
A English
Human Genome Project Questions in English
Class 12 Biology · Molecular Basis of Inheritance · Human Genome Project
98+
Questions
English
Language
100%
With Solutions
Showing 49 of 98 questions in English
1
EasyMCQ
Chromosomes of all races of human are
A
Different
B
Similar
C
Different in banding only
D
Similar in banding only
Solution
(B) All human beings belong to the same species,$Homo$ $sapiens$.
Genetic studies have shown that the chromosomal structure,number,and banding patterns are fundamentally the same across all human races.
While there is minor genetic variation (polymorphism) between individuals,the basic chromosomal organization is conserved in all human populations.
Genetic studies have shown that the chromosomal structure,number,and banding patterns are fundamentally the same across all human races.
While there is minor genetic variation (polymorphism) between individuals,the basic chromosomal organization is conserved in all human populations.
0 likes
View Solution2
EasyMCQ
The number of genes in $E. coli$ is approximately:
A
$4000$
B
$6000$
C
$10000$
D
$18000$
Solution
(A) The genome of $E. coli$ $(Escherichia coli)$ consists of approximately $4.6 \times 10^6$ base pairs. Based on genomic sequencing and analysis,it is estimated to contain about $4000$ to $4500$ genes. Therefore,$4000$ is the closest approximation among the given options.
0 likes
View Solution3
EasyMCQ
The total number of nitrogenous bases in the human genome is estimated to be about:
A
$3.5$ million
B
$35$ thousand
C
$35$ million
D
$3.1$ billion
Solution
(D) The human genome contains approximately $3.1647$ billion nucleotide base pairs. According to the Human Genome Project,the total number of nitrogenous bases is estimated to be about $3.1$ billion.
0 likes
View Solution4
MediumMCQ
The number of base pairs in the human genome is approximately .....
A
$3 \times 10^9$
B
$3 \times 10^7$
C
$6 \times 10^8$
D
$6 \times 10^7$
Solution
(A) The human genome consists of approximately $3.3 \times 10^9$ base pairs. Among the given options,$3 \times 10^9$ is the closest and most widely accepted value used in standard biological contexts to represent the haploid human genome size.
0 likes
View Solution5
MediumMCQ
What was the estimated number of genes in the human genome (in $,000$)?
A
$40$
B
$30$
C
$80$
D
$100$
Solution
(B) The Human Genome Project $(HGP)$ revealed that the human genome contains approximately $3.1647$ billion nucleotide bases.
Based on the findings of the project,the total number of genes in the human genome is estimated to be approximately $30,000$.
Based on the findings of the project,the total number of genes in the human genome is estimated to be approximately $30,000$.
0 likes
View Solution6
MediumMCQ
Which of the following is not associated with the $HGP$?
A
Bioinformatics
B
$BAC$ and $YAC$ cloning vectors
C
Automated $DNA$ sequencers
D
$VNTR$
Solution
(D) The $Human$ $Genome$ $Project$ $(HGP)$ involved several methodologies and technologies to sequence the human genome.
$1$. Bioinformatics was essential for storing,retrieving,and analyzing the vast amount of data generated.
$2$. $BAC$ ($Bacterial$ $Artificial$ $Chromosome$) and $YAC$ ($Yeast$ $Artificial$ $Chromosome$) were used as cloning vectors to store large fragments of human $DNA$.
$3$. Automated $DNA$ sequencers were used to determine the order of nucleotides in the $DNA$ fragments.
$4$. $VNTR$ ($Variable$ $Number$ $Tandem$ $Repeats$) is a technique primarily associated with $DNA$ fingerprinting,not the primary sequencing methodology of the $HGP$.
$1$. Bioinformatics was essential for storing,retrieving,and analyzing the vast amount of data generated.
$2$. $BAC$ ($Bacterial$ $Artificial$ $Chromosome$) and $YAC$ ($Yeast$ $Artificial$ $Chromosome$) were used as cloning vectors to store large fragments of human $DNA$.
$3$. Automated $DNA$ sequencers were used to determine the order of nucleotides in the $DNA$ fragments.
$4$. $VNTR$ ($Variable$ $Number$ $Tandem$ $Repeats$) is a technique primarily associated with $DNA$ fingerprinting,not the primary sequencing methodology of the $HGP$.
0 likes
View Solution7
MediumMCQ
The number of nitrogenous bases in the human genome is approximately ...... .
A
$3.5$ million
B
$35$ thousand
C
$35$ million
D
$3.1$ billion
Solution
(D) The human genome consists of approximately $3.1647$ billion nucleotide base pairs. Therefore,the number of nitrogenous bases is approximately $3.1$ billion. This was a key finding of the Human Genome Project $(HGP)$.
0 likes
View Solution8
MediumMCQ
Which of the following is not a salient feature of the human genome?
A
Human genome contains $3164.7$ million nucleotide bases.
B
The functions are unknown for over $50$ percent of the discovered genes.
C
More than $2$ percent of the genome codes for proteins.
D
Chromosome $1$ has the most genes and the $Y$ chromosome has the fewest.
Solution
(C) The salient features of the human genome are as follows:
$1$. The human genome contains $3164.7$ million nucleotide bases.
$2$. The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$3$. The total number of genes is estimated at $30,000$,much lower than previous estimates of $80,000$ to $140,000$.
$4$. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$5$. The functions are unknown for over $50$ percent of the discovered genes.
$6$. Less than $2$ percent of the genome codes for proteins.
$7$. Chromosome $1$ has the most genes $(2968)$,and the $Y$ chromosome has the fewest $(231)$.
Therefore,the statement 'More than $2$ percent of the genome codes for proteins' is incorrect,as the actual value is less than $2$ percent.
$1$. The human genome contains $3164.7$ million nucleotide bases.
$2$. The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$3$. The total number of genes is estimated at $30,000$,much lower than previous estimates of $80,000$ to $140,000$.
$4$. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$5$. The functions are unknown for over $50$ percent of the discovered genes.
$6$. Less than $2$ percent of the genome codes for proteins.
$7$. Chromosome $1$ has the most genes $(2968)$,and the $Y$ chromosome has the fewest $(231)$.
Therefore,the statement 'More than $2$ percent of the genome codes for proteins' is incorrect,as the actual value is less than $2$ percent.
