
अ Hindi
Genetic code Questions in Hindi
Class 12 Biology · Molecular Basis of Inheritance · Genetic code
256+
Questions
Hindi
Language
100%
With Solutions
Showing 50 of 256 questions in Hindi
201
MediumMCQ
आर्जिनिन (Arginine) के लिए आनुवंशिक कोड (genetic codes) हैं:
A
$CGU, CGC, CGA$
B
$CAU, CAC, CAA$
C
$AGU, AGC, AAC$
D
$GAU, GAC, GAA$
Solution
(A) आनुवंशिक कोड अपह्रासित (degenerate) होते हैं,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं।
आर्जिनिन छह कोडोन द्वारा कोडित होता है: $CGU, CGC, CGA, CGG, AGA,$ और $AGG$।
दिए गए विकल्पों में से,$CGU, CGC, CGA$ का समूह आर्जिनिन के लिए कोडोन का सही प्रतिनिधित्व करता है।
आर्जिनिन छह कोडोन द्वारा कोडित होता है: $CGU, CGC, CGA, CGG, AGA,$ और $AGG$।
दिए गए विकल्पों में से,$CGU, CGC, CGA$ का समूह आर्जिनिन के लिए कोडोन का सही प्रतिनिधित्व करता है।
0 likes
View Solution202
MediumMCQ
आनुवंशिक कोड के वाहक को क्या कहा जाता है?
A
मैसेंजर $RNA$ $(mRNA)$
B
ट्रांसफर $RNA$ $(tRNA)$
C
राइबोसोमल $RNA$ $(rRNA)$
D
वायरल $DNA$
Solution
(A) आनुवंशिक कोड उन नियमों का समूह है जिसके द्वारा आनुवंशिक सामग्री ($DNA$ या $RNA$ अनुक्रमों) में एन्कोड की गई जानकारी को जीवित कोशिकाओं द्वारा प्रोटीन में अनुवादित किया जाता है।
मैसेंजर $RNA$ $(mRNA)$ केंद्रक में स्थित $DNA$ से इस आनुवंशिक जानकारी को कोशिका द्रव्य में स्थित राइबोसोम तक ले जाने के लिए एक वाहक के रूप में कार्य करता है,जहाँ प्रोटीन संश्लेषण होता है।
यह कोडोन के उस अनुक्रम को वहन करता है जो परिणामी पॉलीपेप्टाइड श्रृंखला के अमीनो एसिड अनुक्रम को निर्धारित करता है।
इसलिए,$mRNA$ सही उत्तर है।
मैसेंजर $RNA$ $(mRNA)$ केंद्रक में स्थित $DNA$ से इस आनुवंशिक जानकारी को कोशिका द्रव्य में स्थित राइबोसोम तक ले जाने के लिए एक वाहक के रूप में कार्य करता है,जहाँ प्रोटीन संश्लेषण होता है।
यह कोडोन के उस अनुक्रम को वहन करता है जो परिणामी पॉलीपेप्टाइड श्रृंखला के अमीनो एसिड अनुक्रम को निर्धारित करता है।
इसलिए,$mRNA$ सही उत्तर है।
0 likes
View Solution203
MediumMCQ
आनुवंशिक कूट (Genetic code) क्या निर्धारित करता है?
A
प्रोटीन श्रृंखला में परिवर्तनशील अमीनो एसिड का क्रम
B
पेप्टाइड श्रृंखला में अमीनो एसिड का क्रम
C
मानव कोशिकाओं की संरचना
D
लक्षणों की आकारिकी
Solution
(B) आनुवंशिक कूट नियमों का एक समूह है जिसके द्वारा आनुवंशिक पदार्थ ($DNA$ या $mRNA$ अनुक्रमों) में एन्कोडेड जानकारी को जीवित कोशिकाओं द्वारा प्रोटीन में अनुवादित किया जाता है।
विशेष रूप से,$mRNA$ में न्यूक्लियोटाइड का अनुक्रम (कोडोन) अमीनो एसिड के उस विशिष्ट क्रम को निर्धारित करता है जो एक पेप्टाइड श्रृंखला बनाने के लिए आपस में जुड़ेंगे।
इसलिए,आनुवंशिक कूट प्रोटीन की प्राथमिक संरचना को निर्धारित करता है,जो अमीनो एसिड का अनुक्रम है।
विशेष रूप से,$mRNA$ में न्यूक्लियोटाइड का अनुक्रम (कोडोन) अमीनो एसिड के उस विशिष्ट क्रम को निर्धारित करता है जो एक पेप्टाइड श्रृंखला बनाने के लिए आपस में जुड़ेंगे।
इसलिए,आनुवंशिक कूट प्रोटीन की प्राथमिक संरचना को निर्धारित करता है,जो अमीनो एसिड का अनुक्रम है।
0 likes
View Solution204
MediumMCQ
आनुवंशिक कूट (Genetic code) है
A
ट्रिपलेट,सार्वत्रिक,अस्पष्ट और डिजनरेट।
B
ट्रिपलेट,सार्वत्रिक,स्पष्ट और नॉन-डिजनरेट।
C
ट्रिपलेट,सार्वत्रिक,स्पष्ट और डिजनरेट।
D
ट्रिपलेट,सार्वत्रिक,अस्पष्ट और नॉन-डिजनरेट।
Solution
(C) आनुवंशिक कूट नियमों का वह समूह है जिसके द्वारा $mRNA$ अनुक्रमों में निहित जानकारी को प्रोटीन (अमीनो एसिड अनुक्रम) में अनुवादित किया जाता है।
$1$. यह ट्रिपलेट (त्रिक) है,जिसका अर्थ है कि तीन नाइट्रोजनस क्षार मिलकर एक कोडोन बनाते हैं।
$2$. यह सार्वत्रिक (universal) है,जिसका अर्थ है कि लगभग सभी जीवों में एक ही कोडोन एक ही अमीनो एसिड के लिए कूटलेखन करता है।
$3$. यह स्पष्ट (non-ambiguous) है,जिसका अर्थ है कि एक कोडोन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
$4$. यह डिजनरेट है,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कूटबद्ध होते हैं।
$1$. यह ट्रिपलेट (त्रिक) है,जिसका अर्थ है कि तीन नाइट्रोजनस क्षार मिलकर एक कोडोन बनाते हैं।
$2$. यह सार्वत्रिक (universal) है,जिसका अर्थ है कि लगभग सभी जीवों में एक ही कोडोन एक ही अमीनो एसिड के लिए कूटलेखन करता है।
$3$. यह स्पष्ट (non-ambiguous) है,जिसका अर्थ है कि एक कोडोन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
$4$. यह डिजनरेट है,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कूटबद्ध होते हैं।
0 likes
View Solution205
EasyMCQ
प्रोटीन संश्लेषण (सुकेन्द्रकी में) के लिए प्रारंभिक कोडोन है
A
$GUA$
B
$GCA$
C
$CCA$
D
$AUG$
Solution
(D) $AUG$ सुकेन्द्रकी (eukaryotes) में प्रोटीन संश्लेषण का प्रारंभिक कोडोन है।
सुकेन्द्रकी में $AUG$ हमेशा मेथियोनीन (methionine) के लिए कोड करता है।
सुकेन्द्रकी में $AUG$ हमेशा मेथियोनीन (methionine) के लिए कोड करता है।
0 likes
View Solution206
MediumMCQ
गलत कथन/कथनों का चयन करें।
$i.$ छह कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं।
$ii.$ $mRNA$ में कोडोन को निरंतर रूप से पढ़ा जाता है।
$iii.$ तीन कोडोन स्टॉप कोडोन के रूप में कार्य करते हैं।
$iv.$ दीक्षा कोडोन (initiation codon) $AUG$ मेथियोनीन के लिए कोड करता है।
$i.$ छह कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं।
$ii.$ $mRNA$ में कोडोन को निरंतर रूप से पढ़ा जाता है।
$iii.$ तीन कोडोन स्टॉप कोडोन के रूप में कार्य करते हैं।
$iv.$ दीक्षा कोडोन (initiation codon) $AUG$ मेथियोनीन के लिए कोड करता है।
A
$(i) \text{ केवल}$
B
$(ii) \text{ केवल}$
C
$(i), (ii) \text{ और } (iv)$
D
$(i), (ii) \text{ और } (iii)$
Solution
(A) $3$ कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं। इन्हें स्टॉप कोडोन या नॉन-सेंस कोडोन $(UAA, UAG, UGA)$ कहा जाता है।
कथन $(i)$ गलत है क्योंकि $6$ नहीं बल्कि केवल $3$ कोडोन स्टॉप कोडोन होते हैं।
कथन $(ii)$ सही है क्योंकि आनुवंशिक कोड को बिना किसी विराम के निरंतर पढ़ा जाता है।
कथन $(iii)$ सही है क्योंकि $UAA, UAG, \text{ और } UGA$ तीन स्टॉप कोडोन हैं।
कथन $(iv)$ सही है क्योंकि $AUG$ दीक्षा कोडोन के रूप में कार्य करता है और मेथियोनीन के लिए कोड करता है।
कथन $(i)$ गलत है क्योंकि $6$ नहीं बल्कि केवल $3$ कोडोन स्टॉप कोडोन होते हैं।
कथन $(ii)$ सही है क्योंकि आनुवंशिक कोड को बिना किसी विराम के निरंतर पढ़ा जाता है।
कथन $(iii)$ सही है क्योंकि $UAA, UAG, \text{ और } UGA$ तीन स्टॉप कोडोन हैं।
कथन $(iv)$ सही है क्योंकि $AUG$ दीक्षा कोडोन के रूप में कार्य करता है और मेथियोनीन के लिए कोड करता है।
0 likes
View Solution207
MediumMCQ
एक से अधिक कोडोन द्वारा एक अमीनो एसिड का निर्धारण किसके कारण होता है?
A
जेनेटिक कोड की अतिरेकता (Redundancy).
