
अ Hindi
Transcription Questions in Hindi
Class 12 Biology · Molecular Basis of Inheritance · Transcription
277+
Questions
Hindi
Language
100%
With Solutions
Showing 27 of 277 questions in Hindi
251
EasyMCQ
अनुलेखन (transcription) के दौरान,$DNA$ की जो रज्जुक (strand) टेम्पलेट के रूप में कार्य करती है,उसे $A$ रज्जुक कहा जाता है और इसकी ध्रुवता $B$ होती है।
A
$A$ - एंटीसेंस,$B$ - $3' \rightarrow 5'$
B
$A$ - कोडिंग,$B$ - $5' \rightarrow 3'$
C
$A$ - सेंस,$B$ - $3' \rightarrow 5'$
D
$A$ - सेंस,$B$ - $5' \rightarrow 3'$
Solution
(A) अनुलेखन की प्रक्रिया के दौरान,$DNA$ के दो रज्जुक में से केवल एक ही रज्जुक का $RNA$ में प्रतिलेखन होता है।
इस रज्जुक को टेम्पलेट रज्जुक या एंटीसेंस रज्जुक के रूप में जाना जाता है।
$RNA$ पॉलीमरेज़ एंजाइम न्यूक्लियोटाइड्स के बहुलकीकरण (polymerization) को $5' \rightarrow 3'$ दिशा में उत्प्रेरित करता है।
इसलिए,टेम्पलेट रज्जुक की ध्रुवता $3' \rightarrow 5'$ होनी चाहिए ताकि नवनिर्मित $RNA$ रज्जुक $5' \rightarrow 3'$ दिशा में बन सके।
अतः,$A$ एंटीसेंस रज्जुक है और $B$ की ध्रुवता $3' \rightarrow 5'$ है।
इस रज्जुक को टेम्पलेट रज्जुक या एंटीसेंस रज्जुक के रूप में जाना जाता है।
$RNA$ पॉलीमरेज़ एंजाइम न्यूक्लियोटाइड्स के बहुलकीकरण (polymerization) को $5' \rightarrow 3'$ दिशा में उत्प्रेरित करता है।
इसलिए,टेम्पलेट रज्जुक की ध्रुवता $3' \rightarrow 5'$ होनी चाहिए ताकि नवनिर्मित $RNA$ रज्जुक $5' \rightarrow 3'$ दिशा में बन सके।
अतः,$A$ एंटीसेंस रज्जुक है और $B$ की ध्रुवता $3' \rightarrow 5'$ है।
0 likes
View Solution252
EasyMCQ
नीचे दो कथन दिए गए हैं।
कथन $I$: अनुलेखन इकाई (transcription unit) में केवल एक रज्जुक (strand) टेम्पलेट के रूप में कार्य करता है और इसे एंटीसेंस रज्जुक कहा जाता है।
कथन $II$: अनुलेखन इकाई के नॉन-टेम्पलेट रज्जुक को सेंस रज्जुक कहा जाता है।
उपर्युक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनिए।
कथन $I$: अनुलेखन इकाई (transcription unit) में केवल एक रज्जुक (strand) टेम्पलेट के रूप में कार्य करता है और इसे एंटीसेंस रज्जुक कहा जाता है।
कथन $II$: अनुलेखन इकाई के नॉन-टेम्पलेट रज्जुक को सेंस रज्जुक कहा जाता है।
उपर्युक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनिए।
A
कथन $I$ गलत है लेकिन कथन $II$ सही है।
B
कथन $I$ और कथन $II$ दोनों सही हैं।
C
कथन $I$ और कथन $II$ दोनों गलत हैं।
D
कथन $I$ सही है लेकिन कथन $II$ गलत है।
Solution
(B) एक अनुलेखन इकाई में,$DNA$ का द्विकुंडलित रज्जुक विपरीत ध्रुवता ($3' \rightarrow 5'$ और $5' \rightarrow 3'$) वाले दो रज्जुक से बना होता है।
अनुलेखन के दौरान,केवल एक रज्जुक $RNA$ संश्लेषण के लिए टेम्पलेट के रूप में कार्य करता है,जिसे टेम्पलेट रज्जुक या एंटीसेंस रज्जुक ($3' \rightarrow 5'$ ध्रुवता) के रूप में जाना जाता है।
दूसरा रज्जुक,जिसका अनुक्रम $RNA$ के समान होता है ($U$ के बजाय $T$ को छोड़कर),उसे कोडिंग रज्जुक या सेंस रज्जुक ($5' \rightarrow 3'$ ध्रुवता) के रूप में जाना जाता है।
अतः,कथन $I$ और कथन $II$ दोनों वैज्ञानिक रूप से सही हैं।
अनुलेखन के दौरान,केवल एक रज्जुक $RNA$ संश्लेषण के लिए टेम्पलेट के रूप में कार्य करता है,जिसे टेम्पलेट रज्जुक या एंटीसेंस रज्जुक ($3' \rightarrow 5'$ ध्रुवता) के रूप में जाना जाता है।
दूसरा रज्जुक,जिसका अनुक्रम $RNA$ के समान होता है ($U$ के बजाय $T$ को छोड़कर),उसे कोडिंग रज्जुक या सेंस रज्जुक ($5' \rightarrow 3'$ ध्रुवता) के रूप में जाना जाता है।
अतः,कथन $I$ और कथन $II$ दोनों वैज्ञानिक रूप से सही हैं।
0 likes
View Solution253
EasyMCQ
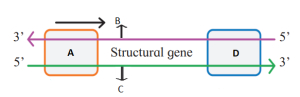
दिए गए ट्रांसक्रिप्शन यूनिट के आरेख के लिए लेबलिंग का सही सेट पहचानें।
A
$A$ - टर्मिनेटर,$B$ - टेम्पलेट रज्जुक,$C$ - कोडिंग रज्जुक,$D$ - प्रमोटर
B
$A$ - प्रमोटर,$B$ - कोडिंग रज्जुक,$C$ - टेम्पलेट रज्जुक,$D$ - टर्मिनेटर
C
$A$ - टर्मिनेटर,$B$ - कोडिंग रज्जुक,$C$ - टेम्पलेट रज्जुक,$D$ - प्रमोटर
D
$A$ - प्रमोटर,$B$ - टेम्पलेट रज्जुक,$C$ - कोडिंग रज्जुक,$D$ - टर्मिनेटर
Solution
(B) एक ट्रांसक्रिप्शन यूनिट में,प्रमोटर कोडिंग रज्जुक के $5'$ सिरे (अपस्ट्रीम) पर स्थित होता है और टर्मिनेटर कोडिंग रज्जुक के $3'$ सिरे (डाउनस्ट्रीम) पर स्थित होता है।
आरेख में दिखाए गए रज्जुक की ध्रुवता के आधार पर:
$5' \rightarrow 3'$ ध्रुवता वाला रज्जुक कोडिंग रज्जुक $(B)$ है।
$3' \rightarrow 5'$ ध्रुवता वाला रज्जुक टेम्पलेट रज्जुक $(C)$ है।
इसलिए,$A$ प्रमोटर (कोडिंग रज्जुक के $5'$ सिरे पर) को दर्शाता है और $D$ टर्मिनेटर (कोडिंग रज्जुक के $3'$ सिरे पर) को दर्शाता है।
अतः,सही लेबल हैं: $A$ - प्रमोटर,$B$ - कोडिंग रज्जुक,$C$ - टेम्पलेट रज्जुक,$D$ - टर्मिनेटर।
आरेख में दिखाए गए रज्जुक की ध्रुवता के आधार पर:
$5' \rightarrow 3'$ ध्रुवता वाला रज्जुक कोडिंग रज्जुक $(B)$ है।
$3' \rightarrow 5'$ ध्रुवता वाला रज्जुक टेम्पलेट रज्जुक $(C)$ है।
इसलिए,$A$ प्रमोटर (कोडिंग रज्जुक के $5'$ सिरे पर) को दर्शाता है और $D$ टर्मिनेटर (कोडिंग रज्जुक के $3'$ सिरे पर) को दर्शाता है।
अतः,सही लेबल हैं: $A$ - प्रमोटर,$B$ - कोडिंग रज्जुक,$C$ - टेम्पलेट रज्जुक,$D$ - टर्मिनेटर।
0 likes
View Solution254
EasyMCQ
ट्रांसक्रिप्शन यूनिट में एक निश्चित क्रम में इंट्रॉन्स को हटाने की प्रक्रिया को . . . . . . कहा जाता है।
A
टेलिंग
B
स्प्लिसिंग
C
कैपिंग
D
अनुवाद (ट्रांसलेशन)
Solution
(B) यूकेरियोटिक कोशिकाओं में,प्राथमिक ट्रांसक्रिप्ट (pre-mRNA) में कोडिंग अनुक्रम (एक्सॉन्स) और नॉन-कोडिंग अनुक्रम (इंट्रॉन्स) दोनों होते हैं।
स्प्लिसिंग वह पोस्ट-ट्रांसक्रिप्शनल संशोधन प्रक्रिया है जिसमें इंट्रॉन्स को हटा दिया जाता है और एक्सॉन्स को जोड़कर परिपक्व mRNA बनाया जाता है।
टेलिंग का अर्थ $3'$ सिरे पर पॉली-$A$ टेल जोड़ना है।
कैपिंग का अर्थ $5'$ सिरे पर मिथाइलगुआनोसिन ट्राइफॉस्फेट जोड़ना है।
ट्रांसलेशन mRNA से प्रोटीन संश्लेषण की प्रक्रिया है।
स्प्लिसिंग वह पोस्ट-ट्रांसक्रिप्शनल संशोधन प्रक्रिया है जिसमें इंट्रॉन्स को हटा दिया जाता है और एक्सॉन्स को जोड़कर परिपक्व mRNA बनाया जाता है।
टेलिंग का अर्थ $3'$ सिरे पर पॉली-$A$ टेल जोड़ना है।
कैपिंग का अर्थ $5'$ सिरे पर मिथाइलगुआनोसिन ट्राइफॉस्फेट जोड़ना है।
ट्रांसलेशन mRNA से प्रोटीन संश्लेषण की प्रक्रिया है।
0 likes
View Solution255
EasyMCQ
यूकेरियोटिक कोशिकाओं में प्रोटीन संश्लेषण के दौरान निम्नलिखित में से कौन सी प्रक्रिया केंद्रक के अंदर होती है?