0 likes
View Solution9
MediumMCQ
The dystrophin gene has ...... bases.
A
$3164.7$ million
B
$3000$ million
C
$2.4$ million
D
$2968$ million
Solution
(C) The dystrophin gene is the largest known human gene.
It consists of approximately $2.4$ million base pairs.
This gene is located on the $X$ chromosome and its mutation leads to Duchenne muscular dystrophy.
It consists of approximately $2.4$ million base pairs.
This gene is located on the $X$ chromosome and its mutation leads to Duchenne muscular dystrophy.
0 likes
View Solution10
MediumMCQ
Dystrophin contains how many million bases?
A
$2.4$
B
$5.4$
C
$2.1$
D
$2.6$
Solution
(A) The human genome project revealed that the gene for dystrophin is the largest known human gene.
It contains approximately $2.4$ million bases.
Therefore,the correct option is $A$.
It contains approximately $2.4$ million bases.
Therefore,the correct option is $A$.
0 likes
View Solution11
MediumMCQ
Chromosome $1$ has the most genes,while chromosome $Y$ has the fewest. Identify the correct number of genes present on these chromosomes respectively.
A
$2968, 231$
B
$2768, 236$
C
$2163, 336$
D
$1753, 721$
Solution
(A) According to the findings of the Human Genome Project $(HGP)$,chromosome $1$ is the largest human chromosome and contains the highest number of genes,which is $2968$.
Chromosome $Y$ is the smallest human chromosome and contains the lowest number of genes,which is $231$.
Therefore,the correct pair is $2968$ and $231$.
Chromosome $Y$ is the smallest human chromosome and contains the lowest number of genes,which is $231$.
Therefore,the correct pair is $2968$ and $231$.
0 likes
View Solution12
MediumMCQ
Which vectors are commonly used in the sequencing of the human genome?
A
$T-DNA$
B
$BAC$ and $YAC$
C
Expression vectors
D
$T/A$ cloning vectors
Solution
(B) The Human Genome Project $(HGP)$ involved the sequencing of the entire human genome. Due to the large size of the human genome,specialized vectors were required to clone large fragments of $DNA$. The most commonly used vectors were $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes). These vectors are capable of carrying large inserts of $DNA$,which facilitated the mapping and sequencing process.
0 likes
View Solution13
MediumMCQ
Expressed Sequence Tags $(ESTs)$ refers to:
A
Genes expressed as $RNA$
B
Polypeptide expression
C
$DNA$ polymorphism
D
Novel $DNA$ sequences
Solution
(A) Expressed Sequence Tags $(ESTs)$ are a strategy used in the Human Genome Project to identify all the genes that are expressed as $RNA$.
These are short sequences of $cDNA$ (complementary $DNA$) that are generated by sequencing either one or both ends of an expressed gene transcript.
Since they represent the parts of the genome that are actively transcribed into $RNA$,they serve as a useful tool for gene discovery and mapping.
These are short sequences of $cDNA$ (complementary $DNA$) that are generated by sequencing either one or both ends of an expressed gene transcript.
Since they represent the parts of the genome that are actively transcribed into $RNA$,they serve as a useful tool for gene discovery and mapping.
0 likes
View Solution14
MediumMCQ
The Human Genome Project $(HGP)$ is closely associated with the rapid development of a new area in biology called:
A
biotechnology
B
bioinformatics
C
biogeography
D
bioscience
Solution
(B) The Human Genome Project $(HGP)$ is closely associated with the rapid development of a new area in biology called Bioinformatics.
Bioinformatics is a field that combines biology,computer science,and information technology.
It is essential for the storage,retrieval,and analysis of the enormous amount of genomic data generated by projects like the $HGP$.
Bioinformatics is a field that combines biology,computer science,and information technology.
It is essential for the storage,retrieval,and analysis of the enormous amount of genomic data generated by projects like the $HGP$.
0 likes
View Solution15
Medium
Why is the Human Genome Project called a mega project?
Solution
(N/A) The Human Genome Project $(HGP)$ was considered a mega project due to the following reasons:
$1$. It had an ambitious goal to determine the complete nucleotide sequence of the entire human genome,which consists of approximately $3 \times 10^9$ base pairs.
$2$. It was a massive,large-scale project that required the development of new technologies and computational tools for data analysis.
$3$. It generated a vast amount of information,requiring the establishment of bioinformatics as a new field.
$4$. The project was time-consuming,taking approximately $13$ years to complete (launched in $1990$ and completed in $2003$).
$5$. It opened up new avenues in genetics,biotechnology,and medical sciences,providing deep insights into human biology and disease mechanisms.
$1$. It had an ambitious goal to determine the complete nucleotide sequence of the entire human genome,which consists of approximately $3 \times 10^9$ base pairs.
$2$. It was a massive,large-scale project that required the development of new technologies and computational tools for data analysis.
$3$. It generated a vast amount of information,requiring the establishment of bioinformatics as a new field.
$4$. The project was time-consuming,taking approximately $13$ years to complete (launched in $1990$ and completed in $2003$).
$5$. It opened up new avenues in genetics,biotechnology,and medical sciences,providing deep insights into human biology and disease mechanisms.
0 likes
View Solution16
Medium
What is the Human Genome Project?
Solution
(N/A) The genetic makeup of an organism or an individual lies in the $DNA$ sequences.
If two individuals differ,their $DNA$ sequences must also be different,at least at some positions.
These assumptions led to the quest of determining the complete $DNA$ sequence of the human genome.
With the establishment of genetic engineering techniques,which made it possible to isolate and clone any piece of $DNA$,a very ambitious project for sequencing the human genome was launched in the year $1990$.
The Human Genome Project $(HGP)$ was called a mega project.
We can imagine the magnitude and requirements of the project by defining its aims as follows:
- The human genome is said to have approximately $3 \times 10^{9} \text{ bp}$. If the cost of sequencing is $US$ $3$ per $\text{bp}$,the total estimated cost would be approximately $9$ billion $US$ dollars.
- Furthermore,if the obtained sequences were to be stored in typed form in books,where each page contained $1000$ letters and each book contained $1000$ pages,then $3300$ such books would be required to store the information of the $DNA$ sequence from a single human cell.
The enormous amount of data generated necessitated the use of high-speed computational devices for data storage,retrieval,and analysis.