B
जेनेटिक कोड की निरंतर प्रकृति।
C
जेनेटिक कोड में विराम चिह्न।
D
जेनेटिक कोड की सार्वभौमिक प्रकृति।
Solution
(A) कोडोन की अपभ्रष्टता (Degeneracy) जेनेटिक कोड की अतिरेकता है।
एक एकल अमीनो एसिड कई कोडोन द्वारा निर्दिष्ट किया जा सकता है,जिसे अपभ्रष्टता कहा जाता है।
अपभ्रष्टता मुख्य रूप से कोडोन में अंतिम बेस के कारण होती है,जिसे 'वोबल बेस' (wobble base) के रूप में जाना जाता है।
इस प्रकार,अमीनो एसिड को निर्धारित करने के लिए कोडोन के पहले दो बेस अधिक महत्वपूर्ण होते हैं,जबकि तीसरा बेस कोडिंग को प्रभावित किए बिना भिन्न हो सकता है।
इसे 'वोबल परिकल्पना' (wobble hypothesis) के रूप में जाना जाता है,जिसे $Crick$ द्वारा प्रस्तावित किया गया था और यह $tRNA$ अणुओं की मितव्ययिता स्थापित करती है।
एक एकल अमीनो एसिड कई कोडोन द्वारा निर्दिष्ट किया जा सकता है,जिसे अपभ्रष्टता कहा जाता है।
अपभ्रष्टता मुख्य रूप से कोडोन में अंतिम बेस के कारण होती है,जिसे 'वोबल बेस' (wobble base) के रूप में जाना जाता है।
इस प्रकार,अमीनो एसिड को निर्धारित करने के लिए कोडोन के पहले दो बेस अधिक महत्वपूर्ण होते हैं,जबकि तीसरा बेस कोडिंग को प्रभावित किए बिना भिन्न हो सकता है।
इसे 'वोबल परिकल्पना' (wobble hypothesis) के रूप में जाना जाता है,जिसे $Crick$ द्वारा प्रस्तावित किया गया था और यह $tRNA$ अणुओं की मितव्ययिता स्थापित करती है।
0 likes
View Solution208
MediumMCQ
प्रोटीन के संश्लेषण में मैसेंजर $RNA$ $(mRNA)$ क्या भूमिका निभाता है?
A
यह प्रक्रिया को उत्प्रेरित करता है।
B
यह आनुवंशिक कोड को एक विशिष्ट अमीनो एसिड में अनुवादित करता है।
C
यह प्रोटीन के लिए आनुवंशिक ब्लूप्रिंट प्रदान करता है।
D
यह प्रोटीन संश्लेषण से पहले मैसेंजर $RNA$ अणुओं को संशोधित करता है।
Solution
(C) प्रोटीन संश्लेषण की प्रक्रिया राइबोसोमल $RNA$ $(rRNA)$ द्वारा उत्प्रेरित होती है।
मैसेंजर $RNA$ $(mRNA)$ प्रोटीन संश्लेषण के लिए आनुवंशिक ब्लूप्रिंट या टेम्पलेट प्रदान करता है।
ट्रांसफर $RNA$ $(tRNA)$ ट्रिपलेट कोड को एक विशिष्ट अमीनो एसिड में अनुवादित करने के लिए जिम्मेदार है।
प्रोटीन संश्लेषण से पहले मैसेंजर $RNA$ अणुओं को स्मॉल न्यूक्लियर $RNA$ $(snRNA)$ द्वारा संशोधित किया जाता है।
मैसेंजर $RNA$ $(mRNA)$ प्रोटीन संश्लेषण के लिए आनुवंशिक ब्लूप्रिंट या टेम्पलेट प्रदान करता है।
ट्रांसफर $RNA$ $(tRNA)$ ट्रिपलेट कोड को एक विशिष्ट अमीनो एसिड में अनुवादित करने के लिए जिम्मेदार है।
प्रोटीन संश्लेषण से पहले मैसेंजर $RNA$ अणुओं को स्मॉल न्यूक्लियर $RNA$ $(snRNA)$ द्वारा संशोधित किया जाता है।
0 likes
View Solution209
MediumMCQ
निम्नलिखित में से किस अणु में आनुवंशिक कूट (genetic code) होता है?
A
$DNA$
B
$mRNA$
C
$tRNA$
D
$rRNA$
Solution
(B) आनुवंशिक कूट को $mRNA$ में न्यूक्लियोटाइड्स के उस अनुक्रम के रूप में परिभाषित किया जाता है जो प्रोटीन में अमीनो एसिड के क्रम को निर्धारित करता है।
$mRNA$ (मेसेंजर $RNA$) एक टेम्पलेट के रूप में कार्य करता है और एक (मोनोसिस्ट्रोनिक) या अधिक (पॉलीसिस्ट्रोनिक) पॉलीपेप्टाइड्स के संश्लेषण के लिए $DNA$ से कोडित जानकारी को राइबोसोम तक ले जाता है।
अनुवाद (translation) की प्रक्रिया के दौरान इसके कोडोन को $tRNA$ अणुओं पर मौजूद एंटीकोडोन द्वारा पहचाना जाता है।
$mRNA$ (मेसेंजर $RNA$) एक टेम्पलेट के रूप में कार्य करता है और एक (मोनोसिस्ट्रोनिक) या अधिक (पॉलीसिस्ट्रोनिक) पॉलीपेप्टाइड्स के संश्लेषण के लिए $DNA$ से कोडित जानकारी को राइबोसोम तक ले जाता है।
अनुवाद (translation) की प्रक्रिया के दौरान इसके कोडोन को $tRNA$ अणुओं पर मौजूद एंटीकोडोन द्वारा पहचाना जाता है।
0 likes
View Solution210
EasyMCQ
गलत मिलान ज्ञात कीजिए।
A
$UUU$ - फेनिलएलनिन
B
$UAG$ - सेंस कोडोन
C
$GUG$ - वैलीन
D
$UGG$ - ट्रिप्टोफैन
Solution
(B) $UAG$ एक स्टॉप कोडोन (नॉनसेंस कोडोन) है,सेंस कोडोन नहीं।
$UUU$ फेनिलएलनिन के लिए कोड करता है।
$GUG$ वैलीन के लिए कोड करता है।
$UGG$ ट्रिप्टोफैन के लिए कोड करता है।
$UUU$ फेनिलएलनिन के लिए कोड करता है।
$GUG$ वैलीन के लिए कोड करता है।
$UGG$ ट्रिप्टोफैन के लिए कोड करता है।
0 likes
View Solution211
MediumMCQ
एक कोडोन केवल एक अमीनो एसिड के लिए कोड करता है,इसलिए कोड है
A
अस्पष्ट और गैर-विशिष्ट
B
स्पष्ट और विशिष्ट
C
अस्पष्ट और विशिष्ट
D
स्पष्ट और गैर-विशिष्ट
Solution
(B) जेनेटिक कोड को स्पष्ट (Unambiguous) और विशिष्ट (Specific) कहा जाता है क्योंकि एक कोडोन केवल एक ही अमीनो एसिड के लिए कोड करता है।
उदाहरण के लिए,कोडोन $AUG$ केवल मेथियोनीन के लिए कोड करता है,किसी अन्य अमीनो एसिड के लिए नहीं।
यह गुण सुनिश्चित करता है कि अनुवाद (Translation) प्रक्रिया सटीक और विश्वसनीय है।
उदाहरण के लिए,कोडोन $AUG$ केवल मेथियोनीन के लिए कोड करता है,किसी अन्य अमीनो एसिड के लिए नहीं।
यह गुण सुनिश्चित करता है कि अनुवाद (Translation) प्रक्रिया सटीक और विश्वसनीय है।
0 likes
View Solution212
MediumMCQ
वोबल (Wobble) परिकल्पना के संदर्भ में सही कथन का चयन करें।
A
कोडोन का तीसरा क्षार कंपन क्षमता का अभाव रखता है।
B
तीसरा क्षार गैर-पूरक एंटीकोडोन के साथ भी $H$-बंध स्थापित कर सकता है।
C
एंटीकोडोन की विशिष्टता विशेष रूप से पहले दो कोडोन द्वारा निर्धारित होती है।
D
जेनेटिक कोड की अपह्रासता (degeneracy) का मुख्य कारण कोडोन के पहले दो $N$-क्षार हैं।
Solution
(B) फ्रांसिस क्रिक द्वारा प्रस्तावित वोबल परिकल्पना के अनुसार,कोडोन के तीसरे क्षार और एंटीकोडोन के पहले क्षार के बीच की पेयरिंग पहले दो स्थानों की तुलना में कम सख्त होती है।
यह कोडोन के तीसरे क्षार को गैर-पूरक एंटीकोडोन के साथ भी $H$-बंध स्थापित करने की अनुमति देता है,जो जेनेटिक कोड में अपह्रासता (degeneracy) की घटना को स्पष्ट करता है।
यह कोडोन के तीसरे क्षार को गैर-पूरक एंटीकोडोन के साथ भी $H$-बंध स्थापित करने की अनुमति देता है,जो जेनेटिक कोड में अपह्रासता (degeneracy) की घटना को स्पष्ट करता है।
0 likes
View Solution213
MediumMCQ
यदि $12^{th}$ न्यूक्लियोटाइड के बाद एक एडेनोसिन अवशेष डाला जाता है,तो $mRNA$ अनुक्रम $5'-CCCUCAUAGUCAUAC-3'$ द्वारा कितने अमीनो एसिड कोडित होंगे?