A
hnRNA का प्रसंस्करण (Processing)
B
अमीनो एसिड का सक्रियण
C
अनुवाद (Translation)
D
पॉलीपेप्टाइड श्रृंखला का निर्माण
Solution
(A) यूकेरियोटिक कोशिकाओं में,प्रोटीन संश्लेषण में कई चरण शामिल होते हैं।
$1$. अनुलेखन (Transcription) केंद्रक में होता है,जहाँ $DNA$ को हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ में बदला जाता है।
$2$. $hnRNA$ केंद्रक के अंदर अनुलेखन-पश्च संशोधनों (प्रसंस्करण) से गुजरता है,जिसमें स्प्लिसिंग (इंट्रॉन्स को हटाना और एक्सॉन्स को जोड़ना),कैपिंग और टेलिंग (पॉलीएडेनिलेशन) शामिल हैं,जिससे परिपक्व $mRNA$ बनता है।
$3$. इसके बाद परिपक्व $mRNA$ को कोशिका द्रव्य में भेजा जाता है।
$4$. अमीनो एसिड का सक्रियण,अनुवाद और पॉलीपेप्टाइड श्रृंखला का निर्माण कोशिका द्रव्य में राइबोसोम पर होता है।
अतः,$hnRNA$ का प्रसंस्करण ही एकमात्र ऐसी प्रक्रिया है जो केंद्रक के अंदर होती है।
$1$. अनुलेखन (Transcription) केंद्रक में होता है,जहाँ $DNA$ को हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ में बदला जाता है।
$2$. $hnRNA$ केंद्रक के अंदर अनुलेखन-पश्च संशोधनों (प्रसंस्करण) से गुजरता है,जिसमें स्प्लिसिंग (इंट्रॉन्स को हटाना और एक्सॉन्स को जोड़ना),कैपिंग और टेलिंग (पॉलीएडेनिलेशन) शामिल हैं,जिससे परिपक्व $mRNA$ बनता है।
$3$. इसके बाद परिपक्व $mRNA$ को कोशिका द्रव्य में भेजा जाता है।
$4$. अमीनो एसिड का सक्रियण,अनुवाद और पॉलीपेप्टाइड श्रृंखला का निर्माण कोशिका द्रव्य में राइबोसोम पर होता है।
अतः,$hnRNA$ का प्रसंस्करण ही एकमात्र ऐसी प्रक्रिया है जो केंद्रक के अंदर होती है।
0 likes
View Solution256
EasyMCQ
ट्रांसक्रिप्शन इकाई के कोडिंग स्ट्रैंड पर कोडॉन अनुक्रम $ATG \ GTG \ AGC \ TAC \ GCG$ है। टेम्पलेट स्ट्रैंड से बनने वाले $mRNA$ पर कोडॉन अनुक्रम क्या होगा?
A
$ATG \ GTG \ AGC \ TAC \ GCG$
B
$GCG \ TAC \ AGC \ GTG \ ATG$
C
$TAC \ CAC \ TGC \ ATG \ CGC$
D
$AUG \ GUG \ AGC \ UAC \ GCG$
Solution
(D) ट्रांसक्रिप्शन इकाई में,कोडिंग स्ट्रैंड $(5' \rightarrow 3')$ का अनुक्रम $mRNA$ के समान ही होता है,सिवाय इसके कि इसमें $Thymine$ $(T)$ के स्थान पर $Uracil$ $(U)$ होता है।
चूंकि कोडिंग स्ट्रैंड $ATG \ GTG \ AGC \ TAC \ GCG$ है,इसलिए टेम्पलेट स्ट्रैंड से बनने वाले $mRNA$ का अनुक्रम कोडिंग स्ट्रैंड के समान ही होगा,जिसमें $T$ के स्थान पर $U$ प्रतिस्थापित हो जाएगा।
अतः,$mRNA$ का अनुक्रम $AUG \ GUG \ AGC \ UAC \ GCG$ होगा।
चूंकि कोडिंग स्ट्रैंड $ATG \ GTG \ AGC \ TAC \ GCG$ है,इसलिए टेम्पलेट स्ट्रैंड से बनने वाले $mRNA$ का अनुक्रम कोडिंग स्ट्रैंड के समान ही होगा,जिसमें $T$ के स्थान पर $U$ प्रतिस्थापित हो जाएगा।
अतः,$mRNA$ का अनुक्रम $AUG \ GUG \ AGC \ UAC \ GCG$ होगा।
0 likes
View Solution257
EasyMCQ
यूकेरियोटिक $hnRNA$ के प्रसंस्करण में,प्रोटीन संश्लेषण के दौरान टेलिंग में $RNA$ के . . . . . . शामिल हैं।
A
$3'$ सिरे पर एडेनिलेट अवशेषों का जोड़ना
B
$3'$ सिरे पर मिथाइल ग्वानोसिन ट्राइफॉस्फेट का जोड़ना
C
$5'$ सिरे पर मिथाइल ग्वानोसिन ट्राइफॉस्फेट का जोड़ना
D
इंट्रॉन्स को हटाना
Solution
(A) यूकेरियोटिक कोशिकाओं में,प्राथमिक ट्रांसक्रिप्ट $(hnRNA)$ कार्यात्मक $mRNA$ बनने के लिए पोस्ट-ट्रांसक्रिप्शनल संशोधनों से गुजरता है।
$1$. टेलिंग (पॉलीएडेनिलेशन): इस प्रक्रिया में,$200-300$ एडेनिलेट अवशेषों को $hnRNA$ के $3'$ सिरे पर टेम्पलेट-स्वतंत्र तरीके से जोड़ा जाता है।
$2$. कैपिंग: इस प्रक्रिया में,एक असामान्य न्यूक्लियोटाइड,मिथाइल ग्वानोसिन ट्राइफॉस्फेट,को $hnRNA$ के $5'$ सिरे पर जोड़ा जाता है।
$3$. स्प्लिसिंग: इस प्रक्रिया में,नॉन-कोडिंग अनुक्रमों (इंट्रॉन्स) को हटा दिया जाता है और कोडिंग अनुक्रमों (एक्सॉन्स) को एक निश्चित क्रम में जोड़ा जाता है।
इसलिए,टेलिंग में $3'$ सिरे पर एडेनिलेट अवशेषों का जोड़ना शामिल है।
$1$. टेलिंग (पॉलीएडेनिलेशन): इस प्रक्रिया में,$200-300$ एडेनिलेट अवशेषों को $hnRNA$ के $3'$ सिरे पर टेम्पलेट-स्वतंत्र तरीके से जोड़ा जाता है।
$2$. कैपिंग: इस प्रक्रिया में,एक असामान्य न्यूक्लियोटाइड,मिथाइल ग्वानोसिन ट्राइफॉस्फेट,को $hnRNA$ के $5'$ सिरे पर जोड़ा जाता है।
$3$. स्प्लिसिंग: इस प्रक्रिया में,नॉन-कोडिंग अनुक्रमों (इंट्रॉन्स) को हटा दिया जाता है और कोडिंग अनुक्रमों (एक्सॉन्स) को एक निश्चित क्रम में जोड़ा जाता है।
इसलिए,टेलिंग में $3'$ सिरे पर एडेनिलेट अवशेषों का जोड़ना शामिल है।
0 likes
View Solution258
EasyMCQ
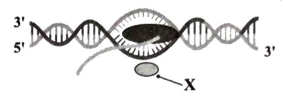
निम्नलिखित आरेख में $X$ क्या दर्शाता है?