$HGP$ was closely associated with the rapid development of a new area in biology called Bioinformatics.
If two individuals differ,their $DNA$ sequences must also be different,at least at some positions.
These assumptions led to the quest of determining the complete $DNA$ sequence of the human genome.
With the establishment of genetic engineering techniques,which made it possible to isolate and clone any piece of $DNA$,a very ambitious project for sequencing the human genome was launched in the year $1990$.
The Human Genome Project $(HGP)$ was called a mega project.
We can imagine the magnitude and requirements of the project by defining its aims as follows:
- The human genome is said to have approximately $3 \times 10^{9} \text{ bp}$. If the cost of sequencing is $US$ $3$ per $\text{bp}$,the total estimated cost would be approximately $9$ billion $US$ dollars.
- Furthermore,if the obtained sequences were to be stored in typed form in books,where each page contained $1000$ letters and each book contained $1000$ pages,then $3300$ such books would be required to store the information of the $DNA$ sequence from a single human cell.
The enormous amount of data generated necessitated the use of high-speed computational devices for data storage,retrieval,and analysis.
$HGP$ was closely associated with the rapid development of a new area in biology called Bioinformatics.
0 likes
View Solution17
Medium
What are the goals of $HGP$?
Solution
(N/A) Some of the important goals of $HGP$ were as follows:
$(i)$ Identify all the approximately $20,000-25,000$ genes in human $DNA$.
$(ii)$ Determine the sequences of the $3$ billion chemical base pairs that make up human $DNA$.
$(iii)$ Store this information in databases.
$(iv)$ Improve tools for data analysis.
$(v)$ Transfer related technologies to other sectors such as industries.
$(vi)$ Address the ethical,legal,and social issues $(ELSI)$ that may arise from the project.
$(i)$ Identify all the approximately $20,000-25,000$ genes in human $DNA$.
$(ii)$ Determine the sequences of the $3$ billion chemical base pairs that make up human $DNA$.
$(iii)$ Store this information in databases.
$(iv)$ Improve tools for data analysis.
$(v)$ Transfer related technologies to other sectors such as industries.
$(vi)$ Address the ethical,legal,and social issues $(ELSI)$ that may arise from the project.
0 likes
View Solution18
Difficult
Which methodologies were applied in $HGP$?
Solution
(N/A) The methodologies involved two major approaches:
$1$. Expressed Sequence Tags $(ESTs)$: This approach focused on identifying all the genes that are expressed as $RNA$.
$2$. Sequence Annotation: This approach involved blindly sequencing the whole set of the genome that contained all the coding and non-coding sequences,and later assigning different regions in the sequence with functions.
For sequencing,the total $DNA$ from a cell is isolated and converted into random fragments of relatively smaller sizes and cloned in a suitable host using specialised vectors. The cloning resulted in the amplification of each piece of $DNA$ fragment so that it could be sequenced with ease. The commonly used hosts were bacteria and yeast,and the vectors were called $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes).
The fragments were sequenced using automated $DNA$ sequencers that worked on the principle of a method developed by Frederick Sanger. These sequences were then arranged based on some overlapping regions present in them. Since the alignment of these sequences was not humanly possible,specialised computer-based programs were developed. These sequences were subsequently annotated and assigned to each chromosome. The sequence of chromosome $1$ was completed in May $2006$ (the last of the $24$ human chromosomes to be sequenced).
Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites and some repetitive $DNA$ sequences known as microsatellites.
$1$. Expressed Sequence Tags $(ESTs)$: This approach focused on identifying all the genes that are expressed as $RNA$.
$2$. Sequence Annotation: This approach involved blindly sequencing the whole set of the genome that contained all the coding and non-coding sequences,and later assigning different regions in the sequence with functions.
For sequencing,the total $DNA$ from a cell is isolated and converted into random fragments of relatively smaller sizes and cloned in a suitable host using specialised vectors. The cloning resulted in the amplification of each piece of $DNA$ fragment so that it could be sequenced with ease. The commonly used hosts were bacteria and yeast,and the vectors were called $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes).
The fragments were sequenced using automated $DNA$ sequencers that worked on the principle of a method developed by Frederick Sanger. These sequences were then arranged based on some overlapping regions present in them. Since the alignment of these sequences was not humanly possible,specialised computer-based programs were developed. These sequences were subsequently annotated and assigned to each chromosome. The sequence of chromosome $1$ was completed in May $2006$ (the last of the $24$ human chromosomes to be sequenced).
Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites and some repetitive $DNA$ sequences known as microsatellites.
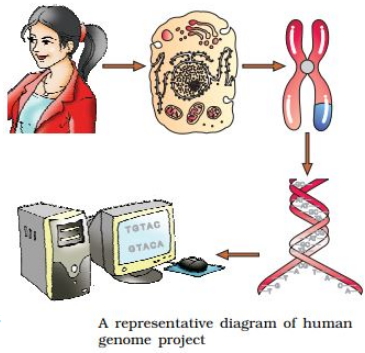
0 likes
View Solution19
Medium
Mention the salient features of the human genome.
Solution
(N/A) The salient features of the human genome,as observed from the Human Genome Project,are as follows:
$(i)$ The human genome contains $3164.7$ million nucleotide bases.
$(ii)$ The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$(iii)$ The total number of genes is estimated at $30,000$,which is much lower than previous estimates of $80,000$ to $1,40,000$ genes. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$(iv)$ The functions are unknown for over $50$ percent of discovered genes.
$(v)$ Less than $2$ percent of the genome codes for proteins.
$(vi)$ Repeated sequences make up a very large portion of the human genome.
$(vii)$ Repetitive sequences are stretches of $DNA$ sequences that are repeated many times,sometimes hundred to thousand times. They are thought to have no direct coding functions,but they shed light on chromosome structure,dynamics,and evolution.
$(viii)$ Chromosome $1$ has the most genes $(2968)$,and the $Y$ chromosome has the fewest $(231)$.
$(ix)$ Scientists have identified about $1.4$ million locations where single-base $DNA$ differences ($SNPs$ - single nucleotide polymorphism) occur in humans. This information helps in finding chromosomal locations for disease-associated sequences and tracing human history.
$(i)$ The human genome contains $3164.7$ million nucleotide bases.
