रक्रियाओं $P, Q$ और $R$ की पहचान करें।
A
$P$: प्रतिकृति (Replication),$Q$: अनुलेखन (Transcription),$R$: स्थानांतरण (Translation)
B
$P$: प्रतिकृति,$Q$: स्थानांतरण,$R$: अनुलेखन
C
$P$: स्थानांतरण,$Q$: प्रतिकृति,$R$: अनुलेखन
D
$P$: अनुलेखन,$Q$: स्थानांतरण,$R$: प्रतिकृति
Solution
(A) आणविक जीवविज्ञान का केंद्रीय सिद्धांत जैविक तंत्र में आनुवंशिक सूचनाओं के प्रवाह को दर्शाता है।
$1$. $P$ उस प्रक्रिया को दर्शाता है जिसमें $DNA$ अपनी प्रतिलिपि बनाता है,जिसे प्रतिकृति (Replication) कहा जाता है।
$2$. $Q$ उस प्रक्रिया को दर्शाता है जिसमें $DNA$ का उपयोग $mRNA$ के संश्लेषण के लिए किया जाता है,जिसे अनुलेखन (Transcription) कहा जाता है।
$3$. $R$ उस प्रक्रिया को दर्शाता है जिसमें $mRNA$ का उपयोग प्रोटीन बनाने के लिए किया जाता है,जिसे स्थानांतरण (Translation) कहा जाता है।
अतः,सही क्रम $P$: प्रतिकृति,$Q$: अनुलेखन,$R$: स्थानांतरण है।
$1$. $P$ उस प्रक्रिया को दर्शाता है जिसमें $DNA$ अपनी प्रतिलिपि बनाता है,जिसे प्रतिकृति (Replication) कहा जाता है।
$2$. $Q$ उस प्रक्रिया को दर्शाता है जिसमें $DNA$ का उपयोग $mRNA$ के संश्लेषण के लिए किया जाता है,जिसे अनुलेखन (Transcription) कहा जाता है।
$3$. $R$ उस प्रक्रिया को दर्शाता है जिसमें $mRNA$ का उपयोग प्रोटीन बनाने के लिए किया जाता है,जिसे स्थानांतरण (Translation) कहा जाता है।
अतः,सही क्रम $P$: प्रतिकृति,$Q$: अनुलेखन,$R$: स्थानांतरण है।
0 likes
View Solution98
MediumMCQ
प्रोटीन संश्लेषण के लिए $P$ सीधे संकेत कर सकता है,जबकि $Q$ के प्रत्येक न्यूक्लियोटाइड की शर्करा में $2'-OH$ समूह होता है। $P$ और $Q$ की पहचान करें।
$\quad\quad P\quad Q$
$\quad\quad P\quad Q$
A
$RNA\quad RNA$
B
$RNA \quad DNA$
C
$DNA \quad RNA$
D
$DNA \quad DNA$
Solution
(A) $1$. प्रोटीन संश्लेषण की प्रक्रिया में,$mRNA$ (मैसेंजर $RNA$) सीधे टेम्पलेट के रूप में कार्य करता है जो अमीनो एसिड के अनुवाद (translation) के लिए आनुवंशिक कोड ले जाता है।
$2$. $RNA$ न्यूक्लियोटाइड का शर्करा घटक राइबोज है,जिसमें शर्करा वलय के $2'$ स्थान पर हाइड्रॉक्सिल समूह $(-OH)$ होता है।
$3$. इसके विपरीत,$DNA$ में डीऑक्सीराइबोज शर्करा होती है,जिसमें $2'-OH$ समूह का अभाव होता है (इसमें $2'$ स्थान पर केवल एक हाइड्रोजन परमाणु होता है)।
$4$. इसलिए,$P$ का मान $RNA$ है और $Q$ का मान $RNA$ है।
$2$. $RNA$ न्यूक्लियोटाइड का शर्करा घटक राइबोज है,जिसमें शर्करा वलय के $2'$ स्थान पर हाइड्रॉक्सिल समूह $(-OH)$ होता है।
$3$. इसके विपरीत,$DNA$ में डीऑक्सीराइबोज शर्करा होती है,जिसमें $2'-OH$ समूह का अभाव होता है (इसमें $2'$ स्थान पर केवल एक हाइड्रोजन परमाणु होता है)।
$4$. इसलिए,$P$ का मान $RNA$ है और $Q$ का मान $RNA$ है।
0 likes
View Solution99
MediumMCQ
निम्नलिखित में से कितने कथन सही हैं?