A
$RNA$ पॉलीमरेज़
B
$Rho$ कारक
C
$Sigma$ कारक
D
$DNA$ पॉलीमरेज़
Solution
(C) यह आरेख प्रोकैरियोट्स में अनुलेखन (transcription) की प्रक्रिया को दर्शाता है।
प्रोकैरियोटिक अनुलेखन में, $RNA$ पॉलीमरेज़ एंजाइम को $DNA$ टेम्पलेट के प्रमोटर क्षेत्र से जुड़ने के लिए एक विशिष्ट दीक्षा कारक (initiation factor) की आवश्यकता होती है।
इस दीक्षा कारक को $Sigma$ $(\sigma)$ कारक के रूप में जाना जाता है।
जब $Sigma$ कारक $RNA$ पॉलीमरेज़ से जुड़ता है, तो यह प्रमोटर साइट की पहचान करने में मदद करता है और अनुलेखन प्रक्रिया शुरू करता है।
इसलिए, $X$ का अर्थ $Sigma$ कारक है।
प्रोकैरियोटिक अनुलेखन में, $RNA$ पॉलीमरेज़ एंजाइम को $DNA$ टेम्पलेट के प्रमोटर क्षेत्र से जुड़ने के लिए एक विशिष्ट दीक्षा कारक (initiation factor) की आवश्यकता होती है।
इस दीक्षा कारक को $Sigma$ $(\sigma)$ कारक के रूप में जाना जाता है।
जब $Sigma$ कारक $RNA$ पॉलीमरेज़ से जुड़ता है, तो यह प्रमोटर साइट की पहचान करने में मदद करता है और अनुलेखन प्रक्रिया शुरू करता है।
इसलिए, $X$ का अर्थ $Sigma$ कारक है।
0 likes
View Solution259
EasyMCQ
$DNA$ का एक खंड जो पॉलीपेप्टाइड के लिए कोडिंग करता है,ट्रांसक्रिप्शन इकाई में स्थित संरचनात्मक जीन (structural gene) को . . . . . . कहा जाता है।
A
सिस्ट्रॉन (Cistron)
B
ऑक्टामर (Octamer)
C
न्यूक्लियोसोम (Nucleosome)
D
क्रोमैटिन (Chromatin)
Solution
(A) एक ट्रांसक्रिप्शन इकाई में,संरचनात्मक जीन $DNA$ का वह खंड है जो एक पॉलीपेप्टाइड या $RNA$ अणु के लिए कोडिंग करता है।
$DNA$ की इस कार्यात्मक इकाई को जो एक पॉलीपेप्टाइड श्रृंखला को निर्दिष्ट करती है,$Cistron$ (सिस्ट्रॉन) के रूप में जाना जाता है।
$Octamer$ न्यूक्लियोसोम में हिस्टोन प्रोटीन के समूह को संदर्भित करता है।
$Nucleosome$ यूकेरियोट्स में $DNA$ पैकेजिंग की मूल संरचनात्मक इकाई है।
$Chromatin$ $DNA$ और प्रोटीन का एक जटिल समूह है जो गुणसूत्र बनाता है।
अतः,सही उत्तर $A$ है।
$DNA$ की इस कार्यात्मक इकाई को जो एक पॉलीपेप्टाइड श्रृंखला को निर्दिष्ट करती है,$Cistron$ (सिस्ट्रॉन) के रूप में जाना जाता है।
$Octamer$ न्यूक्लियोसोम में हिस्टोन प्रोटीन के समूह को संदर्भित करता है।
$Nucleosome$ यूकेरियोट्स में $DNA$ पैकेजिंग की मूल संरचनात्मक इकाई है।
$Chromatin$ $DNA$ और प्रोटीन का एक जटिल समूह है जो गुणसूत्र बनाता है।
अतः,सही उत्तर $A$ है।
0 likes
View Solution260
EasyMCQ
यदि एक ट्रांसक्रिप्शन यूनिट में कोडिंग स्ट्रैंड का अनुक्रम $5'-ATGCATGCA-3'$ के रूप में लिखा गया है,तो mRNA का अनुक्रम क्या होगा?
A
$ATGCATGCA$
B
$UACGUACGU$
C
$AUGCAUGCA$
D
$TACGTACGT$
Solution
(C) एक ट्रांसक्रिप्शन यूनिट में,कोडिंग स्ट्रैंड (जिसे सेंस स्ट्रैंड भी कहा जाता है) का अनुक्रम mRNA के समान ही होता है,सिवाय इसके कि $DNA$ में मौजूद थाइमिन $(T)$ को $RNA$ में यूरेसिल $(U)$ द्वारा प्रतिस्थापित किया जाता है।
दिया गया कोडिंग स्ट्रैंड: $5'-ATGCATGCA-3'$
$T$ को $U$ से बदलने पर mRNA अनुक्रम प्राप्त होता है: $5'-AUGCAUGCA-3'$।
अतः,सही विकल्प $C$ है।
दिया गया कोडिंग स्ट्रैंड: $5'-ATGCATGCA-3'$
$T$ को $U$ से बदलने पर mRNA अनुक्रम प्राप्त होता है: $5'-AUGCAUGCA-3'$।
अतः,सही विकल्प $C$ है।
0 likes
View Solution261
EasyMCQ
$RNA$ पॉलीमरेज़ $III$ किस $RNA$ के अनुलेखन (transcription) के लिए उत्तरदायी है?
A
$tRNA$
B
$18S$ $rRNA$
C
$mRNA$
D
$hnRNA$
Solution
(A) सुकेन्द्रकी जीवों में,विभिन्न प्रकार के $RNA$ के अनुलेखन के लिए तीन मुख्य प्रकार के $RNA$ पॉलीमरेज़ उत्तरदायी होते हैं:
$1$. $RNA$ पॉलीमरेज़ $I$,$rRNA$ ($28S$,$18S$,और $5.8S$) का अनुलेखन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$,$mRNA$ के पूर्ववर्ती $RNA$ यानी $hnRNA$ (heterogeneous nuclear $RNA$) का अनुलेखन करता है।
$3$. $RNA$ पॉलीमरेज़ $III$,$tRNA$,$5S$ $rRNA$,और $snRNA$ (small nuclear $RNA$) के अनुलेखन के लिए उत्तरदायी है।
अतः,सही विकल्प $A$ है।
$1$. $RNA$ पॉलीमरेज़ $I$,$rRNA$ ($28S$,$18S$,और $5.8S$) का अनुलेखन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$,$mRNA$ के पूर्ववर्ती $RNA$ यानी $hnRNA$ (heterogeneous nuclear $RNA$) का अनुलेखन करता है।
$3$. $RNA$ पॉलीमरेज़ $III$,$tRNA$,$5S$ $rRNA$,और $snRNA$ (small nuclear $RNA$) के अनुलेखन के लिए उत्तरदायी है।
अतः,सही विकल्प $A$ है।
0 likes
View Solution262
EasyMCQ
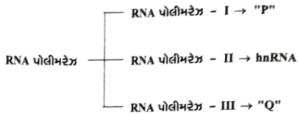
दिए गए चार्ट में '$P$' और '$Q$' क्या दर्शाते हैं?