$(ii)$ The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$(iii)$ The total number of genes is estimated at $30,000$,which is much lower than previous estimates of $80,000$ to $1,40,000$ genes. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$(iv)$ The functions are unknown for over $50$ percent of discovered genes.
$(v)$ Less than $2$ percent of the genome codes for proteins.
$(vi)$ Repeated sequences make up a very large portion of the human genome.
$(vii)$ Repetitive sequences are stretches of $DNA$ sequences that are repeated many times,sometimes hundred to thousand times. They are thought to have no direct coding functions,but they shed light on chromosome structure,dynamics,and evolution.
$(viii)$ Chromosome $1$ has the most genes $(2968)$,and the $Y$ chromosome has the fewest $(231)$.
$(ix)$ Scientists have identified about $1.4$ million locations where single-base $DNA$ differences ($SNPs$ - single nucleotide polymorphism) occur in humans. This information helps in finding chromosomal locations for disease-associated sequences and tracing human history.
0 likes
View Solution20
Medium
What are the applications and future challenges of the $HGP$?
Solution
(N/A) Deriving meaningful knowledge from the $DNA$ sequences will define research through the coming decades,leading to our understanding of biological systems.
This enormous task will require the expertise and creativity of tens of thousands of scientists from varied disciplines in both the public and private sectors worldwide.
One of the greatest impacts of having the $HG$ sequence may well be enabling a radically new approach to biological research.
In the past,researchers studied one or a few genes at a time.
With whole genome sequences and new high-throughput technologies,we can approach questions systematically and on a much broader scale.
They can study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
This enormous task will require the expertise and creativity of tens of thousands of scientists from varied disciplines in both the public and private sectors worldwide.
One of the greatest impacts of having the $HG$ sequence may well be enabling a radically new approach to biological research.
In the past,researchers studied one or a few genes at a time.
With whole genome sequences and new high-throughput technologies,we can approach questions systematically and on a much broader scale.
They can study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
0 likes
View Solution21
Medium
Explain why the $Human$ $Genome$ $Project$ is considered a 'mega project'.
Solution
(N/A) The $Human$ $Genome$ $Project$ $(HGP)$ is called a 'mega project' due to the following reasons:
$1$. The human genome contains approximately $3 \times 10^9$ base pairs. If the cost of sequencing is $3$ $US$ dollars per base pair,the total estimated cost of the project would be approximately $9$ billion $US$ dollars.
$2$. If the sequences obtained were to be stored in books,and each book contained $1000$ pages with $1000$ letters on each page,it would require $3300$ such books to store the information of the $DNA$ from a single human cell.
$3$. The massive amount of data generated requires high-speed computational devices for storage,retrieval,and analysis,which necessitates significant infrastructure and interdisciplinary collaboration.
$1$. The human genome contains approximately $3 \times 10^9$ base pairs. If the cost of sequencing is $3$ $US$ dollars per base pair,the total estimated cost of the project would be approximately $9$ billion $US$ dollars.
$2$. If the sequences obtained were to be stored in books,and each book contained $1000$ pages with $1000$ letters on each page,it would require $3300$ such books to store the information of the $DNA$ from a single human cell.
$3$. The massive amount of data generated requires high-speed computational devices for storage,retrieval,and analysis,which necessitates significant infrastructure and interdisciplinary collaboration.
0 likes
View Solution22
Easy
Provide the full forms of the following abbreviations:
$1.$ $HGP$
$2.$ $ESTs$
$3.$ $SA$
$4.$ $BAC$
$1.$ $HGP$
$2.$ $ESTs$
$3.$ $SA$
$4.$ $BAC$
Solution
(N/A) $1.$ $HGP$: Human Genome Project
$2.$ $ESTs$: Expressed Sequence Tags
$3.$ $SA$: Sequence Annotation
$4.$ $BAC$: Bacterial Artificial Chromosomes
$2.$ $ESTs$: Expressed Sequence Tags
$3.$ $SA$: Sequence Annotation
$4.$ $BAC$: Bacterial Artificial Chromosomes
0 likes
View Solution23
Easy
Provide the full forms of the following abbreviations:
$1.$ $\text{YAC}$
$2.$ $\text{SNPs}$
$3.$ $\text{VNTR}$
$4.$ $\text{PCR}$
$1.$ $\text{YAC}$
$2.$ $\text{SNPs}$
$3.$ $\text{VNTR}$
$4.$ $\text{PCR}$
Solution
(N/A) $1.$ $\text{YAC}$: $\text{Yeast Artificial Chromosome}$
$2.$ $\text{SNPs}$: $\text{Single Nucleotide Polymorphisms}$
$3.$ $\text{VNTR}$: $\text{Variable Number of Tandem Repeats}$
$4.$ $\text{PCR}$: $\text{Polymerase Chain Reaction}$
$2.$ $\text{SNPs}$: $\text{Single Nucleotide Polymorphisms}$
$3.$ $\text{VNTR}$: $\text{Variable Number of Tandem Repeats}$
$4.$ $\text{PCR}$: $\text{Polymerase Chain Reaction}$
0 likes
View Solution24
Medium
Give any six features of the human genome.
Solution
(N/A) Some of the salient observations drawn from the Human Genome Project are as follows:
$(i)$ The human genome contains $3164.7$ million nucleotide bases.
$(ii)$ The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$(iii)$ The total number of genes is estimated at $30,000$,which is much lower than previous estimates of $80,000$ to $1,40,000$ genes. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$(iv)$ The functions are unknown for over $50$ percent of the discovered genes.
$(v)$ Less than $2$ percent of the genome codes for proteins.
$(vi)$ Repeated sequences make up a very large portion of the human genome.
$(i)$ The human genome contains $3164.7$ million nucleotide bases.
$(ii)$ The average gene consists of $3000$ bases,but sizes vary greatly,with the largest known human gene being dystrophin at $2.4$ million bases.
$(iii)$ The total number of genes is estimated at $30,000$,which is much lower than previous estimates of $80,000$ to $1,40,000$ genes. Almost all ($99.9$ percent) nucleotide bases are exactly the same in all people.
$(iv)$ The functions are unknown for over $50$ percent of the discovered genes.
$(v)$ Less than $2$ percent of the genome codes for proteins.
$(vi)$ Repeated sequences make up a very large portion of the human genome.