A
पाँच अमीनो एसिड
B
छह अमीनो एसिड
C
दो अमीनो एसिड
D
तीन अमीनो एसिड
Solution
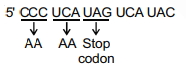
(C) मूल अनुक्रम $5'-CCC-UCA-UAG-UCA-UAC-3'$ है।
$12^{th}$ न्यूक्लियोटाइड दूसरे '$UCA$' कोडोन का '$A$' है (अनुक्रम: $C_1 C_2 C_3 U_4 C_5 A_6 U_7 A_8 G_9 U_{10} C_{11} A_{12} U_{13} A_{14} C_{15}$)।
$12^{th}$ न्यूक्लियोटाइड के बाद एक एडेनोसिन $(A)$ डालने पर नया अनुक्रम $5'-CCC-UCA-UAG-UCA-AUAC-3'$ प्राप्त होता है।
अब,कोडोन को पढ़ें:
$1$. $CCC$ (प्रोलाइन)
$2$. $UCA$ (सेरीन)
$3$. $UAG$ (स्टॉप कोडोन)
अनुवाद $UAG$ स्टॉप कोडोन पर रुक जाता है।
इसलिए,अनुवाद समाप्त होने से पहले केवल दो अमीनो एसिड ही कोडित होते हैं।
$12^{th}$ न्यूक्लियोटाइड दूसरे '$UCA$' कोडोन का '$A$' है (अनुक्रम: $C_1 C_2 C_3 U_4 C_5 A_6 U_7 A_8 G_9 U_{10} C_{11} A_{12} U_{13} A_{14} C_{15}$)।
$12^{th}$ न्यूक्लियोटाइड के बाद एक एडेनोसिन $(A)$ डालने पर नया अनुक्रम $5'-CCC-UCA-UAG-UCA-AUAC-3'$ प्राप्त होता है।
अब,कोडोन को पढ़ें:
$1$. $CCC$ (प्रोलाइन)
$2$. $UCA$ (सेरीन)
$3$. $UAG$ (स्टॉप कोडोन)
अनुवाद $UAG$ स्टॉप कोडोन पर रुक जाता है।
इसलिए,अनुवाद समाप्त होने से पहले केवल दो अमीनो एसिड ही कोडित होते हैं।
0 likes
View Solution214
MediumMCQ
$A$: वोबलिंग (Wobbling) पॉलीपेप्टाइड संश्लेषण के लिए आवश्यक $tRNA$ की संख्या को कम करती है।
$R$: यह कोड डिजनरेसी (code degeneracy) के प्रभाव को बढ़ाती है।
$R$: यह कोड डिजनरेसी (code degeneracy) के प्रभाव को बढ़ाती है।
A
अभिकथन और कारण दोनों सही हैं और कारण,अभिकथन की सही व्याख्या है।
B
अभिकथन और कारण दोनों सही हैं लेकिन कारण,अभिकथन की सही व्याख्या नहीं है।
C
अभिकथन सही है,लेकिन कारण गलत है।
D
अभिकथन और कारण दोनों गलत हैं।
Solution
(C) फ्रांसिस क्रिक द्वारा प्रस्तावित वोबल परिकल्पना (Wobble hypothesis) के अनुसार,कोडोन का तीसरा क्षार ($3'$ सिरा) $tRNA$ अणु के एंटीकोडोन में एक से अधिक क्षार के साथ युग्मित हो सकता है।
यह लचीलापन एक ही $tRNA$ को उन कई कोडोन को पहचानने की अनुमति देता है जो एक ही अमीनो एसिड के लिए कोड करते हैं,जिससे प्रोटीन संश्लेषण के लिए आवश्यक $tRNA$ की कुल संख्या कम हो जाती है।
कोड डिजनरेसी का अर्थ है कि एक ही अमीनो एसिड के लिए कई कोडोन हो सकते हैं।
वोबलिंग एक ऐसी क्रियाविधि है जो कम $tRNA$ द्वारा इन डिजनरेट कोडोन को पढ़ने की सुविधा प्रदान करती है,लेकिन यह डिजनरेसी का कारण नहीं है; बल्कि यह आनुवंशिक कोड की संरचना का परिणाम है।
इसलिए,अभिकथन सही है,लेकिन कारण गलत है क्योंकि वोबलिंग डिजनरेसी के प्रभाव को बढ़ाती नहीं है; यह केवल उसे समायोजित करती है।
यह लचीलापन एक ही $tRNA$ को उन कई कोडोन को पहचानने की अनुमति देता है जो एक ही अमीनो एसिड के लिए कोड करते हैं,जिससे प्रोटीन संश्लेषण के लिए आवश्यक $tRNA$ की कुल संख्या कम हो जाती है।
कोड डिजनरेसी का अर्थ है कि एक ही अमीनो एसिड के लिए कई कोडोन हो सकते हैं।
वोबलिंग एक ऐसी क्रियाविधि है जो कम $tRNA$ द्वारा इन डिजनरेट कोडोन को पढ़ने की सुविधा प्रदान करती है,लेकिन यह डिजनरेसी का कारण नहीं है; बल्कि यह आनुवंशिक कोड की संरचना का परिणाम है।
इसलिए,अभिकथन सही है,लेकिन कारण गलत है क्योंकि वोबलिंग डिजनरेसी के प्रभाव को बढ़ाती नहीं है; यह केवल उसे समायोजित करती है।
0 likes
View Solution215
MediumMCQ
$A$: पॉलीपेप्टाइड अनुक्रम $DNA$ द्वारा निर्धारित होते हैं और $mRNA$ द्वारा दर्शाए जाते हैं।
$R$: पॉलीपेप्टाइड में अमीनो एसिड के अनुक्रम का अनुमान $mRNA$ और टेम्पलेट $DNA$ पर न्यूक्लियोटाइड के सटीक अनुक्रम द्वारा लगाया जा सकता है।
$R$: पॉलीपेप्टाइड में अमीनो एसिड के अनुक्रम का अनुमान $mRNA$ और टेम्पलेट $DNA$ पर न्यूक्लियोटाइड के सटीक अनुक्रम द्वारा लगाया जा सकता है।
A
अभिकथन और कारण दोनों सही हैं और कारण अभिकथन की सही व्याख्या है।
B
अभिकथन और कारण दोनों सही हैं लेकिन कारण अभिकथन की सही व्याख्या नहीं है।
C
अभिकथन सही है,लेकिन कारण गलत है।
D
अभिकथन और कारण दोनों गलत हैं।
Solution
(A) अभिकथन सही है क्योंकि $DNA$ में संग्रहीत आनुवंशिक जानकारी पॉलीपेप्टाइड श्रृंखला में अमीनो एसिड के अनुक्रम को निर्धारित करती है,और यह जानकारी $mRNA$ में कोडोन के रूप में स्थानांतरित होती है।
कारण भी सही है क्योंकि आनुवंशिक कोड विशिष्ट होता है; इसलिए,$mRNA$ में न्यूक्लियोटाइड का अनुक्रम (जो टेम्पलेट $DNA$ श्रृंखला के पूरक होता है) अनुवाद के दौरान अमीनो एसिड के अनुक्रम को सीधे निर्धारित करता है।
चूंकि $mRNA$ अनुक्रम $DNA$ टेम्पलेट का सीधा प्रतिनिधित्व है और यह अमीनो एसिड अनुक्रम को निर्धारित करता है,इसलिए कारण अभिकथन की सही व्याख्या करता है।
कारण भी सही है क्योंकि आनुवंशिक कोड विशिष्ट होता है; इसलिए,$mRNA$ में न्यूक्लियोटाइड का अनुक्रम (जो टेम्पलेट $DNA$ श्रृंखला के पूरक होता है) अनुवाद के दौरान अमीनो एसिड के अनुक्रम को सीधे निर्धारित करता है।
चूंकि $mRNA$ अनुक्रम $DNA$ टेम्पलेट का सीधा प्रतिनिधित्व है और यह अमीनो एसिड अनुक्रम को निर्धारित करता है,इसलिए कारण अभिकथन की सही व्याख्या करता है।
0 likes
View Solution216
MediumMCQ
$A$: ट्रिप्लेट (त्रिक) आनुवंशिक कूट की पुष्टि फ्रेम-शिफ्ट उत्परिवर्तन द्वारा की जा सकती है।
$R$: फ्रेम-शिफ्टिंग में ट्रिप्लेट कोडोन द्वारा कूटबद्ध प्रोटीन उत्पाद में परिवर्तन शामिल है।
$R$: फ्रेम-शिफ्टिंग में ट्रिप्लेट कोडोन द्वारा कूटबद्ध प्रोटीन उत्पाद में परिवर्तन शामिल है।
A
अभिकथन और कारण दोनों सही हैं और कारण अभिकथन की सही व्याख्या है।
B
अभिकथन और कारण दोनों सही हैं लेकिन कारण अभिकथन की सही व्याख्या नहीं है।
C
अभिकथन सही है,लेकिन कारण गलत है।
D
अभिकथन और कारण दोनों गलत हैं।
Solution
(A) आनुवंशिक कूट ट्रिप्लेट (त्रिक) होता है,जिसका अर्थ है कि तीन न्यूक्लियोटाइड एक अमीनो एसिड के लिए कूटबद्ध होते हैं। फ्रेम-शिफ्ट उत्परिवर्तन $DNA$ अनुक्रम में एक या दो न्यूक्लियोटाइड के जुड़ने या हटने के कारण होते हैं। यह mRNA के पूरे रीडिंग फ्रेम को स्थानांतरित कर देता है,जिसके परिणामस्वरूप उत्परिवर्तन के बिंदु से आगे पूरी तरह से अलग अमीनो एसिड का अनुवाद होता है। यह पुष्टि करता है कि आनुवंशिक कूट को नॉन-ओवरलैपिंग ट्रिप्लेट में पढ़ा जाता है। इसलिए,अभिकथन और कारण दोनों सही हैं,और कारण यह बताता है कि फ्रेम-शिफ्ट उत्परिवर्तन आनुवंशिक कूट की ट्रिप्लेट प्रकृति की पुष्टि क्यों करते हैं।
0 likes
View Solution217
DifficultMCQ
कथन $I :$ कोडॉन $'AUG'$ मेथियोनीन और फेनिलएलनिन के लिए कूटलेखन करता है।
कथन $II :$ $'AAA'$ और $'AAG'$ दोनों कोडॉन अमीनो एसिड लाइसिन के लिए कूटलेखन करते हैं।
उपरोक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनें।
कथन $II :$ $'AAA'$ और $'AAG'$ दोनों कोडॉन अमीनो एसिड लाइसिन के लिए कूटलेखन करते हैं।
उपरोक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनें।
A
कथन $I$ और कथन $II$ दोनों सत्य हैं
B
कथन $I$ और कथन $II$ दोनों असत्य हैं
C
कथन $I$ सही है लेकिन कथन $II$ असत्य है
D
कथन $I$ गलत है लेकिन कथन $II$ सत्य है
Solution
(D) कथन $I$ गलत है क्योंकि कोडॉन $'AUG'$ केवल मेथियोनीन के लिए कूटलेखन करता है। यह एक प्रारंभिक कोडॉन (initiation codon) के रूप में भी कार्य करता है। फेनिलएलनिन के लिए $'UUU'$ और $'UUC'$ कूटलेखन करते हैं।
कथन $II$ सही है क्योंकि $'AAA'$ और $'AAG'$ दोनों अपह्रसित (degenerate) कोडॉन हैं जो अमीनो एसिड लाइसिन के लिए कूटलेखन करते हैं।
अतः,कथन $I$ गलत है और कथन $II$ सत्य है।
कथन $II$ सही है क्योंकि $'AAA'$ और $'AAG'$ दोनों अपह्रसित (degenerate) कोडॉन हैं जो अमीनो एसिड लाइसिन के लिए कूटलेखन करते हैं।
अतः,कथन $I$ गलत है और कथन $II$ सत्य है।
0 likes
View Solution218
EasyMCQ
आनुवंशिक कूट (genetic code) ........ पर उपस्थित होता है।
A
$DNA$
B
$rRNA$
C
$tRNA$
D
$mRNA$
Solution
(D) आनुवंशिक कूट नियमों का एक समूह है जिसके द्वारा आनुवंशिक सामग्री ($mRNA$ अनुक्रमों) में एन्कोड की गई जानकारी को जीवित कोशिकाओं द्वारा प्रोटीन में अनुवादित किया जाता है।
अनुलेखन (Transcription) की प्रक्रिया के दौरान,$DNA$ से आनुवंशिक जानकारी $mRNA$ में कॉपी की जाती है।
$mRNA$ अणु में कोडोन का अनुक्रम होता है,जो न्यूक्लियोटाइड की त्रिक (triplets) होती हैं और विशिष्ट अमीनो एसिड को निर्धारित करती हैं।
इसलिए,आनुवंशिक कूट $mRNA$ पर उपस्थित होता है।
अनुलेखन (Transcription) की प्रक्रिया के दौरान,$DNA$ से आनुवंशिक जानकारी $mRNA$ में कॉपी की जाती है।
$mRNA$ अणु में कोडोन का अनुक्रम होता है,जो न्यूक्लियोटाइड की त्रिक (triplets) होती हैं और विशिष्ट अमीनो एसिड को निर्धारित करती हैं।
इसलिए,आनुवंशिक कूट $mRNA$ पर उपस्थित होता है।
0 likes
View Solution219
MediumMCQ
कितने अमीनो एसिड केवल एक ही कोडोन द्वारा कूटबद्ध (encode) होते हैं?