$I - DNA$ से $RNA$ का निर्माण अनुलेखन (transcription) की प्रक्रिया द्वारा होता है।
$II - DNA$,$RNA$ की तुलना में अधिक स्थिर है।
$III - RNA$ कुछ जैव रासायनिक अभिक्रियाओं में उत्प्रेरक (एंजाइम) के रूप में कार्य करता है।
$IV - DNA$ अपनी द्विकुंडलित संरचना और पूरक रज्जुओं की उपस्थिति के कारण उत्परिवर्तन (mutations) के प्रति प्रतिरोधी है,जो मरम्मत तंत्र के लिए आधार प्रदान करते हैं।
$I - DNA$ से $RNA$ का निर्माण अनुलेखन (transcription) की प्रक्रिया द्वारा होता है।
$II - DNA$,$RNA$ की तुलना में अधिक स्थिर है।
$III - RNA$ कुछ जैव रासायनिक अभिक्रियाओं में उत्प्रेरक (एंजाइम) के रूप में कार्य करता है।
$IV - DNA$ अपनी द्विकुंडलित संरचना और पूरक रज्जुओं की उपस्थिति के कारण उत्परिवर्तन (mutations) के प्रति प्रतिरोधी है,जो मरम्मत तंत्र के लिए आधार प्रदान करते हैं।
A
$1$
B
$2$
C
$3$
D
$4$
Solution
(D) कथन $I$ सही है: $RNA$ का संश्लेषण $DNA$ से अनुलेखन प्रक्रिया के माध्यम से होता है।
कथन $II$ सही है: $DNA$,$RNA$ से अधिक स्थिर है क्योंकि $RNA$ में राइबोज शर्करा पर $2'-OH$ समूह होता है,जो इसे अधिक प्रतिक्रियाशील और जल-अपघटन के प्रति संवेदनशील बनाता है।
कथन $III$ सही है: $RNA$ कुछ जैव रासायनिक अभिक्रियाओं में उत्प्रेरक (राइबोजाइम) के रूप में कार्य कर सकता है,जैसे कि प्रोटीन संश्लेषण के दौरान राइबोसोम में।
कथन $IV$ सही है: $DNA$ अपनी द्विकुंडलित संरचना और पूरक रज्जुओं की उपस्थिति के कारण उत्परिवर्तन के प्रति अधिक स्थिर और प्रतिरोधी है,जो मरम्मत तंत्र के लिए एक टेम्पलेट प्रदान करते हैं।
चूंकि चारों कथन सही हैं,इसलिए सही उत्तर $4$ है।
कथन $II$ सही है: $DNA$,$RNA$ से अधिक स्थिर है क्योंकि $RNA$ में राइबोज शर्करा पर $2'-OH$ समूह होता है,जो इसे अधिक प्रतिक्रियाशील और जल-अपघटन के प्रति संवेदनशील बनाता है।
कथन $III$ सही है: $RNA$ कुछ जैव रासायनिक अभिक्रियाओं में उत्प्रेरक (राइबोजाइम) के रूप में कार्य कर सकता है,जैसे कि प्रोटीन संश्लेषण के दौरान राइबोसोम में।
कथन $IV$ सही है: $DNA$ अपनी द्विकुंडलित संरचना और पूरक रज्जुओं की उपस्थिति के कारण उत्परिवर्तन के प्रति अधिक स्थिर और प्रतिरोधी है,जो मरम्मत तंत्र के लिए एक टेम्पलेट प्रदान करते हैं।
चूंकि चारों कथन सही हैं,इसलिए सही उत्तर $4$ है।
0 likes
View Solution100
MediumMCQ
निम्नलिखित में से सही कथन का चयन करें।
A
सभी जीवित जीवों में आनुवंशिक पदार्थ न्यूक्लिक एसिड होता है।
B
$DNA$ को काटने के लिए उसे शुद्ध रूप में होना चाहिए।
C
$DNA$ की संरचना में चार प्रकार के न्यूक्लियोटाइड होते हैं।
D
उपरोक्त सभी।
Solution
(D) $1$. सभी जीवित जीवों में न्यूक्लिक एसिड ($DNA$ या $RNA$) आनुवंशिक पदार्थ के रूप में कार्य करते हैं।