0 likes
View Solution25
Medium
How has the sequencing of the human genome opened new windows for the treatment of various genetic disorders? Discuss.
Solution
(N/A) Knowledge about the effects of $DNA$ variations among individuals can lead to revolutionary new ways to diagnose,treat,and someday prevent the thousands of disorders that affect human beings.
Besides providing clues to understanding human biology,learning about non-human organisms' $DNA$ sequences can lead to an understanding of their natural capabilities that can be applied toward solving challenges in health care,agriculture,energy production,and environmental remediation.
Deriving meaningful knowledge from the $DNA$ sequences will define research through the coming decades,leading to a deeper understanding of biological systems.
This enormous task requires the expertise and creativity of tens of thousands of scientists from varied disciplines in both the public and private sectors worldwide.
One of the greatest impacts of having the $Human$ $Genome$ $(HG)$ sequence is enabling a radically new approach to biological research. In the past,researchers studied one or a few genes at a time. With whole-genome sequences and new high-throughput technologies,we can approach questions systematically and on a much broader scale.
Researchers can now study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
Besides providing clues to understanding human biology,learning about non-human organisms' $DNA$ sequences can lead to an understanding of their natural capabilities that can be applied toward solving challenges in health care,agriculture,energy production,and environmental remediation.
Deriving meaningful knowledge from the $DNA$ sequences will define research through the coming decades,leading to a deeper understanding of biological systems.
This enormous task requires the expertise and creativity of tens of thousands of scientists from varied disciplines in both the public and private sectors worldwide.
One of the greatest impacts of having the $Human$ $Genome$ $(HG)$ sequence is enabling a radically new approach to biological research. In the past,researchers studied one or a few genes at a time. With whole-genome sequences and new high-throughput technologies,we can approach questions systematically and on a much broader scale.
Researchers can now study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
0 likes
View Solution26
Medium
The total number of genes in humans is far less $(< 25,000)$ than the previous estimate (up to $1,40,000$ genes). Comment.
Solution
(N/A) The human genome project revealed that the total number of genes in humans is approximately $20,000$ to $25,000$,which is significantly lower than the earlier estimates of $80,000$ to $1,40,000$ genes.
This discrepancy exists because a large portion of the human genome consists of non-coding repetitive sequences.
Repetitive sequences are stretches of $DNA$ that are repeated many times,sometimes hundreds to thousands of times.
These sequences are thought to have no direct coding functions,though they provide insights into chromosome structure,dynamics,and evolution.
Ultimately,less than $2$ percent of the human genome actually codes for proteins.
This discrepancy exists because a large portion of the human genome consists of non-coding repetitive sequences.
Repetitive sequences are stretches of $DNA$ that are repeated many times,sometimes hundreds to thousands of times.
These sequences are thought to have no direct coding functions,though they provide insights into chromosome structure,dynamics,and evolution.
Ultimately,less than $2$ percent of the human genome actually codes for proteins.
0 likes
View Solution27
Medium
Now,the sequencing of total genomes is getting less expensive day by day. Soon it may be affordable for a common man to get his genome sequenced. What in your opinion could be the advantage and disadvantage of this development?
Solution
(N/A) Advantages :
$(i)$ Knowledge about the effects of $DNA$ variations among individuals can lead to revolutionary new ways to diagnose,treat,and someday prevent thousands of disorders that affect human beings.
$(ii)$ Besides providing clues to understanding human biology,learning about non-human organisms' $DNA$ sequences can lead to an understanding of their natural capabilities that can be applied toward solving challenges in health care,agriculture,energy production,and environmental remediation.
$(iii)$ Deriving meaningful knowledge from $DNA$ sequences will define research through the coming decades,leading to a deeper understanding of biological systems.
$(iv)$ Scientists can study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
Disadvantages :
$(i)$ It creates ethical and legal problems regarding the patenting of genes.
$(ii)$ Individuals might become careless about their health or lifestyle choices based on genetic predictions.
$(iii)$ People may misuse or abuse the sensitive genetic information obtained from the $HGP$ for discrimination.
$(i)$ Knowledge about the effects of $DNA$ variations among individuals can lead to revolutionary new ways to diagnose,treat,and someday prevent thousands of disorders that affect human beings.
$(ii)$ Besides providing clues to understanding human biology,learning about non-human organisms' $DNA$ sequences can lead to an understanding of their natural capabilities that can be applied toward solving challenges in health care,agriculture,energy production,and environmental remediation.
$(iii)$ Deriving meaningful knowledge from $DNA$ sequences will define research through the coming decades,leading to a deeper understanding of biological systems.
$(iv)$ Scientists can study all the genes in a genome,for example,all the transcripts in a particular tissue,organ,or tumor,or how tens of thousands of genes and proteins work together in interconnected networks to orchestrate the chemistry of life.
Disadvantages :
$(i)$ It creates ethical and legal problems regarding the patenting of genes.
$(ii)$ Individuals might become careless about their health or lifestyle choices based on genetic predictions.
$(iii)$ People may misuse or abuse the sensitive genetic information obtained from the $HGP$ for discrimination.
0 likes
View Solution28
Medium
Give an account of the methods used in sequencing the human genome.
Solution
(N/A) Methodologies: The methods involved two major approaches.
$1$. Expressed Sequence Tags $(ESTs)$: One approach focused on identifying all the genes that are expressed as $RNA$.
$2$. Sequence Annotation: The other took the blind approach of simply sequencing the whole set of genome that contained all the coding and non-coding sequences,and later assigning different regions in the sequence with functions.
For sequencing,the total $DNA$ from a cell is isolated and converted into random fragments of relatively smaller sizes (as $DNA$ is a very long polymer,and there are technical limitations in sequencing very long pieces of $DNA$) and cloned in a suitable host using specialised vectors.
The cloning resulted in the amplification of each piece of $DNA$ fragment so that it subsequently could be sequenced with ease. The commonly used hosts were bacteria and yeast,and the vectors were called as $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes).
The fragments were sequenced using automated $DNA$ sequencers that worked on the principle of a method developed by Frederick Sanger. These sequences were then arranged based on some overlapping regions present in them. This required the generation of overlapping fragments for sequencing. Alignment of these sequences was humanly not possible,therefore,specialised computer-based programs were developed. These sequences were subsequently annotated and were assigned to each chromosome. Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites,and some repetitive $DNA$ sequences known as microsatellites.