A
$1$
B
$2$
C
$3$
D
$4$
Solution
(B) आनुवंशिक कूट (Genetic code) में,अधिकांश अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं (अपह्रास/Degeneracy)।
हालाँकि,दो विशिष्ट अमीनो एसिड ऐसे हैं जो केवल एक ही कोडोन द्वारा कूटबद्ध होते हैं:
$1$. मेथियोनीन $(AUG)$
$2$. ट्रिप्टोफैन $(UGG)$
अतः,केवल एक ही कोडोन द्वारा कूटबद्ध अमीनो एसिड की कुल संख्या $2$ है।
हालाँकि,दो विशिष्ट अमीनो एसिड ऐसे हैं जो केवल एक ही कोडोन द्वारा कूटबद्ध होते हैं:
$1$. मेथियोनीन $(AUG)$
$2$. ट्रिप्टोफैन $(UGG)$
अतः,केवल एक ही कोडोन द्वारा कूटबद्ध अमीनो एसिड की कुल संख्या $2$ है।
0 likes
View Solution220
EasyMCQ
$tRNA$ के कितने प्रकार होते हैं?
A
$1$
B
$61$
C
$64$
D
$3$
Solution
(B) $tRNA$ अणुओं के $61$ प्रकार होते हैं जो अमीनो एसिड के लिए कोड करने वाले $61$ कोडोन के अनुरूप होते हैं। हालांकि आनुवंशिक कोड में कुल $64$ कोडोन होते हैं,जिनमें से $3$ स्टॉप कोडोन $(UAA, UAG, UGA)$ होते हैं,जिनके लिए कोई संबंधित $tRNA$ अणु नहीं होते हैं। इसलिए,$tRNA$ के प्रकारों की कुल संख्या $61$ है।
0 likes
View Solution221
MediumMCQ
निम्नलिखित में से कौन सा प्रतिसंकेत (anticodon) नहीं है?
A
$ACU$
B
$AAU$
C
$CUA$
D
$UAA$
Solution
(D) प्रतिसंकेत (anticodon) ट्रांसफर $RNA$ $(tRNA)$ अणु में तीन न्यूक्लियोटाइड का एक क्रम होता है,जो मैसेंजर $RNA$ $(mRNA)$ पर एक पूरक कोडोन के अनुरूप होता है।
स्टॉप कोडोन (जिन्हें समाप्ति कोडोन भी कहा जाता है) $UAA$,$UAG$ और $UGA$ हैं।
ये कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं और सामान्य शारीरिक स्थितियों में कोशिका में इनके लिए कोई संबंधित $tRNA$ अणु नहीं होते हैं।
इसलिए,$UAA$ एक स्टॉप कोडोन है और यह प्रतिसंकेत के रूप में कार्य नहीं करता है।
स्टॉप कोडोन (जिन्हें समाप्ति कोडोन भी कहा जाता है) $UAA$,$UAG$ और $UGA$ हैं।
ये कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं और सामान्य शारीरिक स्थितियों में कोशिका में इनके लिए कोई संबंधित $tRNA$ अणु नहीं होते हैं।
इसलिए,$UAA$ एक स्टॉप कोडोन है और यह प्रतिसंकेत के रूप में कार्य नहीं करता है।
0 likes
View Solution222
MediumMCQ
निम्नलिखित कॉलम का मिलान करें :
| कॉलम-$I$ (आनुवंशिक कूट) | कॉलम-$II$ (अमीनो अम्ल) |
| $P$. $UAA$ | $I$. प्रोलीन |
| $Q$. $CCA$ | $II$. ग्लाइसिन |
| $R$. $GGC$ | $III$. समापन |
| $S$. $AGU$ | $IV$. सेरीन |
A
$(P-I), (Q-III), (R-IV), (S-II)$
B
$(P-III), (Q-I), (R-II), (S-IV)$
C
$(P-I), (Q-IV), (R-III), (S-II)$
D
$(P-III), (Q-I), (R-IV), (S-II)$
Solution
(B) आनुवंशिक कूट $UAA$ एक समापन कोडोन (stop codon) है, जो प्रोटीन संश्लेषण की समाप्ति का संकेत देता है $(P-III)$।
$CCA$ प्रोलीन अमीनो अम्ल के लिए कोड करता है $(Q-I)$।
$GGC$ ग्लाइसिन अमीनो अम्ल के लिए कोड करता है $(R-II)$।
$AGU$ सेरीन अमीनो अम्ल के लिए कोड करता है $(S-IV)$।
अतः, सही मिलान $(P-III), (Q-I), (R-II), (S-IV)$ है।
$CCA$ प्रोलीन अमीनो अम्ल के लिए कोड करता है $(Q-I)$।
$GGC$ ग्लाइसिन अमीनो अम्ल के लिए कोड करता है $(R-II)$।
$AGU$ सेरीन अमीनो अम्ल के लिए कोड करता है $(S-IV)$।
अतः, सही मिलान $(P-III), (Q-I), (R-II), (S-IV)$ है।
0 likes
View Solution223
EasyMCQ
एक ही अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट किया जा सकता है। ऐसे कोडोन को ......... कोडोन कहा जाता है।
A
अपहसित (Degenerate)
B
प्रारंभिक (Initiation)
C
सार्वभौमिक (Universal)
D
समाप्ति (Termination)
Solution
(A) आनुवंशिक कोड अपहसित (Degenerate) होता है,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कूटबद्ध (encode) होते हैं। उदाहरण के लिए,ल्यूसीन,सेरीन और आर्जिनिन में से प्रत्येक को छह अलग-अलग कोडोन द्वारा निर्दिष्ट किया जाता है। यह गुण उत्परिवर्तन के हानिकारक प्रभावों को कम करने में मदद करता है।
0 likes
View Solution224
MediumMCQ
अनुक्रम $AGC \, ACA \, UUU \, AUG \, CCG \, AGC$ है। निम्नलिखित में से किस विकल्प के अनुसार रीडिंग फ्रेम नहीं बदलेगा?
A
$9$ वें और $10$ वें स्थान पर न्यूक्लियोटाइड का योग होने पर
B
तीसरे स्थान पर एक न्यूक्लियोटाइड का योग होने पर
C
$6$ वें और $7$ वें न्यूक्लियोटाइड के विलोपन (deletion) से
D
$10, 11$ और $12$ वें न्यूक्लियोटाइड के विलोपन (deletion) से
Solution
(D) रीडिंग फ्रेम आनुवंशिक कोड की ट्रिपलेट (त्रिक) प्रकृति द्वारा निर्धारित होता है।
यदि जोड़े गए या हटाए गए न्यूक्लियोटाइड की संख्या $3$ का गुणज है,तो रीडिंग फ्रेम अपरिवर्तित रहता है क्योंकि ट्रिपलेट समूह बना रहता है।
विकल्प $D$ में,$3$ न्यूक्लियोटाइड ($10, 11$ और $12$ वें) को हटाने का अर्थ है एक पूर्ण कोडोन का हट जाना।
चूंकि एक पूरा कोडोन हट गया है,इसलिए बाद के कोडोन उसी रीडिंग फ्रेम में रहते हैं,हालांकि प्रोटीन अनुक्रम से एक अमीनो एसिड कम हो जाता है।
यदि जोड़े गए या हटाए गए न्यूक्लियोटाइड की संख्या $3$ का गुणज है,तो रीडिंग फ्रेम अपरिवर्तित रहता है क्योंकि ट्रिपलेट समूह बना रहता है।
विकल्प $D$ में,$3$ न्यूक्लियोटाइड ($10, 11$ और $12$ वें) को हटाने का अर्थ है एक पूर्ण कोडोन का हट जाना।
चूंकि एक पूरा कोडोन हट गया है,इसलिए बाद के कोडोन उसी रीडिंग फ्रेम में रहते हैं,हालांकि प्रोटीन अनुक्रम से एक अमीनो एसिड कम हो जाता है।
0 likes
View Solution225
MediumMCQ
यदि $tRNA$ पर प्रतिसंकेत (anticodon) $CCG$ है,तो यह $tRNA$ किस अमीनो एसिड को वहन करेगा?
A
$Pro$
B
$Gly$
C
$Gln$
D
$Phe$
Solution
(B) $tRNA$ पर प्रतिसंकेत $CCG$ है।
क्षार-युग्मन (base-pairing) के नियमों के अनुसार,प्रतिसंकेत $CCG$,$mRNA$ रज्जुक पर स्थित कोडोन $GGC$ के साथ जुड़ता है।
मानक आनुवंशिक कोड तालिका का उपयोग करने पर,कोडोन $GGC$ ग्लाइसिन $(Gly)$ अमीनो एसिड के लिए कोड करता है।
अतः,$CCG$ प्रतिसंकेत वाला $tRNA$ अमीनो एसिड $Gly$ को वहन करता है।
क्षार-युग्मन (base-pairing) के नियमों के अनुसार,प्रतिसंकेत $CCG$,$mRNA$ रज्जुक पर स्थित कोडोन $GGC$ के साथ जुड़ता है।
मानक आनुवंशिक कोड तालिका का उपयोग करने पर,कोडोन $GGC$ ग्लाइसिन $(Gly)$ अमीनो एसिड के लिए कोड करता है।
अतः,$CCG$ प्रतिसंकेत वाला $tRNA$ अमीनो एसिड $Gly$ को वहन करता है।
0 likes
View Solution226
EasyMCQ
किसने प्रस्तावित किया था कि अमीनो एसिड के लिए आनुवंशिक कोड तीन न्यूक्लियोटाइड से बना होना चाहिए?