A
$P = rRNAs (28S, 18S, 5.8S), Q = tRNA, 5S rRNA, snRNAs$
B
$P = mRNA (18S, 28S), Q = rRNA (8.5S, hnRNA)$
C
$P = tRNA, snRNAs, 18S, Q = 28S, 18S, 5.8S$
D
$P = tRNA, 18S, 5.8S, Q = 28S, snRNA, hnRNA$
Solution
(A) सुकेन्द्रकी कोशिकाओं में,तीन मुख्य प्रकार के $RNA$ पॉलीमरेज़ होते हैं,जिनमें से प्रत्येक विशिष्ट प्रकार के $RNA$ के अनुलेखन (transcription) के लिए जिम्मेदार होता है:
$1$. $RNA$ पॉलीमरेज़-$I$,rRNAs $(28S, 18S, 5.8S)$ का अनुलेखन करता है। अतः,'$P$' इन rRNAs को दर्शाता है।
$2$. $RNA$ पॉलीमरेज़-$II$,mRNA के पूर्ववर्ती,यानी hnRNA का अनुलेखन करता है।
$3$. $RNA$ पॉलीमरेज़-$III$,tRNA,$5S$ rRNA और snRNAs के अनुलेखन के लिए जिम्मेदार है। अतः,'$Q$' इन अणुओं को दर्शाता है।
इसलिए,सही विकल्प $A$ है।
$1$. $RNA$ पॉलीमरेज़-$I$,rRNAs $(28S, 18S, 5.8S)$ का अनुलेखन करता है। अतः,'$P$' इन rRNAs को दर्शाता है।
$2$. $RNA$ पॉलीमरेज़-$II$,mRNA के पूर्ववर्ती,यानी hnRNA का अनुलेखन करता है।
$3$. $RNA$ पॉलीमरेज़-$III$,tRNA,$5S$ rRNA और snRNAs के अनुलेखन के लिए जिम्मेदार है। अतः,'$Q$' इन अणुओं को दर्शाता है।
इसलिए,सही विकल्प $A$ है।
0 likes
View Solution263
EasyMCQ
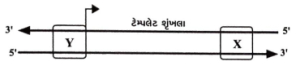
दिए गए आरेख में '$X$' और '$Y$' क्या दर्शाते हैं?
A
$X$ = प्रमोटर,$Y$ = कोडिंग स्ट्रैंड
B
$X$ = प्रमोटर,$Y$ = टर्मिनेटर
C
$X$ = टर्मिनेटर,$Y$ = प्रमोटर
D
$X$ = कोडिंग स्ट्रैंड,$Y$ = टर्मिनेटर
Solution
(C) अनुलेखन (transcription) की प्रक्रिया में,$DNA$ के द्विकुंडलित में विपरीत ध्रुवता ($5' \rightarrow 3'$ और $3' \rightarrow 5'$) वाले दो स्ट्रैंड होते हैं।
प्रमोटर कोडिंग स्ट्रैंड के $5'$ सिरे (अपस्ट्रीम) पर स्थित होता है,जो टेम्पलेट स्ट्रैंड के $3'$ सिरे के अनुरूप होता है।
टर्मिनेटर कोडिंग स्ट्रैंड के $3'$ सिरे (डाउनस्ट्रीम) पर स्थित होता है,जो टेम्पलेट स्ट्रैंड के $5'$ सिरे के अनुरूप होता है।
दिए गए आरेख में,'$X$' कोडिंग स्ट्रैंड के $3'$ सिरे पर है (जो टेम्पलेट स्ट्रैंड का $5'$ सिरा है),इसलिए यह टर्मिनेटर है।
'$Y$' कोडिंग स्ट्रैंड के $5'$ सिरे पर है (जो टेम्पलेट स्ट्रैंड का $3'$ सिरा है),इसलिए यह प्रमोटर है।
अतः,$X = \text{टर्मिनेटर}$ और $Y = \text{प्रमोटर}$।
प्रमोटर कोडिंग स्ट्रैंड के $5'$ सिरे (अपस्ट्रीम) पर स्थित होता है,जो टेम्पलेट स्ट्रैंड के $3'$ सिरे के अनुरूप होता है।
टर्मिनेटर कोडिंग स्ट्रैंड के $3'$ सिरे (डाउनस्ट्रीम) पर स्थित होता है,जो टेम्पलेट स्ट्रैंड के $5'$ सिरे के अनुरूप होता है।
दिए गए आरेख में,'$X$' कोडिंग स्ट्रैंड के $3'$ सिरे पर है (जो टेम्पलेट स्ट्रैंड का $5'$ सिरा है),इसलिए यह टर्मिनेटर है।
'$Y$' कोडिंग स्ट्रैंड के $5'$ सिरे पर है (जो टेम्पलेट स्ट्रैंड का $3'$ सिरा है),इसलिए यह प्रमोटर है।
अतः,$X = \text{टर्मिनेटर}$ और $Y = \text{प्रमोटर}$।
0 likes
View Solution264
EasyMCQ
प्रोकैरियोटिक जीनोम के संदर्भ में निम्नलिखित में से कौन से कथन सही हैं?
$A$. मोनोसिस्ट्रोनिक संरचनात्मक जीन
$B$. संरचनात्मक जीन में इंट्रॉन्स अनुपस्थित होते हैं
$C$. ट्रांसक्रिप्शन और ट्रांसलेशन युग्मित प्रक्रियाएं हैं
$D$. प्राथमिक ट्रांसक्रिप्ट स्प्लिसिंग से गुजरता है
$E$. केवल एक $RNA$ पॉलीमरेज़ उपस्थित होता है
$A$. मोनोसिस्ट्रोनिक संरचनात्मक जीन
$B$. संरचनात्मक जीन में इंट्रॉन्स अनुपस्थित होते हैं
$C$. ट्रांसक्रिप्शन और ट्रांसलेशन युग्मित प्रक्रियाएं हैं
$D$. प्राथमिक ट्रांसक्रिप्ट स्प्लिसिंग से गुजरता है
$E$. केवल एक $RNA$ पॉलीमरेज़ उपस्थित होता है
A
केवल $A, D$ और $E$ सही हैं
B
केवल $A, D$ और $E$ सही नहीं हैं
C
केवल $A, B$ और $D$ सही हैं
D
केवल $B, C$ और $E$ सही हैं
Solution
(D) प्रोकैरियोट्स में:
$A$. प्रोकैरियोटिक संरचनात्मक जीन आमतौर पर पॉलीसिस्ट्रोनिक होते हैं,मोनोसिस्ट्रोनिक नहीं। अतः,कथन $A$ गलत है।
$B$. प्रोकैरियोटिक जीन में इंट्रॉन्स (नॉन-कोडिंग अनुक्रम) नहीं होते हैं। अतः,कथन $B$ सही है।
$C$. केंद्रक झिल्ली के अभाव के कारण,ट्रांसक्रिप्शन और ट्रांसलेशन एक ही कोशिका द्रव्य में होते हैं और ये युग्मित प्रक्रियाएं हैं। अतः,कथन $C$ सही है।
$D$. स्प्लिसिंग एक ऐसी प्रक्रिया है जो यूकेरियोटिक pre-mRNA से इंट्रॉन्स को हटाने के लिए आवश्यक है। चूंकि प्रोकैरियोट्स में इंट्रॉन्स नहीं होते हैं,इसलिए उनमें स्प्लिसिंग नहीं होती है। अतः,कथन $D$ गलत है।
$E$. प्रोकैरियोट्स में केवल एक ही प्रकार का $RNA$ पॉलीमरेज़ होता है जो सभी प्रकार के $RNA$ $(mRNA, tRNA, rRNA)$ का ट्रांसक्रिप्शन करता है। अतः,कथन $E$ सही है।
इसलिए,कथन $B, C$ और $E$ सही हैं।
$A$. प्रोकैरियोटिक संरचनात्मक जीन आमतौर पर पॉलीसिस्ट्रोनिक होते हैं,मोनोसिस्ट्रोनिक नहीं। अतः,कथन $A$ गलत है।
$B$. प्रोकैरियोटिक जीन में इंट्रॉन्स (नॉन-कोडिंग अनुक्रम) नहीं होते हैं। अतः,कथन $B$ सही है।
$C$. केंद्रक झिल्ली के अभाव के कारण,ट्रांसक्रिप्शन और ट्रांसलेशन एक ही कोशिका द्रव्य में होते हैं और ये युग्मित प्रक्रियाएं हैं। अतः,कथन $C$ सही है।