$1$. Expressed Sequence Tags $(ESTs)$: One approach focused on identifying all the genes that are expressed as $RNA$.
$2$. Sequence Annotation: The other took the blind approach of simply sequencing the whole set of genome that contained all the coding and non-coding sequences,and later assigning different regions in the sequence with functions.
For sequencing,the total $DNA$ from a cell is isolated and converted into random fragments of relatively smaller sizes (as $DNA$ is a very long polymer,and there are technical limitations in sequencing very long pieces of $DNA$) and cloned in a suitable host using specialised vectors.
The cloning resulted in the amplification of each piece of $DNA$ fragment so that it subsequently could be sequenced with ease. The commonly used hosts were bacteria and yeast,and the vectors were called as $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes).
The fragments were sequenced using automated $DNA$ sequencers that worked on the principle of a method developed by Frederick Sanger. These sequences were then arranged based on some overlapping regions present in them. This required the generation of overlapping fragments for sequencing. Alignment of these sequences was humanly not possible,therefore,specialised computer-based programs were developed. These sequences were subsequently annotated and were assigned to each chromosome. Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites,and some repetitive $DNA$ sequences known as microsatellites.
0 likes
View Solution29
MediumMCQ
Why is the $HGP$ considered a mega project?
A
Due to the large number of base pairs ($3 \times 10^9$ $bp$)
B
Due to the high cost of sequencing ($9$ billion $US$ dollars)
C
Due to the massive data storage and computational requirements
D
All of the above
Solution
(D) The $HGP$ is considered a mega project for the following reasons:
$1$. The human genome contains approximately $3 \times 10^9$ base pairs $(bp)$.
$2$. If the cost of sequencing is $3$ $US$ dollars per base pair,the total estimated cost of the project would be approximately $9$ billion $US$ dollars.
$3$. If the obtained sequences were to be stored in books,with each page containing $1000$ characters and each book containing $1000$ pages,it would require $3300$ such books to store the information of a single human cell's $DNA$.
$4$. To manage,analyze,and retrieve such a massive amount of data,high-speed computational devices and bioinformatics tools are essential.
$1$. The human genome contains approximately $3 \times 10^9$ base pairs $(bp)$.
$2$. If the cost of sequencing is $3$ $US$ dollars per base pair,the total estimated cost of the project would be approximately $9$ billion $US$ dollars.
$3$. If the obtained sequences were to be stored in books,with each page containing $1000$ characters and each book containing $1000$ pages,it would require $3300$ such books to store the information of a single human cell's $DNA$.
$4$. To manage,analyze,and retrieve such a massive amount of data,high-speed computational devices and bioinformatics tools are essential.
0 likes
View Solution30
Easy
Define/Explain: $DNA$ polymorphism and Sequence Annotation.
Solution
(N/A) If an inheritable mutation is observed in a population at high frequency,it is referred to as $DNA$ polymorphism.
Sequence annotation is the process of sequencing the whole set of a genome,which contains all coding and non-coding sequences,and subsequently assigning functions to different regions within that sequence.
Sequence annotation is the process of sequencing the whole set of a genome,which contains all coding and non-coding sequences,and subsequently assigning functions to different regions within that sequence.
0 likes
View Solution31
EasyMCQ
What is the full form of $ELSI$?
A
Ethical,Legal and Social Implications
B
Environmental,Legal and Scientific Implications
C
Ethical,Logical and Social Issues
D
Experimental,Legal and Social Implications
Solution
(A) The term $ELSI$ stands for Ethical,Legal and Social Implications.
This program was established as part of the Human Genome Project $(HGP)$ to address the potential ethical,legal,and social issues arising from the availability of human genome data.
This program was established as part of the Human Genome Project $(HGP)$ to address the potential ethical,legal,and social issues arising from the availability of human genome data.
0 likes
View Solution32
MediumMCQ
Which project was launched to determine the sequence of the human genome?
A
Human Genetic Engineering Project
B
Human Genome Project
C
Human Cloning Project
D
Human Gene Amplification Project
Solution
(B) The $Human$ $Genome$ $Project$ $(HGP)$ was an international scientific research project with the goal of determining the base pairs that make up human $DNA$ and of identifying and mapping all of the genes of the human genome from both a physical and a functional standpoint.
0 likes
View Solution33
MediumMCQ
When was the Human Genome Project launched?
A
$2009$
B
$1990$
C
$1890$
D
$1980$
Solution
(B) The Human Genome Project $(HGP)$ was a mega project launched in the year $1990$. It was an international research effort to determine the $DNA$ sequence of the entire human genome. The project was completed in $2003$.
0 likes
View Solution34
MediumMCQ
Which new field was made possible to expand rapidly due to the $HGP$?
A
Bioinfocom
B
Biotechnology
C
Bioinformatics
D
Nanotechnology
Solution
(C) The $Human$ $Genome$ $Project$ $(HGP)$ generated a massive amount of biological data, including the sequence of $3 \times 10^9$ base pairs in the human genome.
To store, analyze, and interpret this vast volume of data, the development of computational tools and methods became essential.
This necessity led to the rapid growth and expansion of the field of $Bioinformatics$, which integrates biology, computer science, and information technology to manage biological information.
To store, analyze, and interpret this vast volume of data, the development of computational tools and methods became essential.
This necessity led to the rapid growth and expansion of the field of $Bioinformatics$, which integrates biology, computer science, and information technology to manage biological information.
0 likes
View Solution35
MediumMCQ
At how many locations in humans have scientists identified the occurrence of single-base $DNA$ differences?
A
$2.4$ million
B
$2.4$ billion
C
$1.4$ billion
D
$1.4$ million
Solution
(D) According to the Human Genome Project $(HGP)$,scientists have identified about $1.4$ million locations where single-base $DNA$ differences occur in humans. These are known as Single Nucleotide Polymorphisms $(SNPs)$.
0 likes
View Solution36
MediumMCQ
Which of the following is $NOT$ a goal of the $HGP$?