A
जॉर्ज गैमोव
B
फ्रांसिस क्रिक
C
जैक मोनोड
D
फ्रैंकलिन स्टाहल
Solution
(A) यह अवधारणा कि आनुवंशिक कोड एक ट्रिपलेट (त्रिक) है,भौतिक विज्ञानी $George \ Gamow$ द्वारा प्रस्तावित की गई थी।
उन्होंने तर्क दिया कि चूंकि केवल $4$ बेस और $20$ अमीनो एसिड होते हैं,इसलिए कोड को बेस का एक संयोजन होना चाहिए।
उन्होंने गणना की कि $4^3 = 64$ कोडोन बनते हैं,जो $20$ अमीनो एसिड को कोड करने के लिए पर्याप्त हैं।
उन्होंने तर्क दिया कि चूंकि केवल $4$ बेस और $20$ अमीनो एसिड होते हैं,इसलिए कोड को बेस का एक संयोजन होना चाहिए।
उन्होंने गणना की कि $4^3 = 64$ कोडोन बनते हैं,जो $20$ अमीनो एसिड को कोड करने के लिए पर्याप्त हैं।
0 likes
View Solution227
MediumMCQ
दी गई $mRNA$ अनुक्रम द्वारा कोडित अमीनो एसिड अनुक्रम की पहचान करें: $5'-AUG-UUU-UUC-GUG-AUA-UGG-3'$
A
$Met-Phe-Leu-Ser-Ile$
B
$Met-Phe-Phe-Val-Ile-Trp$
C
$Met-Leu-Leu-Ser-Ile-Tyr$
D
$Met-Leu-Leu-Val-Cys-Trp$
Solution
(B) अमीनो एसिड अनुक्रम निर्धारित करने के लिए,हम $mRNA$ अनुक्रम को कोडोन (न्यूक्लियोटाइड की त्रिक) में विभाजित करते हैं:
$1$. $AUG$: मेथियोनीन $(Met)$ के लिए कोड करता है।
$2$. $UUU$: फेनिलएलनिन $(Phe)$ के लिए कोड करता है।
$3$. $UUC$: फेनिलएलनिन $(Phe)$ के लिए कोड करता है।
$4$. $GUG$: वैलीन $(Val)$ के लिए कोड करता है।
$5$. $AUA$: आइसोल्यूसीन $(Ile)$ के लिए कोड करता है।
$6$. $UGG$: ट्रिप्टोफैन $(Trp)$ के लिए कोड करता है।
अतः,अनुक्रम $Met-Phe-Phe-Val-Ile-Trp$ है।
$1$. $AUG$: मेथियोनीन $(Met)$ के लिए कोड करता है।
$2$. $UUU$: फेनिलएलनिन $(Phe)$ के लिए कोड करता है।
$3$. $UUC$: फेनिलएलनिन $(Phe)$ के लिए कोड करता है।
$4$. $GUG$: वैलीन $(Val)$ के लिए कोड करता है।
$5$. $AUA$: आइसोल्यूसीन $(Ile)$ के लिए कोड करता है।
$6$. $UGG$: ट्रिप्टोफैन $(Trp)$ के लिए कोड करता है।
अतः,अनुक्रम $Met-Phe-Phe-Val-Ile-Trp$ है।
0 likes
View Solution228
MediumMCQ
कथन $I$: कोडॉन $\text{UAA}$ लाइसिन के लिए कूटलेखन (code) करता है।
कथन $II$: आनुवंशिक कोड आमतौर पर अस्पष्ट (ambiguous) होता है।
उपर्युक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनिए।
कथन $II$: आनुवंशिक कोड आमतौर पर अस्पष्ट (ambiguous) होता है।
उपर्युक्त कथनों के आलोक में,नीचे दिए गए विकल्पों में से सही उत्तर चुनिए।
A
कथन $I$ और कथन $II$ दोनों सत्य हैं
B
कथन $I$ और कथन $II$ दोनों असत्य हैं
C
कथन $I$ सही है लेकिन कथन $II$ गलत है
D
कथन $I$ गलत है लेकिन कथन $II$ सही है
Solution
(B) कथन $I$ गलत है क्योंकि $\text{UAA}$ एक स्टॉप कोडॉन (नॉनसेंस कोडॉन) है और यह लाइसिन सहित किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करता है। लाइसिन के लिए $\text{AAA}$ और $\text{AAG}$ कोडॉन होते हैं।
कथन $II$ गलत है क्योंकि आनुवंशिक कोड अस्पष्ट नहीं होता है,जिसका अर्थ है कि एक कोडॉन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
अतः,दोनों कथन असत्य हैं।
कथन $II$ गलत है क्योंकि आनुवंशिक कोड अस्पष्ट नहीं होता है,जिसका अर्थ है कि एक कोडॉन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
अतः,दोनों कथन असत्य हैं।
0 likes
View Solution229
MediumMCQ
निम्नलिखित में से किस वैज्ञानिक द्वारा विकसित रासायनिक विधि नाइट्रोजन क्षारों के परिभाषित संयोजनों वाले $\text{RNA}$ अणुओं के संश्लेषण में सहायक थी?
A
निरेनबर्ग
B
हर गोबिंद खुराना
C
गैमो
D
क्रिक
Solution
(B) हर गोबिंद खुराना ने एक रासायनिक विधि विकसित की जो नाइट्रोजन क्षारों के परिभाषित संयोजनों (होमोपॉलिमर और कोपॉलिमर) वाले $\text{RNA}$ अणुओं के संश्लेषण में सहायक थी। यह आनुवंशिक कोड (genetic code) को समझने की दिशा में एक महत्वपूर्ण कदम था। मार्शल निरेनबर्ग की प्रोटीन संश्लेषण के लिए सेल-फ्री सिस्टम ने भी कोड को समझने में मदद की,लेकिन परिभाषित $\text{RNA}$ अनुक्रमों के रासायनिक संश्लेषण का श्रेय विशेष रूप से खुराना को जाता है।
0 likes
View Solution230
MediumMCQ
आनुवंशिक कूट (Genetic code) की अपह्रासता (Degeneracy) का अर्थ है$-$
A
प्रत्येक कोडोन केवल एक विशिष्ट अमीनो एसिड के लिए कोड करता है
B
अमीनो एसिड हमेशा केवल एक विशिष्ट कोडोन द्वारा कोडित होते हैं
C
कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं
D
मेथियोनीन और ट्रिप्टोफैन का कोडोन
Solution
(C) आनुवंशिक कूट को अपह्रासित (degenerate) कहा जाता है क्योंकि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं।
कुल $64$ संभावित कोडोन होते हैं,लेकिन प्रोटीन संश्लेषण में सामान्यतः केवल $20$ अमीनो एसिड का उपयोग होता है।
चूंकि कोडोन की संख्या अमीनो एसिड की संख्या से अधिक होती है,इसलिए एक ही अमीनो एसिड के लिए कई कोडोन हो सकते हैं।
उदाहरण के लिए,ल्यूसीन और सेरीन प्रत्येक $6$ अलग-अलग कोडोन द्वारा कोडित होते हैं।
कुल $64$ संभावित कोडोन होते हैं,लेकिन प्रोटीन संश्लेषण में सामान्यतः केवल $20$ अमीनो एसिड का उपयोग होता है।
चूंकि कोडोन की संख्या अमीनो एसिड की संख्या से अधिक होती है,इसलिए एक ही अमीनो एसिड के लिए कई कोडोन हो सकते हैं।
उदाहरण के लिए,ल्यूसीन और सेरीन प्रत्येक $6$ अलग-अलग कोडोन द्वारा कोडित होते हैं।
0 likes
View Solution231
MediumMCQ
आनुवंशिक कूट (genetic code) के लिए निम्नलिखित में से कौन सा कथन गलत है?
$(i)$ कोडोन ट्रिपलेट (त्रिक) होता है।
$(ii)$ $64$ कोडोन अमीनो एसिड के लिए कूटलेखन (code) करते हैं।
$(iii)$ आनुवंशिक कूट असंदिग्ध (unambiguous) होता है।
$(iv)$ आनुवंशिक कूट लगभग सार्वत्रिक (universal) है।
$(v)$ $\text{AUG}$ के दोहरे कार्य होते हैं।
$(i)$ कोडोन ट्रिपलेट (त्रिक) होता है।
$(ii)$ $64$ कोडोन अमीनो एसिड के लिए कूटलेखन (code) करते हैं।
$(iii)$ आनुवंशिक कूट असंदिग्ध (unambiguous) होता है।
$(iv)$ आनुवंशिक कूट लगभग सार्वत्रिक (universal) है।
$(v)$ $\text{AUG}$ के दोहरे कार्य होते हैं।
A
केवल $(ii)$
B
$(ii)$ और $(iii)$
C
$(iii), (iv)$ और $(v)$
D
सभी सही हैं
Solution
(A) आनुवंशिक कूट में कुल $64$ कोडोन होते हैं।
इन $64$ कोडोन में से,$61$ कोडोन अमीनो एसिड के लिए कूटलेखन करते हैं,जबकि $3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (समापन कोडोन) के रूप में कार्य करते हैं और किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करते हैं।
इसलिए,कथन $(ii)$ गलत है क्योंकि $64$ कोडोन अमीनो एसिड के लिए कूटलेखन नहीं करते हैं; केवल $61$ ही करते हैं।
कथन $(i)$ सही है क्योंकि कोडोन न्यूक्लियोटाइड के त्रिक होते हैं।
कथन $(iii)$ सही है क्योंकि आनुवंशिक कूट असंदिग्ध होता है,जिसका अर्थ है कि एक कोडोन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
कथन $(iv)$ सही है क्योंकि आनुवंशिक कूट लगभग सार्वत्रिक है (बैक्टीरिया से लेकर मनुष्यों तक)।
कथन $(v)$ सही है क्योंकि $\text{AUG}$ एक प्रारंभिक कोडोन (मिथियोनाइन के लिए) के रूप में कार्य करता है और पॉलीपेप्टाइड श्रृंखला के बीच में भी मिथियोनाइन के लिए कूटलेखन करता है।
इन $64$ कोडोन में से,$61$ कोडोन अमीनो एसिड के लिए कूटलेखन करते हैं,जबकि $3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (समापन कोडोन) के रूप में कार्य करते हैं और किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करते हैं।
इसलिए,कथन $(ii)$ गलत है क्योंकि $64$ कोडोन अमीनो एसिड के लिए कूटलेखन नहीं करते हैं; केवल $61$ ही करते हैं।
कथन $(i)$ सही है क्योंकि कोडोन न्यूक्लियोटाइड के त्रिक होते हैं।
कथन $(iii)$ सही है क्योंकि आनुवंशिक कूट असंदिग्ध होता है,जिसका अर्थ है कि एक कोडोन केवल एक विशिष्ट अमीनो एसिड के लिए कूटलेखन करता है।
कथन $(iv)$ सही है क्योंकि आनुवंशिक कूट लगभग सार्वत्रिक है (बैक्टीरिया से लेकर मनुष्यों तक)।
कथन $(v)$ सही है क्योंकि $\text{AUG}$ एक प्रारंभिक कोडोन (मिथियोनाइन के लिए) के रूप में कार्य करता है और पॉलीपेप्टाइड श्रृंखला के बीच में भी मिथियोनाइन के लिए कूटलेखन करता है।
0 likes
View Solution232
EasyMCQ
निम्नलिखित में से कौन सा एक समापन कोडोन (termination codon) है?