$D$. स्प्लिसिंग एक ऐसी प्रक्रिया है जो यूकेरियोटिक pre-mRNA से इंट्रॉन्स को हटाने के लिए आवश्यक है। चूंकि प्रोकैरियोट्स में इंट्रॉन्स नहीं होते हैं,इसलिए उनमें स्प्लिसिंग नहीं होती है। अतः,कथन $D$ गलत है।
$E$. प्रोकैरियोट्स में केवल एक ही प्रकार का $RNA$ पॉलीमरेज़ होता है जो सभी प्रकार के $RNA$ $(mRNA, tRNA, rRNA)$ का ट्रांसक्रिप्शन करता है। अतः,कथन $E$ सही है।
इसलिए,कथन $B, C$ और $E$ सही हैं।
0 likes
View Solution265
EasyMCQ
यूकेरियोटिक जीन मोनोसिस्ट्रोनिक होते हैं,लेकिन उन्हें 'स्प्लिट जीन' (split genes) माना जाता है क्योंकि:
A
इंट्रॉन्स,म्यूटॉन्स द्वारा बाधित होते हैं।
B
उनमें केवल एक्सॉन्स होते हैं।
C
उनमें केवल इंट्रॉन्स होते हैं।
D
एक्सॉन्स,इंट्रॉन्स द्वारा बाधित होते हैं।
Solution
(D) सही उत्तर $D$ है।
यूकेरियोट्स में,मोनोसिस्ट्रोनिक संरचनात्मक जीन में कोडिंग अनुक्रम बाधित होते हैं,इसीलिए उन्हें 'स्प्लिट जीन' कहा जाता है।
कोडिंग अनुक्रमों या अभिव्यक्त अनुक्रमों को $Exons$ के रूप में परिभाषित किया गया है।
$Exons$ वे अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई देते हैं।
ये $Exons$ गैर-कोडिंग अनुक्रमों द्वारा बाधित होते हैं जिन्हें $Introns$ कहा जाता है।
यूकेरियोट्स में,मोनोसिस्ट्रोनिक संरचनात्मक जीन में कोडिंग अनुक्रम बाधित होते हैं,इसीलिए उन्हें 'स्प्लिट जीन' कहा जाता है।
कोडिंग अनुक्रमों या अभिव्यक्त अनुक्रमों को $Exons$ के रूप में परिभाषित किया गया है।
$Exons$ वे अनुक्रम हैं जो परिपक्व या संसाधित $RNA$ में दिखाई देते हैं।
ये $Exons$ गैर-कोडिंग अनुक्रमों द्वारा बाधित होते हैं जिन्हें $Introns$ कहा जाता है।
0 likes
View Solution266
EasyMCQ
$RNA$ polymerase $II$ . . . . . . के अनुलेखन (transcription) के लिए उत्तरदायी है।
A
hnRNA
B
snRNA
C
tRNA
D
rRNA
Solution
(A) सही उत्तर $A$ (hnRNA) है।
सुकेन्द्रकी (eukaryotes) जीवों में,केंद्रक में तीन प्रकार के $RNA$ पॉलीमरेज़ होते हैं।
$1$. $RNA$ पॉलीमरेज़ $I$,$rRNA$ ($28S, 18S,$ और $5.8S$) का अनुलेखन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$,$mRNA$ के पूर्ववर्ती (precursor) का अनुलेखन करता है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ के रूप में जाना जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$,$tRNA$,$5S$ $rRNA$,और $snRNA$ (स्मॉल न्यूक्लियर $RNA$) के अनुलेखन के लिए उत्तरदायी है।
सुकेन्द्रकी (eukaryotes) जीवों में,केंद्रक में तीन प्रकार के $RNA$ पॉलीमरेज़ होते हैं।
$1$. $RNA$ पॉलीमरेज़ $I$,$rRNA$ ($28S, 18S,$ और $5.8S$) का अनुलेखन करता है।
$2$. $RNA$ पॉलीमरेज़ $II$,$mRNA$ के पूर्ववर्ती (precursor) का अनुलेखन करता है,जिसे हेटेरोजेनस न्यूक्लियर $RNA$ $(hnRNA)$ के रूप में जाना जाता है।
$3$. $RNA$ पॉलीमरेज़ $III$,$tRNA$,$5S$ $rRNA$,और $snRNA$ (स्मॉल न्यूक्लियर $RNA$) के अनुलेखन के लिए उत्तरदायी है।
0 likes
View Solution267
EasyMCQ
अनुलेखन (Transcription) के दौरान,संरचनात्मक जीन (Structural gene) की $3' \rightarrow 5'$ ध्रुवता वाली $DNA$ रज्जुक हमेशा टेम्पलेट के रूप में कार्य करती है क्योंकि
A
$DNA$ रज्जुक के $5' \rightarrow 3'$ न्यूक्लियोटाइड्स $mRNA$ में स्थानांतरित होते हैं।
B
एंजाइम $DNA$ निर्भर $RNA$ पॉलीमरेज हमेशा $5' \rightarrow 3'$ दिशा में बहुलकीकरण (polymerisation) को उत्प्रेरित करता है।
C
एंजाइम $DNA$ निर्भर $RNA$ पॉलीमरेज हमेशा $3' \rightarrow 5'$ दिशा में बहुलकीकरण को उत्प्रेरित करता है।
D
एंजाइम $DNA$ निर्भर $RNA$ पॉलीमरेज हमेशा दोनों दिशाओं में बहुलकीकरण को उत्प्रेरित करता है।
Solution
(B) अनुलेखन की प्रक्रिया के दौरान,$DNA$ निर्भर $RNA$ पॉलीमरेज एंजाइम $RNA$ के संश्लेषण के लिए जिम्मेदार होता है।
इस एंजाइम की एक सख्त आवश्यकता होती है कि यह न्यूक्लियोटाइड्स के बहुलकीकरण को केवल $5' \rightarrow 3'$ दिशा में ही उत्प्रेरित कर सकता है।
चूंकि $DNA$ के दो रज्जुक प्रतिसमांतर (Antiparallel) होते हैं,इसलिए जो रज्जुक $3' \rightarrow 5'$ दिशा में चलता है,वह टेम्पलेट के रूप में कार्य करता है।
यह नव-संश्लेषित $RNA$ रज्जुक को $5' \rightarrow 3'$ दिशा में बनने की अनुमति देता है,जो टेम्पलेट रज्जुक के पूरक और प्रतिसमांतर होता है।
इस एंजाइम की एक सख्त आवश्यकता होती है कि यह न्यूक्लियोटाइड्स के बहुलकीकरण को केवल $5' \rightarrow 3'$ दिशा में ही उत्प्रेरित कर सकता है।
चूंकि $DNA$ के दो रज्जुक प्रतिसमांतर (Antiparallel) होते हैं,इसलिए जो रज्जुक $3' \rightarrow 5'$ दिशा में चलता है,वह टेम्पलेट के रूप में कार्य करता है।
यह नव-संश्लेषित $RNA$ रज्जुक को $5' \rightarrow 3'$ दिशा में बनने की अनुमति देता है,जो टेम्पलेट रज्जुक के पूरक और प्रतिसमांतर होता है।
0 likes
View Solution268
EasyMCQ