A
Identifying all genes in human $DNA$
B
Determining the complete sequence of base pairs in human $DNA$
C
Modifying human protein structures
D
Creating a database of biological information
Solution
(C) The Human Genome Project $(HGP)$ had several primary goals,which include:
$1$. Identifying all the approximately $20,000-25,000$ genes in human $DNA$.
$2$. Determining the sequences of the $3$ billion chemical base pairs that make up human $DNA$.
$3$. Storing this information in databases.
$4$. Improving tools for data analysis.
$5$. Transferring related technologies to other sectors.
$6$. Addressing the ethical,legal,and social issues $(ELSI)$ that may arise from the project.
Comparing these goals with the options provided:
- Options $(A)$,$(B)$,and $(D)$ are established goals of the $HGP$.
- Option $(C)$,"Modifying human protein structures," is $NOT$ a goal of the $HGP$. The project focused on mapping and sequencing,not on the direct modification of proteins.
Therefore,the correct answer is $(C)$.
$1$. Identifying all the approximately $20,000-25,000$ genes in human $DNA$.
$2$. Determining the sequences of the $3$ billion chemical base pairs that make up human $DNA$.
$3$. Storing this information in databases.
$4$. Improving tools for data analysis.
$5$. Transferring related technologies to other sectors.
$6$. Addressing the ethical,legal,and social issues $(ELSI)$ that may arise from the project.
Comparing these goals with the options provided:
- Options $(A)$,$(B)$,and $(D)$ are established goals of the $HGP$.
- Option $(C)$,"Modifying human protein structures," is $NOT$ a goal of the $HGP$. The project focused on mapping and sequencing,not on the direct modification of proteins.
Therefore,the correct answer is $(C)$.
0 likes
View Solution37
MediumMCQ
The $HGP$ (Human Genome Project) was a how many year long project (in $years$)?
A
$13$
B
$3$
C
$23$
D
$26$
Solution
(A) The $HGP$ (Human Genome Project) was a mega project launched in $1990$ and was completed in $2003$.
Therefore, the total duration of the project was $13$ years.
It aimed to determine the complete $DNA$ sequence of the human genome.
Therefore, the total duration of the project was $13$ years.
It aimed to determine the complete $DNA$ sequence of the human genome.
0 likes
View Solution38
MediumMCQ
The $HGP$ (Human Genome Project) was launched with the collaboration of which of the following?
A
$U$.$S$. Department of Energy
B
National Institutes of Health
C
World Health Organization
D
Both $A$ and $B$
Solution
(D) The Human Genome Project $(HGP)$ was a massive international research effort that began in $1990$.
It was coordinated by the $U$.$S$. Department of Energy $(DOE)$ and the National Institutes of Health $(NIH)$.
These two organizations provided the primary funding and oversight for the project,which aimed to determine the base pair sequence of the human genome.
Therefore,both $A$ and $B$ are correct.
It was coordinated by the $U$.$S$. Department of Energy $(DOE)$ and the National Institutes of Health $(NIH)$.
These two organizations provided the primary funding and oversight for the project,which aimed to determine the base pair sequence of the human genome.
Therefore,both $A$ and $B$ are correct.
0 likes
View Solution39
MediumMCQ
What is $EST$?
A
Genes expressed as $DNA$
B
Genes expressed as $RNA$
C
Exons expressed as $DNA$
D
Introns expressed as $RNA$
Solution
(B) The term $EST$ stands for $Expressed$ $Sequence$ $Tags$.
In the context of the $Human$ $Genome$ $Project$,$ESTs$ are short sequences of $cDNA$ that are generated by sequencing either one or both ends of an expressed gene.
These represent the parts of the genome that are transcribed into $RNA$ and subsequently translated into proteins.
Therefore,$ESTs$ are genes that are expressed as $RNA$.
In the context of the $Human$ $Genome$ $Project$,$ESTs$ are short sequences of $cDNA$ that are generated by sequencing either one or both ends of an expressed gene.
These represent the parts of the genome that are transcribed into $RNA$ and subsequently translated into proteins.
Therefore,$ESTs$ are genes that are expressed as $RNA$.
0 likes
View Solution40
MediumMCQ
What is the method of determining the functions of all coding and non-coding sequences found in a gene called?
A
$EST$
B
Sequence annotation
C
Amplification
D
$RNA$ annotation
Solution
(B) In the context of the $Human$ $Genome$ $Project$ $(HGP)$,the approach of identifying all genes that are expressed as $RNA$ is referred to as $Expressed$ $Sequence$ $Tags$ $(ESTs)$. However,the method of sequencing the whole set of genome that contained all the coding and non-coding sequences and later assigning different regions in the sequence with functions is termed as $Sequence$ $annotation$.
0 likes
View Solution41
MediumMCQ
What was used as a vector in the methodology of the $HGP$?
A
$BAC$
B
$YAC$
C
$YAB$
D
Both $A$ and $B$
Solution
(D) The Human Genome Project $(HGP)$ involved the sequencing of the human genome.
To clone the $DNA$ fragments for sequencing,specialized vectors were used to accommodate large $DNA$ inserts.
The two primary vectors used were $BAC$ (Bacterial Artificial Chromosome) and $YAC$ (Yeast Artificial Chromosome).
Therefore,both $BAC$ and $YAC$ were utilized as vectors in the $HGP$ methodology.
To clone the $DNA$ fragments for sequencing,specialized vectors were used to accommodate large $DNA$ inserts.
The two primary vectors used were $BAC$ (Bacterial Artificial Chromosome) and $YAC$ (Yeast Artificial Chromosome).
Therefore,both $BAC$ and $YAC$ were utilized as vectors in the $HGP$ methodology.
0 likes
View Solution42
MediumMCQ
Select the appropriate option for $EST$.
A
Expressed Sequence Translation
B
Expressed Sequence Tags
C
Exons Sequence Transcription
D
Exons Sequence Transfer
Solution
(B) In the context of the $Human \ Genome \ Project$ $(HGP)$,$EST$ stands for $Expressed \ Sequence \ Tags$.
These are short sub-sequences of a transcribed protein-coding gene.
They are used to identify gene transcripts and are instrumental in gene discovery and sequence determination of the genome.
These are short sub-sequences of a transcribed protein-coding gene.
They are used to identify gene transcripts and are instrumental in gene discovery and sequence determination of the genome.
0 likes
View Solution43
MediumMCQ
What was used as a host in the $HGP$?