A
$AUG$
B
$UAG$
C
$UGU$
D
$UUA$
Solution
(B) समापन कोडोन (जिन्हें स्टॉप कोडोन भी कहा जाता है) $UAA$,$UAG$ और $UGA$ हैं। ये कोडोन स्थानांतरण (translation) की प्रक्रिया के दौरान प्रोटीन संश्लेषण के अंत का संकेत देते हैं। दिए गए विकल्पों में से,$UAG$ एक समापन कोडोन है।
0 likes
View Solution233
EasyMCQ
$mRNA$ पर कोडोन और $tRNA$ पर एंटीकोडोन क्या हैं?
A
समान न्यूक्लियोटाइड्स की त्रिक (triplet)
B
पूरक न्यूक्लियोटाइड्स की त्रिक (triplet)
C
किन्हीं दो पूरक नाइट्रोजन क्षार का समूह
D
केवल दो समान न्यूक्लियोटाइड्स का समूह
Solution
(B) आनुवंशिक कोड को $mRNA$ पर न्यूक्लियोटाइड्स की त्रिक (triplet) के रूप में पढ़ा जाता है,जिसे कोडोन कहा जाता है।
अनुवाद (translation) की प्रक्रिया के दौरान,$tRNA$ अणु में एक एंटीकोडोन होता है,जो $mRNA$ पर कोडोन के पूरक तीन न्यूक्लियोटाइड्स का एक क्रम है।
कोडोन और एंटीकोडोन के बीच यह क्षार युग्मन (base pairing) यह सुनिश्चित करता है कि सही अमीनो एसिड बढ़ती हुई पॉलीपेप्टाइड श्रृंखला में शामिल हो।
इसलिए,कोडोन और एंटीकोडोन पूरक न्यूक्लियोटाइड्स की त्रिक हैं।
अनुवाद (translation) की प्रक्रिया के दौरान,$tRNA$ अणु में एक एंटीकोडोन होता है,जो $mRNA$ पर कोडोन के पूरक तीन न्यूक्लियोटाइड्स का एक क्रम है।
कोडोन और एंटीकोडोन के बीच यह क्षार युग्मन (base pairing) यह सुनिश्चित करता है कि सही अमीनो एसिड बढ़ती हुई पॉलीपेप्टाइड श्रृंखला में शामिल हो।
इसलिए,कोडोन और एंटीकोडोन पूरक न्यूक्लियोटाइड्स की त्रिक हैं।
0 likes
View Solution234
EasyMCQ
$CUA$ $CUA$ $CUA$ कोडोन निम्नलिखित में से किस अमीनो एसिड के लिए कोड करता है?
A
वेलिन
B
मिथियोनाइन
C
ल्यूसिन
D
ग्लूटामिक एसिड
Solution
(C) आनुवंशिक कोड त्रिक (triplet) और अपह्रासित (degenerate) प्रकृति का होता है।
होमोपॉलिमर और दोहराव वाली अनुक्रमों का उपयोग करने वाले प्रयोगों ने दिखाया है कि दोहराव वाले त्रिक के साथ एक पॉलिन्यूक्लियोटाइड श्रृंखला एक विशिष्ट पॉलीपेप्टाइड के लिए कोड करती है।
उदाहरण के लिए,$CUA$ $CUA$ $CUA$ $CUA$ के दोहराव वाले अनुक्रम वाली एक पॉलिन्यूक्लियोटाइड श्रृंखला केवल ल्यूसिन अमीनो एसिड से बनी पॉलीपेप्टाइड श्रृंखला के संश्लेषण का परिणाम देती है।
इसलिए,$CUA$ कोडोन ल्यूसिन के लिए कोड करता है।
होमोपॉलिमर और दोहराव वाली अनुक्रमों का उपयोग करने वाले प्रयोगों ने दिखाया है कि दोहराव वाले त्रिक के साथ एक पॉलिन्यूक्लियोटाइड श्रृंखला एक विशिष्ट पॉलीपेप्टाइड के लिए कोड करती है।
उदाहरण के लिए,$CUA$ $CUA$ $CUA$ $CUA$ के दोहराव वाले अनुक्रम वाली एक पॉलिन्यूक्लियोटाइड श्रृंखला केवल ल्यूसिन अमीनो एसिड से बनी पॉलीपेप्टाइड श्रृंखला के संश्लेषण का परिणाम देती है।
इसलिए,$CUA$ कोडोन ल्यूसिन के लिए कोड करता है।
0 likes
View Solution235
EasyMCQ
डॉ. खुराना ने $CUCUCUCUCU$ न्यूक्लियोटाइड्स युक्त एक कृत्रिम $mRNA$ तैयार किया; इसके अनुवाद (translation) के परिणामस्वरूप क्रमशः . . . . . . और . . . . . . अमीनो एसिड की वैकल्पिक व्यवस्था वाली पॉलीपेप्टाइड श्रृंखला का निर्माण हुआ।
A
ल्यूसीन,सेरीन
B
सेरीन,ल्यूसीन
C
प्रोलिन,ग्लूटामाइन
D
ग्लूटामाइन और प्रोलिन
Solution
(A) कृत्रिम $mRNA$ अनुक्रम $CUCUCUCUCU...$ है।
इस अनुक्रम को तीन न्यूक्लियोटाइड्स के कोडोन के रूप में पढ़ा जाता है: $CUC$ और $UCU$।
जेनेटिक कोड तालिका के अनुसार:
$1$. $CUC$ कोडोन ल्यूसीन $(Leucine)$ अमीनो एसिड के लिए कोड करता है।
$2$. $UCU$ कोडोन सेरीन $(Serine)$ अमीनो एसिड के लिए कोड करता है।
अतः,इस $mRNA$ के अनुवाद से ल्यूसीन और सेरीन अमीनो एसिड की वैकल्पिक व्यवस्था वाली एक पॉलीपेप्टाइड श्रृंखला प्राप्त होती है।
इस अनुक्रम को तीन न्यूक्लियोटाइड्स के कोडोन के रूप में पढ़ा जाता है: $CUC$ और $UCU$।
जेनेटिक कोड तालिका के अनुसार:
$1$. $CUC$ कोडोन ल्यूसीन $(Leucine)$ अमीनो एसिड के लिए कोड करता है।
$2$. $UCU$ कोडोन सेरीन $(Serine)$ अमीनो एसिड के लिए कोड करता है।
अतः,इस $mRNA$ के अनुवाद से ल्यूसीन और सेरीन अमीनो एसिड की वैकल्पिक व्यवस्था वाली एक पॉलीपेप्टाइड श्रृंखला प्राप्त होती है।
0 likes
View Solution236
EasyMCQ
आनुवंशिक कोड के अनुसार,कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कूटबद्ध (encoded) होते हैं,आनुवंशिक कोड की इस विशेषता को . . . . . . कहा जाता है।
A
अस्पष्टता का अभाव (non-ambiguous)
B
अपभ्रंशता (degeneracy)
C
सार्वत्रिक (universal)
D
ओवरलैपिंग न होना (non-overlapping)
Solution
(B) आनुवंशिक कोड एक गुण प्रदर्शित करता है जिसे अपभ्रंशता (degeneracy) या अतिरेक (redundancy) कहा जाता है।
चूंकि कुल $64$ कोडोन होते हैं और केवल $20$ अमीनो एसिड,इसलिए कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं।
उदाहरण के लिए,ल्यूसीन (Leucine) अमीनो एसिड $6$ अलग-अलग कोडोन $(UUA, UUG, CUU, CUC, CUA, CUG)$ द्वारा कूटबद्ध होता है।
यह विशेषता जीव को उत्परिवर्तन (mutations) से बचाने में मदद करती है,क्योंकि कोडोन के तीसरे क्षार (base) में परिवर्तन होने पर अक्सर अमीनो एसिड में कोई बदलाव नहीं होता है।
चूंकि कुल $64$ कोडोन होते हैं और केवल $20$ अमीनो एसिड,इसलिए कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं।
उदाहरण के लिए,ल्यूसीन (Leucine) अमीनो एसिड $6$ अलग-अलग कोडोन $(UUA, UUG, CUU, CUC, CUA, CUG)$ द्वारा कूटबद्ध होता है।
यह विशेषता जीव को उत्परिवर्तन (mutations) से बचाने में मदद करती है,क्योंकि कोडोन के तीसरे क्षार (base) में परिवर्तन होने पर अक्सर अमीनो एसिड में कोई बदलाव नहीं होता है।
0 likes
View Solution237
EasyMCQ
ट्रिप्लेट जेनेटिक कोड के लिए पहला प्रमाण . . . . . . द्वारा दिया गया था।
A
सेवेरो ओचोआ
B
निरेनबर्ग और मैथाई
C
क्रिक
D
डॉ. एच. जी. खुराना
Solution
(C) ट्रिप्लेट जेनेटिक कोड के लिए पहला प्रमाण फ्रांसिस $Crick$ और उनके सहयोगियों द्वारा $T4$ बैक्टीरियोफेज के $rII$ क्षेत्र पर किए गए प्रयोगों के माध्यम से दिया गया था। उन्होंने प्रदर्शित किया कि एक या दो न्यूक्लियोटाइड के जुड़ने या हटने से फ्रेमशिफ्ट म्यूटेशन होता है,जबकि तीन न्यूक्लियोटाइड के जुड़ने या हटने से रीडिंग फ्रेम बहाल हो जाता है,जिससे यह सिद्ध होता है कि जेनेटिक कोड ट्रिप्लेट है।
0 likes
View Solution238
EasyMCQ
$20$ ज्ञात अमीनो एसिड के लिए कितने सेंस कोडोन कोडिंग करते हैं?