यदि $DNA$ के टेम्पलेट स्ट्रैंड में न्यूक्लियोटाइड का अनुक्रम $3'-ATGCTTCCGAAT-5'$ है,तो ट्रांसक्राइब किए गए mRNA के संबंधित क्षेत्र में अनुक्रम लिखिए।
A
$5'-UACGAAGGCCUA-3'$
B
$5'-UACGAAGGCCUU-3'$
C
$3'-UACGAAGGCCUA-5'$
D
$5'-TACGAAGGCCTT-3'$
Solution
(B) अनुलेखन (Transcription) के दौरान,$RNA$ पॉलीमरेज़ एंजाइम $DNA$ टेम्पलेट स्ट्रैंड का उपयोग करके mRNA का संश्लेषण करता है।
पूरकता के सिद्धांत के अनुसार,mRNA में नाइट्रोजनस बेस $DNA$ के टेम्पलेट स्ट्रैंड के पूरक होते हैं।
$DNA$ में,एडेनिन $(A)$ थाइमिन $(T)$ के साथ जुड़ता है,और साइटोसिन $(C)$ ग्वानिन $(G)$ के साथ जुड़ता है।
हालाँकि,$RNA$ में,थाइमिन $(T)$ के स्थान पर यूरेसिल $(U)$ आ जाता है।
इसलिए,अनुलेखन के लिए बेस पेयरिंग का नियम इस प्रकार है:
$A$ $(DNA)$ $\rightarrow$ $U$ (mRNA)
$T$ $(DNA)$ $\rightarrow$ $A$ (mRNA)
$C$ $(DNA)$ $\rightarrow$ $G$ (mRNA)
$G$ $(DNA)$ $\rightarrow$ $C$ (mRNA)
दिया गया $DNA$ टेम्पलेट स्ट्रैंड: $3'-ATGCTTCCGAAT-5'$
पूरक mRNA अनुक्रम: $5'-UACGAAGGCCUU-3'$
अतः,सही विकल्प $B$ है।
पूरकता के सिद्धांत के अनुसार,mRNA में नाइट्रोजनस बेस $DNA$ के टेम्पलेट स्ट्रैंड के पूरक होते हैं।
$DNA$ में,एडेनिन $(A)$ थाइमिन $(T)$ के साथ जुड़ता है,और साइटोसिन $(C)$ ग्वानिन $(G)$ के साथ जुड़ता है।
हालाँकि,$RNA$ में,थाइमिन $(T)$ के स्थान पर यूरेसिल $(U)$ आ जाता है।
इसलिए,अनुलेखन के लिए बेस पेयरिंग का नियम इस प्रकार है:
$A$ $(DNA)$ $\rightarrow$ $U$ (mRNA)
$T$ $(DNA)$ $\rightarrow$ $A$ (mRNA)
$C$ $(DNA)$ $\rightarrow$ $G$ (mRNA)
$G$ $(DNA)$ $\rightarrow$ $C$ (mRNA)
दिया गया $DNA$ टेम्पलेट स्ट्रैंड: $3'-ATGCTTCCGAAT-5'$
पूरक mRNA अनुक्रम: $5'-UACGAAGGCCUU-3'$
अतः,सही विकल्प $B$ है।
0 likes
View Solution269
EasyMCQ
$DNA$ के दिए गए अनुक्रम के लिए,नीचे दिए गए विकल्पों में से इसके $mRNA$ पर पूरक क्षार अनुक्रम की पहचान करें।
$DNA$ $3'-ATGCATGCATGC-5'$
$DNA$ $3'-ATGCATGCATGC-5'$
A
$5'-GCATGCATGCAT-3'$
B
$5'-UACGUACGUACG-3'$
C
$5'-TACGTACGTACG-3'$
D
$3'-UACGUACGUACG-5'$
Solution
(B) अनुलेखन (Transcription) की प्रक्रिया में $DNA$ टेम्पलेट रज्जुक से $mRNA$ का संश्लेषण होता है।
इस प्रक्रिया के दौरान,क्षार युग्मन के नियम इस प्रकार हैं: $A$ (एडेनिन) $U$ (यूरेसिल) के साथ,$T$ (थाइमिन) $A$ (एडेनिन) के साथ,$G$ (ग्वानिन) $C$ (साइटोसिन) के साथ और $C$ (साइटोसिन) $G$ (ग्वानिन) के साथ जुड़ता है।
दिया गया $DNA$ टेम्पलेट: $3'-ATGCATGCATGC-5'$.
क्षार युग्मन नियमों को लागू करने पर:
$A \rightarrow U$
$T \rightarrow A$
$G \rightarrow C$
$C \rightarrow G$
इस प्रकार,पूरक $mRNA$ अनुक्रम $5'-UACGUACGUACG-3'$ है।
अतः,सही विकल्प $(B)$ है।
इस प्रक्रिया के दौरान,क्षार युग्मन के नियम इस प्रकार हैं: $A$ (एडेनिन) $U$ (यूरेसिल) के साथ,$T$ (थाइमिन) $A$ (एडेनिन) के साथ,$G$ (ग्वानिन) $C$ (साइटोसिन) के साथ और $C$ (साइटोसिन) $G$ (ग्वानिन) के साथ जुड़ता है।
दिया गया $DNA$ टेम्पलेट: $3'-ATGCATGCATGC-5'$.
क्षार युग्मन नियमों को लागू करने पर:
$A \rightarrow U$
$T \rightarrow A$
$G \rightarrow C$
$C \rightarrow G$
इस प्रकार,पूरक $mRNA$ अनुक्रम $5'-UACGUACGUACG-3'$ है।
अतः,सही विकल्प $(B)$ है।
0 likes
View Solution270
EasyMCQ
सुकेन्द्रकी (eukaryotes) जीवों में,एक जीन का पूरा क्षार अनुक्रम परिपक्व $RNA$ में दिखाई नहीं देता है क्योंकि
A
कुछ जीन अनुक्रम एक्सोन्यूक्लिएज द्वारा हटा दिए जाते हैं
B
सुकेन्द्रकी जीवों में अनुलेखन (transcription) में अधिक ऊर्जा खर्च होती है।
C
प्रक्रिया के दौरान कोडिंग अनुक्रम हटा दिए जाते हैं।
D
प्रसंस्करण (processing) के दौरान इंट्रॉन्स हटा दिए जाते हैं।
Solution
(D) सही उत्तर $D$ है।
सुकेन्द्रकी कोशिकाओं में,प्राथमिक ट्रांसक्रिप्ट (pre-mRNA) में कोडिंग अनुक्रम जिन्हें एक्सॉन कहा जाता है और गैर-कोडिंग अनुक्रम जिन्हें इंट्रॉन्स कहा जाता है,दोनों मौजूद होते हैं।
$RNA$ प्रसंस्करण या अनुलेखन-पश्चात संशोधन की प्रक्रिया के दौरान,गैर-कोडिंग इंट्रॉन्स को हटा दिया जाता है और एक्सॉन्स को एक विशिष्ट क्रम में जोड़ा जाता है।
इस प्रक्रिया को स्प्लिसिंग (splicing) के रूप में जाना जाता है,जिसके परिणामस्वरूप परिपक्व और कार्यात्मक mRNA का निर्माण होता है।
सुकेन्द्रकी कोशिकाओं में,प्राथमिक ट्रांसक्रिप्ट (pre-mRNA) में कोडिंग अनुक्रम जिन्हें एक्सॉन कहा जाता है और गैर-कोडिंग अनुक्रम जिन्हें इंट्रॉन्स कहा जाता है,दोनों मौजूद होते हैं।
$RNA$ प्रसंस्करण या अनुलेखन-पश्चात संशोधन की प्रक्रिया के दौरान,गैर-कोडिंग इंट्रॉन्स को हटा दिया जाता है और एक्सॉन्स को एक विशिष्ट क्रम में जोड़ा जाता है।
इस प्रक्रिया को स्प्लिसिंग (splicing) के रूप में जाना जाता है,जिसके परिणामस्वरूप परिपक्व और कार्यात्मक mRNA का निर्माण होता है।
0 likes
View Solution271
EasyMCQ
प्रोकैरियोट्स में, $DNA$ का अनुलेखन (transcription) किसकी सहायता से शुरू होता है?