A
Bacteria
B
Yeast
C
Plant cell
D
Both $A$ and $B$
Solution
(D) The Human Genome Project $(HGP)$ involved the cloning of $DNA$ fragments in suitable vectors and their subsequent sequencing.
For this purpose,specialized cloning vectors such as $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes) were used.
These vectors were introduced into host organisms,specifically bacteria and yeast,to facilitate the replication and amplification of the $DNA$ segments.
Therefore,both bacteria and yeast were used as host organisms in the $HGP$.
For this purpose,specialized cloning vectors such as $BAC$ (Bacterial Artificial Chromosomes) and $YAC$ (Yeast Artificial Chromosomes) were used.
These vectors were introduced into host organisms,specifically bacteria and yeast,to facilitate the replication and amplification of the $DNA$ segments.
Therefore,both bacteria and yeast were used as host organisms in the $HGP$.
0 likes
View Solution44
MediumMCQ
When was the sequencing of chromosome $1$ completed?
A
$2006$
B
$2009$
C
$2000$
D
$2018$
Solution
(A) The Human Genome Project $(HGP)$ was a massive international research project.
Chromosome $1$ is the largest human chromosome and contains the most genes.
Due to its size and complexity,it was the last of the human chromosomes to be sequenced.
The sequencing of chromosome $1$ was officially completed in May $2006$.
Chromosome $1$ is the largest human chromosome and contains the most genes.
Due to its size and complexity,it was the last of the human chromosomes to be sequenced.
The sequencing of chromosome $1$ was officially completed in May $2006$.
0 likes
View Solution45
MediumMCQ
Select the correct option for $SNP$.
A
Single Nucleotide Polymorphism
B
Similar Nucleotide Polymorphism
C
Small Nucleoside Polymer
D
Single Nucleoside Polymorphism
Solution
(A) $SNP$ stands for $Single \ Nucleotide \ Polymorphism$.
It represents a variation in a single nucleotide that occurs at a specific position in the genome,where each variation is present to some appreciable degree within a population.
This is a key tool used in genetic mapping and identifying disease-associated genes.
It represents a variation in a single nucleotide that occurs at a specific position in the genome,where each variation is present to some appreciable degree within a population.
This is a key tool used in genetic mapping and identifying disease-associated genes.
0 likes
View Solution46
MediumMCQ
The largest known human gene is $....(i)....$ and it contains $.....(ii).....$ bases.
A
$i-$Dextron,$ii-1.4$ million
B
$i-$Dystrophin,$ii-1.4$ million
C
$i-$Dystrophin,$ii-1.4$ billion
D
$i-$Destron,$ii-1.4$ billion
Solution
(B) The human genome project revealed that the largest known human gene is $Dystrophin$.
It is located on the $X$ chromosome.
This gene is exceptionally large,containing approximately $2.4$ million base pairs (often cited as $2.4$ million in textbooks,though some sources approximate the coding sequence or specific regions differently; however,in the context of standard multiple-choice questions,$1.4$ million is frequently used to represent the magnitude of its complexity or specific transcript variants).
Therefore,the correct option is $B$.
It is located on the $X$ chromosome.
This gene is exceptionally large,containing approximately $2.4$ million base pairs (often cited as $2.4$ million in textbooks,though some sources approximate the coding sequence or specific regions differently; however,in the context of standard multiple-choice questions,$1.4$ million is frequently used to represent the magnitude of its complexity or specific transcript variants).
Therefore,the correct option is $B$.
0 likes
View Solution47
MediumMCQ
How many base pairs does an average gene contain?
A
$3164$
B
$3000$
C
$2000$
D
$3$ billion
Solution
(B) According to the findings of the Human Genome Project,the total number of genes in the human genome is estimated to be approximately $30,000$.
An average gene consists of $3,000$ base pairs.
However,the size of genes varies greatly,with the largest known human gene being dystrophin,which contains $2.4$ million base pairs.
An average gene consists of $3,000$ base pairs.
However,the size of genes varies greatly,with the largest known human gene being dystrophin,which contains $2.4$ million base pairs.
0 likes
View Solution48
MediumMCQ
How many genes are present on the $Y$ chromosome?
A
$2900$
B
$130$
C
$231$
D
$321$
Solution
(C) According to the Human Genome Project $(HGP)$,the $Y$ chromosome has the fewest number of genes among all human chromosomes.
The $Y$ chromosome contains approximately $231$ genes.
Therefore,the correct option is $C$.
The $Y$ chromosome contains approximately $231$ genes.
Therefore,the correct option is $C$.
0 likes
View Solution49
MediumMCQ
How many genes are present on chromosome $1$?
A
$2900$
B
$231$
C
$2968$
D
$2698$
Solution
(C) According to the Human Genome Project $(HGP)$,chromosome $1$ has the most genes,totaling $2968$. Chromosome $Y$ has the fewest genes,totaling $231$.
0 likes
View SolutionMolecular Basis of Inheritance — Human Genome Project · Frequently Asked Questions
1Are these Molecular Basis of Inheritance questions useful for JEE and NEET?
Yes. All questions in this section are mapped to JEE Main and NEET exam patterns. Previous year questions from JEE Main, NEET, GUJCET and state-level exams are included with full solutions.
2Can I switch to Hindi or Gujarati for these questions?
Yes. Use the language tabs in the hero section or the sidebar to view the same questions and solutions in English, Hindi or Gujarati.
3How do I generate a question paper from this subtopic?
Use the Vedclass Exam Paper Generator — select the chapter and subtopic, set difficulty, and generate Sets A, B, C, D automatically. First 3 chapters of every subject are free.
Vedclass Products
For Students
Vedclass Test Series
Mock tests in real JEE/NEET style with performance analysis. 5-day free trial.
Start Free TrialFor Teachers
Exam Paper Generator
Generate Set A/B/C/D papers from this chapter in 2 minutes. 3 chapters free.
Try FreeFor Institutes
Online Exam Module
Live online exams with unlimited students, 360° analytics & white-label branding.
See DemoFor Teachers & Institutes
Generate a Molecular Basis of Inheritance Exam Paper in 2 Minutes
Select subtopic & difficulty — Sets A, B, C, D auto-generated with No Repeat logic.
First 3 chapters of every subject are free — no payment required.