A
$61$
B
$62$
C
$63$
D
$64$
Solution
(A) जेनेटिक कोड में कुल $64$ कोडोन होते हैं।
इन $64$ कोडोन में से,$3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (जिन्हें टर्मिनेशन या नॉनसेंस कोडोन भी कहा जाता है) होते हैं क्योंकि वे किसी भी अमीनो एसिड के लिए कोडिंग नहीं करते हैं।
इसलिए,अमीनो एसिड के लिए कोडिंग करने वाले सेंस कोडोन की संख्या $64 - 3 = 61$ है।
ये $61$ कोडोन प्रोटीन संश्लेषण में उपयोग किए जाने वाले $20$ मानक अमीनो एसिड के लिए जिम्मेदार हैं।
इन $64$ कोडोन में से,$3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (जिन्हें टर्मिनेशन या नॉनसेंस कोडोन भी कहा जाता है) होते हैं क्योंकि वे किसी भी अमीनो एसिड के लिए कोडिंग नहीं करते हैं।
इसलिए,अमीनो एसिड के लिए कोडिंग करने वाले सेंस कोडोन की संख्या $64 - 3 = 61$ है।
ये $61$ कोडोन प्रोटीन संश्लेषण में उपयोग किए जाने वाले $20$ मानक अमीनो एसिड के लिए जिम्मेदार हैं।
0 likes
View Solution239
EasyMCQ
एक कोशिका में कितने प्रकार के एंटीकोडोन उपस्थित होते हैं?
A
$4$
B
$61$
C
$3$
D
$64$
Solution
(B) आनुवंशिक कूट (genetic code) में कुल $64$ कोडोन होते हैं,जिनमें से $61$ कोडोन अमीनो एसिड के लिए कूटलेखन करते हैं। शेष $3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (नॉनसेंस कोडोन) होते हैं और ये किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करते हैं। चूंकि स्टॉप कोडोन के लिए कोई संबंधित tRNA एंटीकोडोन नहीं होते हैं,इसलिए कोशिका में $61$ सेंस कोडोन को पहचानने के लिए केवल $61$ प्रकार के एंटीकोडोन उपस्थित होते हैं।
0 likes
View Solution240
EasyMCQ
$(i)$ कोडोन mRNA में निरंतर (contiguous) तरीके से पढ़ा जाता है। इसमें कोई विराम चिह्न नहीं होते हैं।
(ii) कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं।
(iii) $UUU$ फेनिलएलनिन (phenylalanine) के लिए कोड करता है।
(iv) $GAA$ एक स्टॉप टर्मिनेटर कोडोन है।
उपरोक्त कथनों (i-iv) की तुलना करते हुए,आनुवंशिक कोड की मुख्य विशेषताओं के संबंध में $T$ (सत्य) और $F$ (असत्य) के साथ चिह्नित सही विकल्प का चयन करें।
(ii) कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं।
(iii) $UUU$ फेनिलएलनिन (phenylalanine) के लिए कोड करता है।
(iv) $GAA$ एक स्टॉप टर्मिनेटर कोडोन है।
उपरोक्त कथनों (i-iv) की तुलना करते हुए,आनुवंशिक कोड की मुख्य विशेषताओं के संबंध में $T$ (सत्य) और $F$ (असत्य) के साथ चिह्नित सही विकल्प का चयन करें।
A
$FTTF$
B
$FFTF$
C
$TTFF$
D
$FTFT$
Solution
(C) $(i)$ आनुवंशिक कोड mRNA में निरंतर तरीके से पढ़ा जाता है,जिसका अर्थ है कि कोडोन के बीच कोई विराम चिह्न नहीं होते हैं। यह कथन सत्य $(T)$ है।
(ii) आनुवंशिक कोड अपह्रसित (degenerate) होता है,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं। यह कथन सत्य $(T)$ है।
(iii) $UUU$ फेनिलएलनिन के लिए कोडोन है। यह कथन सत्य $(T)$ है।
(iv) $GAA$ ग्लूटामिक एसिड के लिए कोड करता है,न कि स्टॉप कोडोन के लिए। स्टॉप कोडोन $UAA$,$UAG$ और $UGA$ हैं। यह कथन असत्य $(F)$ है।
अतः,सही क्रम $T, T, T, F$ है।
(ii) आनुवंशिक कोड अपह्रसित (degenerate) होता है,जिसका अर्थ है कि कुछ अमीनो एसिड एक से अधिक कोडोन द्वारा कोडित होते हैं। यह कथन सत्य $(T)$ है।
(iii) $UUU$ फेनिलएलनिन के लिए कोडोन है। यह कथन सत्य $(T)$ है।
(iv) $GAA$ ग्लूटामिक एसिड के लिए कोड करता है,न कि स्टॉप कोडोन के लिए। स्टॉप कोडोन $UAA$,$UAG$ और $UGA$ हैं। यह कथन असत्य $(F)$ है।
अतः,सही क्रम $T, T, T, F$ है।
0 likes
View Solution241
EasyMCQ
प्रारंभिक कोडोन (initiator codon) कौन सा है?
A
$AUG$
B
$UUU$
C
$CAC$
D
$CAA$
Solution
(A) प्रारंभिक कोडोन $AUG$ है। यह सुकेंद्रकी (eukaryotes) जीवों में मेथिओनिन $(Met)$ अमीनो एसिड के लिए और असीमकेंद्रकी (prokaryotes) जीवों में $N$-फॉर्मिलमेथिओनिन $(fMet)$ के लिए कोड करता है। यह स्थानांतरण (translation) की प्रक्रिया के दौरान प्रोटीन संश्लेषण की शुरुआत का संकेत देता है।
0 likes
View Solution242
EasyMCQ
आनुवंशिक कूट (Genetic code) के लिए,दिए गए कथनों के लिए सही विकल्प चुनें। जहाँ $T$ का अर्थ सत्य (True) और $F$ का अर्थ असत्य (False) है।
$(1)$ फेनिलएलनिन $(Phe)$ अमीनो एसिड तीन से अधिक कोडोन द्वारा कोडित होता है।
$(2)$ कोडोन $t-RNA$ में निरंतर (contiguous) तरीके से पढ़ा जाता है।
$(3)$ $UUC$ फेनिलएलनिन के लिए कोड करेगा।
$(4)$ $AUG$ मेथियोनीन के लिए कोड करता है।
$(1)$ फेनिलएलनिन $(Phe)$ अमीनो एसिड तीन से अधिक कोडोन द्वारा कोडित होता है।
$(2)$ कोडोन $t-RNA$ में निरंतर (contiguous) तरीके से पढ़ा जाता है।
$(3)$ $UUC$ फेनिलएलनिन के लिए कोड करेगा।
$(4)$ $AUG$ मेथियोनीन के लिए कोड करता है।
A
$FFTT$
B
$TTFT$
C
$FTTF$
D
$FTFT$
Solution
(A) कथन $(1)$ असत्य है: फेनिलएलनिन दो कोडोन ($UUU$ और $UUC$) द्वारा कोडित होता है,तीन से अधिक द्वारा नहीं।
कथन $(2)$ असत्य है: कोडोन $mRNA$ में निरंतर तरीके से पढ़ा जाता है,$t-RNA$ में नहीं।
कथन $(3)$ सत्य है: $UUC$ फेनिलएलनिन के लिए दो कोडोन में से एक है।
कथन $(4)$ सत्य है: $AUG$ प्रारंभिक कोडोन है और यह मेथियोनीन के लिए कोड करता है।
अतः,अनुक्रम $F, F, T, T$ है। सही विकल्प $A$ है।
कथन $(2)$ असत्य है: कोडोन $mRNA$ में निरंतर तरीके से पढ़ा जाता है,$t-RNA$ में नहीं।
कथन $(3)$ सत्य है: $UUC$ फेनिलएलनिन के लिए दो कोडोन में से एक है।
कथन $(4)$ सत्य है: $AUG$ प्रारंभिक कोडोन है और यह मेथियोनीन के लिए कोड करता है।
अतः,अनुक्रम $F, F, T, T$ है। सही विकल्प $A$ है।
0 likes
View Solution243
EasyMCQ
$AUG$ द्वारा क्या इंगित किया जाता है?
A
प्रारंभिक कोडोन (Initiator Codon)
B
अपहसित कोडोन (Degenerate Codon)
C
निरर्थक कोडोन (Nonsense Codon)
D
समापन कोडोन (Stop Codon)
Solution
(A) $AUG$ एक दोहरे कार्य वाला कोडोन है।
$1$. यह मेथियोनीन $(Met)$ अमीनो एसिड के लिए कोड करता है।
$2$. यह एक प्रारंभिक कोडोन के रूप में कार्य करता है,जो $mRNA$ स्ट्रैंड पर प्रोटीन संश्लेषण (अनुवाद) की शुरुआत का संकेत देता है।
अतः,सही विकल्प $A$ है।
$1$. यह मेथियोनीन $(Met)$ अमीनो एसिड के लिए कोड करता है।
$2$. यह एक प्रारंभिक कोडोन के रूप में कार्य करता है,जो $mRNA$ स्ट्रैंड पर प्रोटीन संश्लेषण (अनुवाद) की शुरुआत का संकेत देता है।
अतः,सही विकल्प $A$ है।
0 likes
View Solution244
EasyMCQ
निम्नलिखित में से कौन सा विकल्प आनुवंशिक कोड में स्टॉप कोडोन (समापन संकेत) को दर्शाता है?