A
rho कारक
B
elongation कारक
C
sigma कारक
D
termination कारक
Solution
(C) सही उत्तर $C$ है।
प्रोकैरियोट्स में, अनुलेखन की प्रक्रिया $DNA$-निर्भर $RNA$ पॉलीमरेज़ द्वारा उत्प्रेरित होती है।
इस एंजाइम को $DNA$ टेम्पलेट पर प्रमोटर क्षेत्र को पहचानने के लिए $\sigma$ कारक नामक एक विशिष्ट प्रारंभिक कारक की आवश्यकता होती है।
जब $\sigma$ कारक $RNA$ पॉलीमरेज़ से जुड़ता है, तो यह एंजाइम को प्रमोटर के साथ जुड़ने में मदद करता है, जिससे अनुलेखन प्रक्रिया शुरू हो जाती है।
प्रारंभ होने के बाद, $\sigma$ कारक अलग हो जाता है और मुख्य एंजाइम दीर्घीकरण (elongation) की प्रक्रिया को जारी रखता है।
प्रोकैरियोट्स में, अनुलेखन की प्रक्रिया $DNA$-निर्भर $RNA$ पॉलीमरेज़ द्वारा उत्प्रेरित होती है।
इस एंजाइम को $DNA$ टेम्पलेट पर प्रमोटर क्षेत्र को पहचानने के लिए $\sigma$ कारक नामक एक विशिष्ट प्रारंभिक कारक की आवश्यकता होती है।
जब $\sigma$ कारक $RNA$ पॉलीमरेज़ से जुड़ता है, तो यह एंजाइम को प्रमोटर के साथ जुड़ने में मदद करता है, जिससे अनुलेखन प्रक्रिया शुरू हो जाती है।
प्रारंभ होने के बाद, $\sigma$ कारक अलग हो जाता है और मुख्य एंजाइम दीर्घीकरण (elongation) की प्रक्रिया को जारी रखता है।
0 likes
View Solution272
EasyMCQ
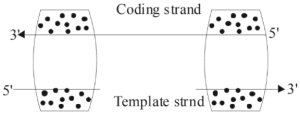
दिए गए अनुलेखन (transcription) इकाई में,क्रमशः $I$ और $II$ क्षेत्रों की पहचान करें।
A
प्रमोटर और टर्मिनेटर
B
Rho कारक और सिग्मा कारक
C
टर्मिनेटर और प्रमोटर
D
ऑपरेटर और इनहिबिटर
Solution
(A) सही उत्तर $(A)$ है।
एक अनुलेखन इकाई में,प्रमोटर कोडिंग स्ट्रैंड के $5'$-सिरे (अपस्ट्रीम) पर स्थित होता है,जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे (डाउनस्ट्रीम) पर स्थित होता है,जो अनुलेखन प्रक्रिया के अंत का संकेत देता है।
दिए गए आरेख के आधार पर,क्षेत्र $I$ प्रमोटर का प्रतिनिधित्व करता है और क्षेत्र $II$ टर्मिनेटर का प्रतिनिधित्व करता है।
एक अनुलेखन इकाई में,प्रमोटर कोडिंग स्ट्रैंड के $5'$-सिरे (अपस्ट्रीम) पर स्थित होता है,जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे (डाउनस्ट्रीम) पर स्थित होता है,जो अनुलेखन प्रक्रिया के अंत का संकेत देता है।
दिए गए आरेख के आधार पर,क्षेत्र $I$ प्रमोटर का प्रतिनिधित्व करता है और क्षेत्र $II$ टर्मिनेटर का प्रतिनिधित्व करता है।
0 likes
View Solution273
EasyMCQ
$RNA$ पॉलीमरेज़-$I$ सुकेंद्रकी राइबोसोमल $RNA$ का अनुलेखन करता है,जिसमें निम्नलिखित में से क्या शामिल नहीं होता है ($S$ $rRNA$ में)?
A
$5.8$
B
$28$
C
$18$
D
$5$
Solution
(D) सुकेंद्रकी (eukaryotes) जीवों में,$RNA$ पॉलीमरेज़-$I$ $rRNA$ जीनों के अनुलेखन के लिए उत्तरदायी होता है,जिसमें मुख्य रूप से $28S$,$18S$ और $5.8S$ $rRNA$ शामिल होते हैं।
$5S$ $rRNA$ का अनुलेखन $RNA$ पॉलीमरेज़-$III$ द्वारा किया जाता है।
अतः,सही विकल्प $(D)$ है।
$5S$ $rRNA$ का अनुलेखन $RNA$ पॉलीमरेज़-$III$ द्वारा किया जाता है।
अतः,सही विकल्प $(D)$ है।
0 likes
View Solution274
EasyMCQ
$Statement A$: सुकेंद्रकी (eukaryotes) में उत्पन्न प्राथमिक ट्रांसक्रिप्ट बिना किसी संशोधन या प्रसंस्करण के अनुवादित (translated) होता है।
$Statement B$: मनुष्यों में $hnRNA$ में एक्सॉन और इंट्रॉन होते हैं।
$Statement B$: मनुष्यों में $hnRNA$ में एक्सॉन और इंट्रॉन होते हैं।
A
$Statement B$ सही है और $Statement A$ गलत है।
B
दोनों कथन $A$ और $B$ सही हैं।
C
$Statement A$ सही है और $Statement B$ गलत है।
D
दोनों कथन $A$ और $B$ गलत हैं।
Solution
(A) $Statement B$ सही है और $Statement A$ गलत है।
सुकेंद्रकी जीवों में,प्राथमिक ट्रांसक्रिप्ट (pre-$mRNA$) अनुवादित होने से पहले स्प्लिसिंग,कैपिंग और टेलिंग जैसे महत्वपूर्ण अनुलेखन-पश्च संशोधनों से गुजरता है।
$Statement A$ गलत है क्योंकि प्राथमिक ट्रांसक्रिप्ट सीधे अनुवादित नहीं होता है।
$Statement B$ सही है क्योंकि $hnRNA$ (heterogeneous nuclear $RNA$) में कोडिंग अनुक्रम (एक्सॉन) और नॉन-कोडिंग अनुक्रम (इंट्रॉन) दोनों होते हैं,जिन्हें स्प्लिसिंग के माध्यम से हटाना आवश्यक होता है।
सुकेंद्रकी जीवों में,प्राथमिक ट्रांसक्रिप्ट (pre-$mRNA$) अनुवादित होने से पहले स्प्लिसिंग,कैपिंग और टेलिंग जैसे महत्वपूर्ण अनुलेखन-पश्च संशोधनों से गुजरता है।
$Statement A$ गलत है क्योंकि प्राथमिक ट्रांसक्रिप्ट सीधे अनुवादित नहीं होता है।
$Statement B$ सही है क्योंकि $hnRNA$ (heterogeneous nuclear $RNA$) में कोडिंग अनुक्रम (एक्सॉन) और नॉन-कोडिंग अनुक्रम (इंट्रॉन) दोनों होते हैं,जिन्हें स्प्लिसिंग के माध्यम से हटाना आवश्यक होता है।
0 likes
View Solution275
EasyMCQ
कथन $A$ और $B$ की तुलना कीजिए।
कथन $A$: सुकेंद्रकी (eukaryotic) कोशिकाओं में अनुलेखन (transcription) के दौरान उत्पादित $RNA$ का सीधे स्थानांतरण (translation) में उपयोग नहीं किया जा सकता है।
कथन $B$: $RNA$ स्प्लिसिंग की घटना एक्सॉन को हटाने में मदद करती है।
सही विवरण चुनिए।
कथन $A$: सुकेंद्रकी (eukaryotic) कोशिकाओं में अनुलेखन (transcription) के दौरान उत्पादित $RNA$ का सीधे स्थानांतरण (translation) में उपयोग नहीं किया जा सकता है।
कथन $B$: $RNA$ स्प्लिसिंग की घटना एक्सॉन को हटाने में मदद करती है।
सही विवरण चुनिए।
A
दोनों कथन $A$ और $B$ गलत हैं।
B
दोनों कथन $A$ और $B$ सही हैं।
C
कथन $A$ सही है और $B$ गलत है।
D
कथन $A$ गलत है और $B$ सही है।
Solution
(C) कथन $A$ सही है और $B$ गलत है।
सुकेंद्रकी कोशिकाओं में अनुलेखन के दौरान उत्पादित प्राथमिक ट्रांसक्रिप्ट $(pre-mRNA)$ को स्थानांतरण के लिए कार्यात्मक $mRNA$ बनने हेतु कैपिंग,पॉलीएडिनिलेशन और स्प्लिसिंग जैसे पोस्ट-ट्रांसक्रिप्शनल संशोधनों से गुजरना पड़ता है। इसका सीधे उपयोग नहीं किया जाता है।
कथन $B$ गलत है क्योंकि $RNA$ स्प्लिसिंग इंट्रॉन (नॉन-कोडिंग अनुक्रम) को हटाने और एक्सॉन (कोडिंग अनुक्रम) को जोड़कर परिपक्व $mRNA$ बनाने की प्रक्रिया है। एक्सॉन को हटाया नहीं जाता है; वे बने रहते हैं।
सुकेंद्रकी कोशिकाओं में अनुलेखन के दौरान उत्पादित प्राथमिक ट्रांसक्रिप्ट $(pre-mRNA)$ को स्थानांतरण के लिए कार्यात्मक $mRNA$ बनने हेतु कैपिंग,पॉलीएडिनिलेशन और स्प्लिसिंग जैसे पोस्ट-ट्रांसक्रिप्शनल संशोधनों से गुजरना पड़ता है। इसका सीधे उपयोग नहीं किया जाता है।
कथन $B$ गलत है क्योंकि $RNA$ स्प्लिसिंग इंट्रॉन (नॉन-कोडिंग अनुक्रम) को हटाने और एक्सॉन (कोडिंग अनुक्रम) को जोड़कर परिपक्व $mRNA$ बनाने की प्रक्रिया है। एक्सॉन को हटाया नहीं जाता है; वे बने रहते हैं।
0 likes
View Solution276
EasyMCQ
$DNA$ के एक कोडिंग खंड के एक भाग में नाइट्रोजन बेस का अनुक्रम $AAT GCT TAG GCA$ है। तो इसके संगत ट्रांसक्रिप्टेड $mRNA$ के भाग में नाइट्रोजन बेस का अनुक्रम क्या होगा?