$2$. रिकॉम्बिनेंट $DNA$ तकनीक में,रिस्ट्रिक्शन एंडोन्यूक्लिएज द्वारा $DNA$ को प्रभावी ढंग से काटने के लिए,इसे प्रोटीन,$RNA$,पॉलीसैकराइड और लिपिड जैसे अन्य मैक्रोमोलेक्यूल्स से मुक्त और शुद्ध रूप में होना आवश्यक है।
$3$. $DNA$ अणु चार प्रकार के न्यूक्लियोटाइड से बना होता है,जो उनके नाइट्रोजनस बेस ($Adenine$,$Guanine$,$Cytosine$,और $Thymine$) के आधार पर भिन्न होते हैं।
चूंकि दिए गए सभी कथन वैज्ञानिक रूप से सही हैं,इसलिए सही विकल्प $D$ है।
$2$. रिकॉम्बिनेंट $DNA$ तकनीक में,रिस्ट्रिक्शन एंडोन्यूक्लिएज द्वारा $DNA$ को प्रभावी ढंग से काटने के लिए,इसे प्रोटीन,$RNA$,पॉलीसैकराइड और लिपिड जैसे अन्य मैक्रोमोलेक्यूल्स से मुक्त और शुद्ध रूप में होना आवश्यक है।
$3$. $DNA$ अणु चार प्रकार के न्यूक्लियोटाइड से बना होता है,जो उनके नाइट्रोजनस बेस ($Adenine$,$Guanine$,$Cytosine$,और $Thymine$) के आधार पर भिन्न होते हैं।
चूंकि दिए गए सभी कथन वैज्ञानिक रूप से सही हैं,इसलिए सही विकल्प $D$ है।
0 likes
View SolutionMolecular Basis of Inheritance — Mix Example-Molecular Basis of Inheritance · Frequently Asked Questions
1Are these Molecular Basis of Inheritance questions useful for JEE and NEET?
Yes. All questions in this section are mapped to JEE Main and NEET exam patterns. Previous year questions from JEE Main, NEET, GUJCET and state-level exams are included with full solutions.
2Can I switch to Hindi or Gujarati for these questions?
Yes. Use the language tabs in the hero section or the sidebar to view the same questions and solutions in English, Hindi or Gujarati.
3How do I generate a question paper from this subtopic?
Use the Vedclass Exam Paper Generator — select the chapter and subtopic, set difficulty, and generate Sets A, B, C, D automatically. First 3 chapters of every subject are free.
Vedclass Products
For Students
Vedclass Test Series
Mock tests in real JEE/NEET style with performance analysis. 5-day free trial.
Start Free TrialFor Teachers
Exam Paper Generator
Generate Set A/B/C/D papers from this chapter in 2 minutes. 3 chapters free.
Try FreeFor Institutes
Online Exam Module
Live online exams with unlimited students, 360° analytics & white-label branding.
See DemoFor Teachers & Institutes
Generate a Molecular Basis of Inheritance Exam Paper in 2 Minutes
Select subtopic & difficulty — Sets A, B, C, D auto-generated with No Repeat logic.
First 3 chapters of every subject are free — no payment required.