A
$UAA$,$UAG$,$UGA$
B
$UGG$,$UGC$,$UCG$
C
$AAU$,$AUG$,$AAG$
D
$UGU$,$UGG$,$UGA$
Solution
(A) आनुवंशिक कोड में कुल $64$ कोडोन होते हैं,जिनमें से $3$ कोडोन किसी भी अमीनो एसिड के लिए कोड नहीं करते हैं। इन्हें स्टॉप कोडोन या समापन संकेत के रूप में जाना जाता है क्योंकि ये प्रोटीन संश्लेषण प्रक्रिया के अंत का संकेत देते हैं। ये तीन कोडोन $UAA$,$UAG$ और $UGA$ हैं।
0 likes
View Solution245
EasyMCQ
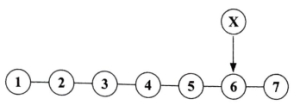
सिकल-सेल $HbS$ पेप्टाइड श्रृंखला के दिए गए आरेख में '$X$' के लिए सही तीन-अक्षर वाला कोडोन चुनें।
A
$GAU$
B
$GAG$
C
$GUG$
D
$GAA$
Solution
(C) सिकल-सेल एनीमिया में,हीमोग्लोबिन के $\beta$-ग्लोबिन जीन में एक बिंदु उत्परिवर्तन (point mutation) होता है।
विशेष रूप से,$\beta$-ग्लोबिन mRNA का $6^{th}$ कोडोन $GAG$ (जो ग्लूटामिक एसिड के लिए कोड करता है) से बदलकर $GUG$ (जो वैलीन के लिए कोड करता है) हो जाता है।
$\beta$-ग्लोबिन श्रृंखला के $6^{th}$ स्थान पर ग्लूटामिक एसिड के स्थान पर वैलीन का यह प्रतिस्थापन सिकल-सेल हीमोग्लोबिन $(HbS)$ के निर्माण का कारण बनता है।
इसलिए,स्थान '$X$' ($6^{th}$ स्थान) पर सही कोडोन $GUG$ है।
विशेष रूप से,$\beta$-ग्लोबिन mRNA का $6^{th}$ कोडोन $GAG$ (जो ग्लूटामिक एसिड के लिए कोड करता है) से बदलकर $GUG$ (जो वैलीन के लिए कोड करता है) हो जाता है।
$\beta$-ग्लोबिन श्रृंखला के $6^{th}$ स्थान पर ग्लूटामिक एसिड के स्थान पर वैलीन का यह प्रतिस्थापन सिकल-सेल हीमोग्लोबिन $(HbS)$ के निर्माण का कारण बनता है।
इसलिए,स्थान '$X$' ($6^{th}$ स्थान) पर सही कोडोन $GUG$ है।
0 likes
View Solution246
EasyMCQ
बीस अमीनो एसिड के कूटलेखन (coding) में प्रभावी कोडोन की संख्या कितनी है?
A
$64$
B
$61$
C
$20$
D
$32$
Solution
(B) आनुवंशिक कूट (genetic code) में कुल $64$ संभावित कोडोन होते हैं।
इन $64$ कोडोन में से,$3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (समाप्ति कोडोन) होते हैं जो किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करते हैं।
इसलिए,$20$ अमीनो एसिड के लिए कूटलेखन करने वाले प्रभावी कोडोन की संख्या $64 - 3 = 61$ है।
इन $64$ कोडोन में से,$3$ कोडोन $(UAA, UAG, UGA)$ स्टॉप कोडोन (समाप्ति कोडोन) होते हैं जो किसी भी अमीनो एसिड के लिए कूटलेखन नहीं करते हैं।
इसलिए,$20$ अमीनो एसिड के लिए कूटलेखन करने वाले प्रभावी कोडोन की संख्या $64 - 3 = 61$ है।
0 likes
View Solution247
EasyMCQ
एक परिपक्व $mRNA$ में बीच में बिना किसी स्टॉप कोडोन के $900$ बेस होते हैं। अनुवाद (translation) के दौरान इस $mRNA$ द्वारा कोडित अमीनो एसिड की संख्या की गणना करें।
A
$900$
B
$299$
C
$300$
D
$450$
Solution
(C) आनुवंशिक कोड एक ट्रिपलेट कोड है,जिसका अर्थ है कि $3$ न्यूक्लियोटाइड (बेस) $1$ अमीनो एसिड के लिए कोड करते हैं।
यह दिया गया है कि $mRNA$ में $900$ बेस हैं और कोई स्टॉप कोडोन मौजूद नहीं है,इसलिए कोडोन की कुल संख्या बेस की कुल संख्या को $3$ से विभाजित करके प्राप्त की जाती है।
कोडोन की संख्या = $\frac{900}{3} = 300$.
चूंकि प्रत्येक कोडोन एक अमीनो एसिड के लिए कोड करता है,इसलिए कोडित अमीनो एसिड की संख्या $300$ होगी।
यह दिया गया है कि $mRNA$ में $900$ बेस हैं और कोई स्टॉप कोडोन मौजूद नहीं है,इसलिए कोडोन की कुल संख्या बेस की कुल संख्या को $3$ से विभाजित करके प्राप्त की जाती है।
कोडोन की संख्या = $\frac{900}{3} = 300$.
चूंकि प्रत्येक कोडोन एक अमीनो एसिड के लिए कोड करता है,इसलिए कोडित अमीनो एसिड की संख्या $300$ होगी।
0 likes
View Solution248
EasyMCQ
निम्नलिखित में से कौन सा अमीनो एसिड केवल एक कोडोन द्वारा कोडित होता है?
A
वेलिन
B
फेनिलएलनिन
C
टायरोसिन
D
ट्रिप्टोफैन
Solution
(D) ट्रिप्टोफैन.
आनुवंशिक कोड में,अधिकांश अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं (डिजनरेसी).
हालाँकि,ट्रिप्टोफैन $(Trp)$ और मेथियोनीन $(Met)$ अद्वितीय हैं क्योंकि वे प्रत्येक केवल एक ही कोडोन द्वारा कोडित होते हैं.
ट्रिप्टोफैन विशेष रूप से $UGG$ कोडोन द्वारा कोडित होता है.
आनुवंशिक कोड में,अधिकांश अमीनो एसिड एक से अधिक कोडोन द्वारा निर्दिष्ट होते हैं (डिजनरेसी).
हालाँकि,ट्रिप्टोफैन $(Trp)$ और मेथियोनीन $(Met)$ अद्वितीय हैं क्योंकि वे प्रत्येक केवल एक ही कोडोन द्वारा कोडित होते हैं.
ट्रिप्टोफैन विशेष रूप से $UGG$ कोडोन द्वारा कोडित होता है.
0 likes
View Solution249
EasyMCQ
$mRNA$ पर कोडोन $CAU-CCU-AAA-CUG$ हैं। अमीनो एसिड के सही अनुक्रम की पहचान करें।
A
His-Pro-Lys-Leu
B
Pro-His-Lys-Leu
C
His-Pro-Leu-Lys
D
Pro-Leu-Lys-His
Solution
(A) सही अनुक्रम $A$ है।
$CAU$ हिस्टिडाइन $(His)$ के लिए कोड करता है।
$CCU$ प्रोलाइन $(Pro)$ के लिए कोड करता है।
$AAA$ लाइसिन $(Lys)$ के लिए कोड करता है।
$CUG$ ल्यूसीन $(Leu)$ के लिए कोड करता है।
अतः,अमीनो एसिड का अनुक्रम $His-Pro-Lys-Leu$ है।
$CAU$ हिस्टिडाइन $(His)$ के लिए कोड करता है।
$CCU$ प्रोलाइन $(Pro)$ के लिए कोड करता है।
$AAA$ लाइसिन $(Lys)$ के लिए कोड करता है।
$CUG$ ल्यूसीन $(Leu)$ के लिए कोड करता है।
अतः,अमीनो एसिड का अनुक्रम $His-Pro-Lys-Leu$ है।
0 likes
View Solution250
MediumMCQ
एमिनो एसिड 'Met-Leu-Val-Arg' के अनुक्रम के लिए कोडिंग करने वाले $mRNA$ का न्यूक्लियोटाइड अनुक्रम ज्ञात कीजिए और नीचे दिए गए विकल्पों में से सही विकल्प चुनिए:
A
$AUG-GAU-GAA-UAU-UGU$
B
$AUG-GAU-GAA-CGU-GCC$
C
$AUG-CUA-GUG-UAU-UGU$
D
$AUG-CUA-GUG-CGU-GCC$
Solution
(D) जेनेटिक कोड (आनुवंशिक कूट) अपहसित और सार्वभौमिक होते हैं। दिए गए एमिनो एसिड के लिए कोडोन इस प्रकार हैं:
$1$. मेथियोनीन $(Met)$: $AUG$
$2$. ल्यूसीन $(Leu)$: $CUA$
$3$. वैलीन $(Val)$: $GUG$
$4$. आर्जिनीन $(Arg)$: $CGU$
इन कोडोन को जोड़ने पर,$mRNA$ अनुक्रम $AUG-CUA-GUG-CGU$ प्राप्त होता है। विकल्प $D$ में $AUG-CUA-GUG-CGU-GCC$ अनुक्रम दिया गया है,जिसमें अंतिम $GCC$ एक अतिरिक्त कोडोन है,लेकिन अन्य विकल्पों की तुलना में यह विकल्प आवश्यक अनुक्रम के साथ पूरी तरह मेल खाता है। अतः,सही विकल्प $D$ है।
$1$. मेथियोनीन $(Met)$: $AUG$
$2$. ल्यूसीन $(Leu)$: $CUA$
$3$. वैलीन $(Val)$: $GUG$
$4$. आर्जिनीन $(Arg)$: $CGU$
इन कोडोन को जोड़ने पर,$mRNA$ अनुक्रम $AUG-CUA-GUG-CGU$ प्राप्त होता है। विकल्प $D$ में $AUG-CUA-GUG-CGU-GCC$ अनुक्रम दिया गया है,जिसमें अंतिम $GCC$ एक अतिरिक्त कोडोन है,लेकिन अन्य विकल्पों की तुलना में यह विकल्प आवश्यक अनुक्रम के साथ पूरी तरह मेल खाता है। अतः,सही विकल्प $D$ है।
0 likes
View SolutionMolecular Basis of Inheritance — Genetic code · Frequently Asked Questions
1Are these Molecular Basis of Inheritance questions useful for JEE and NEET?
Yes. All questions in this section are mapped to JEE Main and NEET exam patterns. Previous year questions from JEE Main, NEET, GUJCET and state-level exams are included with full solutions.
2Can I switch to Hindi or Gujarati for these questions?
Yes. Use the language tabs in the hero section or the sidebar to view the same questions and solutions in English, Hindi or Gujarati.
3How do I generate a question paper from this subtopic?
Use the Vedclass Exam Paper Generator — select the chapter and subtopic, set difficulty, and generate Sets A, B, C, D automatically. First 3 chapters of every subject are free.
Vedclass Products
For Students
Vedclass Test Series
Mock tests in real JEE/NEET style with performance analysis. 5-day free trial.
Start Free TrialFor Teachers
Exam Paper Generator
Generate Set A/B/C/D papers from this chapter in 2 minutes. 3 chapters free.
Try FreeFor Institutes
Online Exam Module
Live online exams with unlimited students, 360° analytics & white-label branding.
See DemoFor Teachers & Institutes
Generate a Molecular Basis of Inheritance Exam Paper in 2 Minutes
Select subtopic & difficulty — Sets A, B, C, D auto-generated with No Repeat logic.
First 3 chapters of every subject are free — no payment required.