A
$AAT GCT TAG GCA$
B
$UUT CGT TUC CGU$
C
$TTA CGA ATC CGT$
D
$UUA CGA AUC CGU$
Solution
(D) $DNA$ की कोडिंग स्ट्रैंड $mRNA$ के समान होती है, केवल $Thymine (T)$ के स्थान पर $Uracil (U)$ होता है।
यदि दिया गया अनुक्रम टेम्पलेट स्ट्रैंड का है, तो $mRNA$ का अनुक्रम पूरक (complementary) होगा।
$DNA$ टेम्पलेट: $AAT GCT TAG GCA$
$mRNA$ पूरक: $UUA CGA AUC CGU$
अतः, सही विकल्प $D$ है।
यदि दिया गया अनुक्रम टेम्पलेट स्ट्रैंड का है, तो $mRNA$ का अनुक्रम पूरक (complementary) होगा।
$DNA$ टेम्पलेट: $AAT GCT TAG GCA$
$mRNA$ पूरक: $UUA CGA AUC CGU$
अतः, सही विकल्प $D$ है।
0 likes
View Solution277
MediumMCQ
ट्रांसक्रिप्शन यूनिट के संदर्भ में निम्नलिखित में से कौन से कथन सही हैं?
$A$. $DNA$ में एक ट्रांसक्रिप्शन यूनिट मुख्य रूप से तीन क्षेत्रों द्वारा परिभाषित होती है: प्रमोटर,स्ट्रक्चरल जीन और टर्मिनेटर।
$B$. प्रमोटर स्ट्रक्चरल जीन के $5'$-सिरे की ओर स्थित होता है।
$C$. प्रमोटर एक $DNA$ अनुक्रम है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
$D$. प्रमोटर टेम्पलेट और कोडिंग स्ट्रैंड को परिभाषित करता है।
$E$. टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे की ओर स्थित होता है और यह ट्रांसक्रिप्शन की प्रक्रिया के अंत को परिभाषित करता है।
नीचे दिए गए विकल्पों में से सही उत्तर चुनें:
$A$. $DNA$ में एक ट्रांसक्रिप्शन यूनिट मुख्य रूप से तीन क्षेत्रों द्वारा परिभाषित होती है: प्रमोटर,स्ट्रक्चरल जीन और टर्मिनेटर।
$B$. प्रमोटर स्ट्रक्चरल जीन के $5'$-सिरे की ओर स्थित होता है।
$C$. प्रमोटर एक $DNA$ अनुक्रम है जो $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
$D$. प्रमोटर टेम्पलेट और कोडिंग स्ट्रैंड को परिभाषित करता है।
$E$. टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे की ओर स्थित होता है और यह ट्रांसक्रिप्शन की प्रक्रिया के अंत को परिभाषित करता है।
नीचे दिए गए विकल्पों में से सही उत्तर चुनें:
A
$(1)$ केवल $B, C, D$ और $E$
B
$(2)$ $A, B, C, D$ और $E$
C
$(3)$ केवल $A, B, C$ और $D$
D
$(4)$ केवल $A, C, D$ और $E$
Solution
(B) दिए गए सभी कथन आणविक जीव विज्ञान (molecular biology) में ट्रांसक्रिप्शन यूनिट से संबंधित मानक परिभाषाएँ हैं।
$A$. $DNA$ में एक ट्रांसक्रिप्शन यूनिट प्रमोटर,स्ट्रक्चरल जीन और टर्मिनेटर द्वारा परिभाषित होती है।
$B$. प्रमोटर स्ट्रक्चरल जीन के $5'$-सिरे (अपस्ट्रीम) पर स्थित होता है।
$C$. यह ट्रांसक्रिप्शन शुरू करने के लिए $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
$D$. अपनी स्थिति के माध्यम से,प्रमोटर यह निर्धारित करता है कि $DNA$ की कौन सी श्रृंखला टेम्पलेट स्ट्रैंड के रूप में और कौन सी कोडिंग स्ट्रैंड के रूप में कार्य करेगी।
$E$. टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे पर स्थित होता है और यह ट्रांसक्रिप्शन प्रक्रिया के अंत का संकेत देता है।
चूंकि सभी कथन $A, B, C, D$ और $E$ सही हैं,इसलिए विकल्प $(2)$ सही उत्तर है।
$A$. $DNA$ में एक ट्रांसक्रिप्शन यूनिट प्रमोटर,स्ट्रक्चरल जीन और टर्मिनेटर द्वारा परिभाषित होती है।
$B$. प्रमोटर स्ट्रक्चरल जीन के $5'$-सिरे (अपस्ट्रीम) पर स्थित होता है।
$C$. यह ट्रांसक्रिप्शन शुरू करने के लिए $RNA$ पॉलीमरेज़ के लिए बाइंडिंग साइट प्रदान करता है।
$D$. अपनी स्थिति के माध्यम से,प्रमोटर यह निर्धारित करता है कि $DNA$ की कौन सी श्रृंखला टेम्पलेट स्ट्रैंड के रूप में और कौन सी कोडिंग स्ट्रैंड के रूप में कार्य करेगी।
$E$. टर्मिनेटर कोडिंग स्ट्रैंड के $3'$-सिरे पर स्थित होता है और यह ट्रांसक्रिप्शन प्रक्रिया के अंत का संकेत देता है।
चूंकि सभी कथन $A, B, C, D$ और $E$ सही हैं,इसलिए विकल्प $(2)$ सही उत्तर है।
0 likes
View SolutionMolecular Basis of Inheritance — Transcription · Frequently Asked Questions
1Are these Molecular Basis of Inheritance questions useful for JEE and NEET?
Yes. All questions in this section are mapped to JEE Main and NEET exam patterns. Previous year questions from JEE Main, NEET, GUJCET and state-level exams are included with full solutions.
2Can I switch to Hindi or Gujarati for these questions?
Yes. Use the language tabs in the hero section or the sidebar to view the same questions and solutions in English, Hindi or Gujarati.
3How do I generate a question paper from this subtopic?
Use the Vedclass Exam Paper Generator — select the chapter and subtopic, set difficulty, and generate Sets A, B, C, D automatically. First 3 chapters of every subject are free.
Vedclass Products
For Students
Vedclass Test Series
Mock tests in real JEE/NEET style with performance analysis. 5-day free trial.
Start Free TrialFor Teachers
Exam Paper Generator
Generate Set A/B/C/D papers from this chapter in 2 minutes. 3 chapters free.
Try FreeFor Institutes
Online Exam Module
Live online exams with unlimited students, 360° analytics & white-label branding.
See DemoFor Teachers & Institutes
Generate a Molecular Basis of Inheritance Exam Paper in 2 Minutes
Select subtopic & difficulty — Sets A, B, C, D auto-generated with No Repeat logic.
First 3 chapters of every subject are free — no payment required.